基于小波特征和支持向量机的信号分类金宝app
此示例显示如何使用基于小波的特征提取和支持向量机(SVM)分类器来分类人体心电图(ECG)信号。金宝app通过将原始ECG信号转换为在聚集体中用于区分不同类的更小的特征来简化信号分类的问题。您必须具有小波Toolbox™,信号处理工具箱™和统计和机器学习工具箱™来运行此示例。本例中使用的数据是公开的物理体.
数据描述
该示例使用从三组或课程中获得的心电图数据:心脏心律失常的人,具有充血性心力衰竭的人,以及具有正常窦性心律的人。该示例使用来自三个PhysioIoneT数据库的162个ECG录制:MIT-BIH心律失常数据库[3] [7],MIT-BIH正常窦性节律数据库[3],和BIDMC充血性心力衰竭数据库[1] [3]。总共有96名患有心律失常的人的录音,来自患有充血性心力衰竭的人的30个录音,36人从正常的窦性心律的人录音。目标是培训分类器以区分心律失常(ARR),充血性心力衰竭(CHF)和正常窦性心律(NSR)。
下载数据
控件中下载数据是第一步GitHub库.要下载数据,请单击代码并选择下载zip..保存文件physionet_ecg_data-master.zip在您有写权限的文件夹中。本例的说明假设您已经将该文件下载到临时目录(Tempdir.在MATLAB中)。如果选择在不同的文件夹中下载数据,请修改后续解压缩和加载数据的说明Tempdir..
该文件physionet_ecg_data-master.zip包含
EcgData.zip.
README.md
和ecgdata.zip包含
ECGData.mat
Modified_physionet_data.txt
License.txt。
ECGData.matholds the data used in this example. The .txt file, Modified_physionet_data.txt, is required by PhysioNet's copying policy and provides the source attributions for the data as well as a description of the pre-processing steps applied to each ECG recording.
加载文件
如果您遵循上一节中的下载说明,请输入以下命令以解压缩两个存档文件。
解压缩(fullfile (tempdir,'physionet_ecg_data-master.zip'), tempdir)解压缩(fullfile (tempdir,“physionet_ECG_data-master”那'ecgdata.zip'),...fullfile (tempdir“ECGData”)))
解压缩ecgdata.zip文件后,将数据加载到MATLAB中。
load(fullfile(tempdir,“ECGData”那'ecgdata.mat')))
EcgData.是一个具有两个字段的结构阵列:数据和标签.数据是一个162×65536矩阵,其中每行是在128赫兹采样的心电图录制。标签是一个162×1个单元格阵列诊断标签,每排一个数据.三种诊断类别是:“ARR”(心律失常)、“CHF”(充血性心力衰竭)和“NSR”(正常窦性心律)。
创建培训和测试数据
随机将数据分成两组 - 培训和测试数据集。辅助功能Helperrandomsplit.执行随机分割。Helperrandomsplit.接受培训数据的所需分割百分比EcgData..这Helperrandomsplit.功能输出两个数据集以及每个数据集。每一排训练DATA.和测试数据是一个心电图信号。每个元素Trainlabels.和testlabels.包含数据矩阵的相应行的类标签。在此示例中,我们随机将每个类中的70%分配给训练集。剩下的30%被列出用于测试(预测),并分配给测试集。
百分之= 70;[TrainData,TestData,TrainLabels,TestLabels] =...Helperrandomsplit(百分号,EcgData);
有113条记录训练DATA.输入49条记录测试数据.通过设计,培训数据包含69.75%(113/162)的数据。回想一下,ARR类代表数据的59.26%(96/162),CHF类代表18.52%(30/162),NSR类代表22.22%(36/162)。检查培训和测试集中每个类的百分比。每个百分比与数据集中的整个类百分比一致。
Ctrain = countcats(分类(trainLabels)。/元素个数(trainLabels)。*100 . Ctest = countcats(categorical(testLabels))./numel(testLabels).*100 . Ctest = countcats(categorical(testLabels))./numel(testLabels).*100 . Ctest = countcats(categorical(testLabels)
CTRAIN = 59.2920 18.5841 22.1239 CTEST = 59.1837 18.3673 22.4490
绘制样本
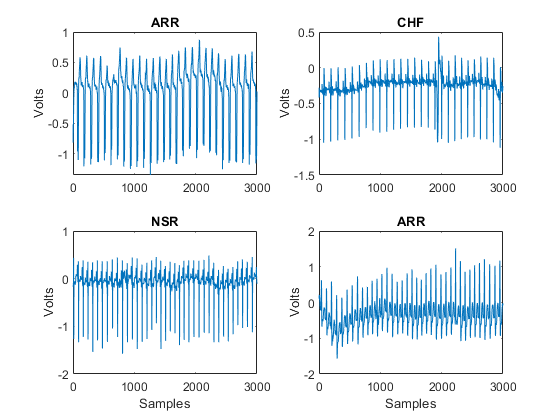
绘制来自四个随机选择的记录的前几千样本EcgData..辅助功能HelperplotrandomRecords.这是否。HelperplotrandomRecords.接受EcgData.一个随机的种子作为输入。初始种子设置为14,以便绘制每个类的至少一条记录。你可以执行HelperplotrandomRecords.和EcgData.作为唯一的输入参数,如您希望获得与每个类关联的各种ECG波形的感觉。您可以在此示例结束时找到此辅助功能的源代码。金宝app
helperPlotRandomRecords (ECGData 14)
特征提取
提取每个信号的信号分类中使用的特征。此示例使用以下功能在每个信号的8个块中提取的以下功能大约一分钟(8192个样本):
自回归模型(AR)订单4 [8]的系数。
Shannon熵(SE)最大重叠离散小波包变换(ModPWT)的值在4级[5]。
缩放指数的第二次累积量的多重术小波领导估计和持有者指数的范围,或奇异性谱[4]。
另外,在整个数据长度[6]上为每个信号提取多尺度小波差异估计。使用对小波差异的无偏见估计。这要求在方差估计中仅使用具有不受边界条件不受影响的小波系数的级别。信号长度为2 ^ 16(65,536),并且'db2'小波这会导致14个级别。
根据已发布的研究选择这些功能,证明了它们在分类ECG波形方面的有效性。这并非旨在是穷举或优化的功能列表。
利用Burg方法估计各窗的AR系数,阿尔堡.在[8]中,作者使用了模型顺序选择方法来确定AR(4)模型在类似的分类问题中提供了ECG波形的最佳选择。在[5]中,在小波包树的终端节点上计算了信息理论措施,Shannon熵,并与随机林分类器一起使用。在这里,我们使用不确定的小波包变换,modwpt,低至4级。
[5]之后的非抽取小波包变换的Shannon熵的定义为: 在哪里
在哪里 是第j节节点中的相应系数的数量
是第j节节点中的相应系数的数量 是第j个终端节点中的小波分组系数的归一化平方。
是第j个终端节点中的小波分组系数的归一化平方。
通过小波方法估计的两个分形测量用作特征。遵循[4],我们使用从中获得的奇点谱的宽度dwtleader.作为ECG信号的多分泌性质的衡量标准。我们还使用缩放指数的第二次累积量。缩放指数是基于比例的指导指数,其描述了不同分辨率信号中信号中的幂律行为。金宝搏官方网站第二次累积物广泛地代表了缩放指数从线性的偏离。
使用整个信号的小波差异modwtvar..小波差异通过尺度测量信号的可变性,或者在八度带频率间隔的信号中等效地变化。
总共有190个特点:32 AR功能(每块4系数),128个香农熵值(每块16个值),16个分形估计(每块2个),和14个小波方差估计值。
这helperExtractFeatures功能计算这些功能并将它们连接到每个信号的特征向量中。您可以在此示例结束时找到此辅助功能的源代码。金宝app
TimeWindow = 8192;Arorder = 4;modwptlevel = 4;[训练培训,Testfeatures,Feathindices] =...ververextractfeatures(TrainData,Testdata,TimeWindow,Arorder,Modwptlevel);
训练费和testFeatures分别是113 × 190和49 × 190矩阵。这些矩阵的每一行都是对应心电数据的特征向量训练DATA.和测试数据, 分别。在创建特征向量时,数据从65536样本减少到190个元素向量。这是数据的显着减少,但目标不仅仅是数据的减少。目标是将数据减少到更小的特征集,该特征集捕获了类之间的差异,使得分类器可以准确地分离信号。构成的功能的指标训练费和testFeatures包含在结构阵列中,featureindices.您可以使用这些索引来探索组的功能。例如,检查第一次窗口的奇点光谱中的持有者指数范围。绘制整个数据集的数据。
allFeatures = [trainFeatures; testFeatures];allLabels = [trainLabels; testLabels];图箱线图(allFeatures (:, featureindices.HRfeatures (1)), allLabels,'缺口'那'上') ylabel (“霍尔德指数范围”)标题('按组的奇点谱的范围(第一次窗口)') 网格在
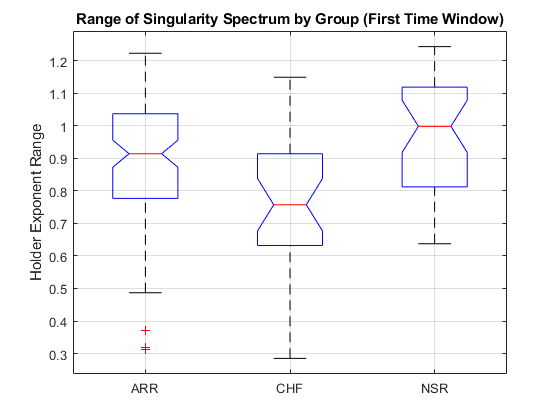
您可以对此功能进行单向分析,并确认Boxplot中出现的内容,即Arr和NSR组的范围比CHF组明显更大。
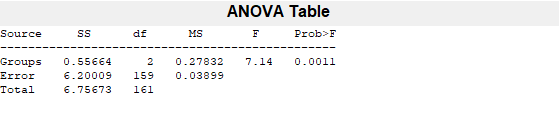
[p anovatab st] = anova1 (allFeatures (:, featureindices.HRfeatures (1)),...alllabels);C = Multcompare(ST,“显示”那“关闭”)
C = 1.0000 2.0000 0.0176 0.1144 0.2112 0.0155 1.0000 3.0000 -0.1591-0.0687 0.0218 0.01764 2.0000 3.0000 -0.2975 -0.1831 -0.0687 0.0005

作为另一个例子,考虑三组的次最低频率(第二大尺度)小波子带的方差差异。
箱线图(allFeatures (:, featureindices.WVARfeatures (end-1)), allLabels,'缺口'那'上') ylabel (小波变化的)标题('按组的小波差异'') 网格在

如果你对这个特征进行方差分析,你会发现NSR组在这个小波子带的方差显著低于ARR和CHF组。这些示例只是为了说明单个特性如何用于分离类。虽然单独一个特性是不够的,但我们的目标是获得足够丰富的特性集,使分类器能够分离所有三个类。
信号分类
现在数据已经被简化为每个信号的特征向量,下一步是使用这些特征向量对心电信号进行分类。您可以使用Classification Learner应用程序来快速评估大量的分类器。在这个例子中,使用了一个二次核的多类支持向量机。进行了两项分析。首先,我们使用整个数据集(训练和测试集),并使用5倍交叉验证估计误分类率和混淆矩阵。
特点= [训练饲料;testfeatures];RNG(1)模板= TemplatesVM(...“KernelFunction”那'多项式'那...“PolynomialOrder”2,...'kernelscale'那'汽车'那...“BoxConstraint”,1,...“标准化”,真正的);模型= fitcecoc (...特征,...[Trainlabels; Testlabels],...'学习者',模板,...'编码'那“onevsone”那...'classnames',{'arr'那瑞士法郎的那'nsr'});kfoldmodel = crossval(模型,'kfold'5);ClassLabels = KfoldPredict(Kfoldmodel);损失= kfoldloss(kfoldmodel)* 100 [confmatcv,grouporder] =困惑硕士([Trainlabels; Testlabels],ClassLabels);
损失= 8.0247
5倍分类误差为8.02%(91.98%正确)。混乱矩阵,Confmatcv.,显示哪些记录被错误分类。Grouporder.提供组的排序。ARR组中的两组被错误分类为CHF,八个CHF组被错误分类为ARR,作为NSR,来自NSR组的两个人被错误分类为ARR。
精确,召回和F1分数
在分类任务中,类的精度是校正正结果的数量除以积极结果的数量。换句话说,分类器分配给定标签的所有记录中,实际属于该类的比例。调用被定义为正确标签的数量除以给定类的标签数。具体而言,属于类的所有记录,我们的分类器标签为该类的比例。在判断您的机器学习系统的准确性时,您理想地想在精度和召回方面做得好。例如,假设我们有一个分类器,它将每一个记录标记为arr。然后我们召回ARR类将是1(100%)。属于ARR类的所有记录将被标记为ARR。但是,精度会很低。由于我们的分类器标记为ARR的所有记录,因此在这种情况下会有66个误报,以精确为96/162或0.5926。 The F1 score is the harmonic mean of precision and recall and therefore provides a single metric that summarizes the classifier performance in terms of both recall and precision. The following helper function computes the precision, recall, and F1 scores for the three classes. You can see howHelperPrecisionRecall.通过检查支持函数部分中的代码,根据混淆矩阵计算精度、召回率和F1分数。金宝app
CVTable = helperPrecisionRecall (confmatCV);
可以显示由。返回的表HelperPrecisionRecall.使用以下命令。
disp (CVTable)
精密召回F1_SCORE _________ ______ ________ ARR 90.385 97.917 94 CHF 91.304 70 79.245 NSR 97.143 94.444 95.775
ARR和NSR类的查全率和查全率都很好,而CHF类的查全率明显较低。
在接下来的分析中,我们只对训练数据(70%)拟合一个多类二次支持向量机,然后使用该模型对等待测试的30%的数据进行预测。测试集中有49条数据记录。
模型= fitcecoc (...训练疗法,...Trainlabels,...'学习者',模板,...'编码'那“onevsone”那...'classnames',{'arr'那瑞士法郎的那'nsr'});predLabels =预测(模型、testFeatures);
使用下面的方法来确定正确的预测次数并得到混淆矩阵。
classpredictions = strcmp(predlabels,testlabels);testAccuracy = sum(trackpricictions)/ length(testlabels)* 100 [confmattest,grouporder] = confusionmat(testlabels,predlabels);
testAccuracy = 97.9592
测试数据集的分类精度约为98%,混淆矩阵显示一个CHF记录被错误分类为NSR。
类似于在交叉验证分析中完成的内容,获取精度,召回和测试集的F1分数。
testtable = HelperPrecisionRecall(Confmattest);DISP(睾丸)
精密召回F1_SCORE _________ ______ ________ ARR 100 100 100 100 CHF 100 88.889 94.118 NSR 91.667 100 95.652
对原始数据和聚类的分类
从之前的分析出现了两个自然问题。是必要的特征提取,以实现良好的分类结果吗?是一个必要的分类器,或者这些功能是否可以在没有分类器的情况下分开组?要解决第一个问题,请重复原始时间序列数据的交叉验证结果。请注意,以下是计算昂贵的步骤,因为我们将SVM应用于162×65536矩阵。如果您不希望自己运行此步骤,结果将在下一段中描述。
Rawdata = [traindata; testdata];标签= [trainlabels; testlabels];RNG(1)模板= TemplatesVM(...“KernelFunction”那'多项式'那...“PolynomialOrder”2,...'kernelscale'那'汽车'那...“BoxConstraint”,1,...“标准化”,真正的);模型= fitcecoc (...rawData,...[Trainlabels; Testlabels],...'学习者',模板,...'编码'那“onevsone”那...'classnames',{'arr'那瑞士法郎的那'nsr'});kfoldmodel = crossval(模型,'kfold'5);ClassLabels = KfoldPredict(Kfoldmodel);损失= kfoldloss(kfoldmodel)* 100 [confmatcvraw,grouporder] =困惑硕士([Trainlabels; Testlabels],ClassLabels);Rawtable = HelperPrecisionRecall(Confmatcvraw);DISP(Rawtable)
损失= 33.3333精确召回F1_SCORE _________ ______ ________ ARR 64 100 78.049 CHF 100 13.333 23.529 NSR 100 22.222 36.364
原始时间序列数据的误分类率为33.3%。重复精度、召回率和F1分数分析显示,CHF组(23.52)和NSR组(36.36)的F1分数都很低。得到每个信号的幅值离散傅里叶变换(DFT)系数,进行频域分析。由于数据是实值的,我们可以利用傅里叶大小是偶函数这一事实,利用DFT实现一些数据约简。
Rawdatadft = ABS(FFT(Rawdata,[],2));Rawdatadft = Rawdatadft(:,1:2 ^ 16/2 + 1);RNG(1)模板= TemplatesVM(...“KernelFunction”那'多项式'那...“PolynomialOrder”2,...'kernelscale'那'汽车'那...“BoxConstraint”,1,...“标准化”,真正的);模型= fitcecoc (...Rawdatadft,...[Trainlabels; Testlabels],...'学习者',模板,...'编码'那“onevsone”那...'classnames',{'arr'那瑞士法郎的那'nsr'});kfoldmodel = crossval(模型,'kfold'5);ClassLabels = KfoldPredict(Kfoldmodel);损失= kfoldloss(kfoldmodel)* 100 [confmatcvdft,grouporder] =困惑硕士([Trainlabels; Testlabels],ClassLabels);dfttable = helperprecisionrecall(confmatcvdft);DISP(DFTTABLE)
损失= 19.1358精确召回F1_SCORE _________ ______ ________ ARR 76.423 97.917 85.845 CHF 100 26.667 42.105 NSR 93.548 80.556 86.567
使用DFT幅度将错误分类率降低至19.13%,但仍然超过我们的190个功能获得的错误率的两倍。这些分析表明,分类器已从仔细选择特征中受益。
要回答有关分类器的角色的问题,请尝试仅使用特征向量进行数据。使用K-means群集以及间隙统计数据来确定群集和群集分配的最佳数量。允许对数据的1至6个集群的可能性。
rng默认的Eva = Evallusters(功能,“kmeans”那'差距'那'klist',[1:6]);eva.
EVA = GapEvaluation具有属性:NumObservations:162检验:[1 2 3 4 5 6]标准值:[1.2777 1.3539 1.3644 1.3570 1.3591 1.3752] Optimwalk:3
间隙统计表明,最优聚类数为3。但是,如果您查看三个集群中的每个集群中的记录数量,您会发现基于特征向量的k-means聚类在分离三个诊断类别方面做得很差。
countcats(分类(eva.optimaly))
ans = 61 74 27
回想一下,有96人在ARR类,30人在CHF类,36人在NSR类。
概括
该实例利用信号处理从心电信号中提取小波特征,并利用小波特征将心电信号分为三类。特征提取不仅导致了大量的数据缩减,它还捕获了ARR、CHF和NSR类之间的差异,这从交叉验证结果和SVM分类器在测试集上的性能可以看出。该例子进一步证明,将支持向量机分类器应用于原始数据导致性能较差,因为没有使用分类器聚类特征向量。分类器和特征本身都不足以分离类。然而,当在使用分类器之前使用特征提取作为数据缩减步骤时,这三个类得到了很好的分离。
参考
Baim DS,Colucci Ws,Monrad Es,Smith Hs,Wright RF,Lanoue A,Gauthier DF,Ransil Bj,Grossman W,Braunwald E.用口服Milrinone治疗严重充血性心力衰竭患者的生存。J美国心脏病学院1986年3月;7(3):661-670。
Engin,M.,2004年。使用神经模糊网络进行ECG击败分类。模式识别字母,25(15),PP.1715-1722。
Goldberger AL, Amaral LAN, Glass L, Hausdorff JM, Ivanov PCh, Mark RG, miietus JE, Moody GB, Peng C-K, Stanley HE。PhysioBank, PhysioToolkit和PhysioNet:一个新的复杂生理信号研究资源的组成部分。循环.卷。101,23,33,2000年6月13日,PP。E215-E220。
http://circ.ahajournals.org/content/101/23/e215.full.Leonarduzzi, r。f。Schlotthauer, G。和Torres。工程师2010人。基于小波导子的心肌缺血心率变异性多重分形分析。医学与生物工程学会(EMBC), 2010年IEEE年度国际会议。
李,T.和周,2016年,2016年。使用小波包熵和随机森林的ECG分类。熵,18(8),p.285。
Maharaj,E.A.和阿隆索。2014年多元时间序列的判别分析:基于ECG信号的诊断应用。计算统计和数据分析,70,pp。67-87。
穆迪GB,Mark RG。MIT-BIH心律失常数据库的影响。IEEE Eng在Med和Biol 20(3):45-50(2001年5月)。(PMID:11446209)
赵,Q.和张,L.,2005。ECG功能采用小波变换和支持向量机的分类。金宝appIEEE关于神经网络和大脑的国际会议,2,PP。1089-1092。
金宝app支持功能
HelperplotrandomRecords.绘制随机选取的四个心电信号EcgData..
函数helperPlotRandomRecords (ECGData randomSeed)%这个函数只是为了支持xpwwavetmlexample。金宝app它可能%更改或在将来的释放中删除。如果输入参数个数= = 2 rng (randomSeed)结尾M =大小(ECGData.Data, 1);idxsel = randperm (M, 4);为了numplot = 1:4子图(2,2,numplot)绘图(EcgData.data(Idxsel(Numplot),1:3000))Ylabel('伏特')如果numplot> 2 xlabel('样品')结尾标题(EcgData.Labels {idxsel(numplot)})结尾结尾
helperExtractFeatures提取小波特征和AR系数,用于指定大小的数据块。该功能被连接到特征向量中。
函数[trainFeatures, testFeatures,featureindices] = helperExtractFeatures(trainData,testData,T,AR_order,level)%此函数仅支持XPWWaveletMlexample。金宝app它可能会改变或%将在以后的版本中删除。训练费= [];testfeatures = [];为了idx = 1:大小(traindata,1)x = traindata(idx,:);x = detrend(x,0);ARCOEFS = SLOOLAR(X,AR_ORDER,T);se = shannonentropy(x,t,级别);[cp,rh] =领导者(x,t);wvar = modwtvar(modwt(x,“db2”),“db2”);训练训练= [训练疗法;ARCOEFS SE CP RH WVAR'];%#OK结尾为了x1 = testData(idx,赋值);x1 =去趋势(x1, 0);arcoefs = blockAR (x1, AR_order, T);se = shannonEntropy (x1, T,水平);(cp, rh) =领导人(x1, T);wvar = modwtvar (modwt (x1,“db2”),“db2”);testFeatures = [testFeatures;arcoefs se cp rh wvar'];%#OK 结尾featureIndices = struct();%4 * 8feathindices.arfeatures = 1:32;startidx = 33;EndidX = 33+(16 * 8)-1;featureIndices.sefeatures = startidx:EndidX;startidx = Endidx + 1;EndIDX = startidx + 7;feathindices.cp2features = startidx:EndIDX;startidx = Endidx + 1;EndIDX = startidx + 7;feathindindes.hrfeatures = startidx:EndIDX; startidx = endidx+1; endidx = startidx+13; featureindices.WVARfeatures = startidx:endidx;结尾函数numwindow = nummel (x)/numbuffer;缓冲(x, y = numbuffer);se = 0(2 ^的级别,大小(y, 2));为了KK = 1:大小(y,2)wpt = modwpt(y(:,kk),级别);百分比横跨时间e = sum(wpt。^ 2,2);pij = wpt。^ 2. / e;%以下是EPS(1)se (: kk) =总和(j。*日志(j + eps), 2);结尾SE = REHAPE(SE,2 ^级* NUMWINDOWS,1);se = se';结尾函数ARCFS = SLOBLAR(x,订单,numbuffer)numwindows = numel(x)/ numbuffer;缓冲(x, y = numbuffer);ARCFS =零(顺序,大小(y,2));为了artmp = arburg(y(:, Kk),order);arcfs (:, kk) = artmp(2:结束);结尾ARCFS = REPAPE(ACCFS,ORDER * NUMWINDOWS,1);ArcFS = AccFS';结尾函数[cp,rh] = leaders(x,numbuffer) y = buffer(x,numbuffer);cp = 0(1、大小(y, 2));rh = 0(1、大小(y, 2));为了kk = 1:尺寸(y,2)[〜,h,cptmp] = dwtleader(y(:,kk));Cp(kk)= cptmp(2);RH(kk)=范围(h);结尾结尾
HelperPrecisionRecall.根据混淆矩阵返回精度、召回率和F1分数。输出结果为MATLAB表格。
函数prtable = helperprecisionrecall(confmat)%此函数仅支持XPWWaveletMlexample。金宝app它可能会改变或%将在以后的版本中删除。precisionARR = confmat(1,1) /笔(confmat (: 1)) * 100;precisionCHF = confmat(2,2)/sum(confmat(:,2))*100;precisionNSR = confmat(3,3)/sum(confmat(:,3))*100;recallARR = confmat(1,1) /笔(confmat (1:)) * 100;recallCHF = confmat(2, 2) /笔(confmat (2:)) * 100;recallNSR = confmat(3,3) /笔(confmat (3:)) * 100;F1ARR = 2 * precisionARR * recallARR / (precisionARR + recallARR);F1CHF = 2 * precisionCHF * recallCHF / (precisionCHF + recallCHF);F1NSR = 2 * precisionNSR * recallNSR / (precisionNSR + recallNSR);%构造一个MATLAB表来显示结果。prtable = Array2table([PrecisionArr Recallarr F1arr;...precisionCHF recallCHF F1CHF;precisionNSR recallNSR...F1nsr],'variablenames',{'精确'那“回忆”那'f1_score'},'rownames'那...{'arr'那瑞士法郎的那'nsr'});结尾
也可以看看
职能
应用
- 分类学习者应用(统计和机器学习工具箱)
你也可以从以下列表中选择一个网站: