小波散射与GPU加速-语音数字识别
这个例子展示了如何加速小波散射特性的计算使用gpuArray(并行计算工具箱)。你必须有并行计算工具箱™和GPU的支持。金宝app看到GPU的金宝app支持版本(并行计算工具箱)获取详细信息。这个示例使用7.0 V泰坦NVIDIA GPU的计算能力。示例计算散射变换的部分提供了选择使用GPU和CPU如果你想GPU与CPU性能进行比较。
这个例子中繁殖专门CPU版本的散射变换中发现语音数字识别与小波散射和深度学习。
数据
克隆或下载免费使用数字数据集(FSDD),可用https://github.com/Jakobovski/free-spoken-digit-dataset。FSDD是一个开放的数据集,这意味着它能随着时间的推移而增长。这个例子使用的版本在08/20/2020由3000录音的英语数字0到9获得6个扬声器。数据采样在8000赫兹。
使用audioDatastore管理数据访问录音,确保随机分为训练集和测试集。设置位置房地产的位置FSDD录音文件夹在您的计算机上。在本例中,数据存储在一个文件夹下tempdir。
位置= fullfile (tempdir,“free-spoken-digit-dataset”,“录音”);广告= audioDatastore(位置);
辅助功能,helpergenLabels定义在这个示例中,创建一个分类数组FSDD标签的文件。列表的类和例子的数量在每个类。
ads.Labels = helpergenLabels(广告);总结(ads.Labels)
0 300 300 300 300 300 4 300 5 6 300 7 300 300 300 9
FSDD数据集包括平衡类300录音。的录音FSDD不相等的时间。通读FSDD文件并构建一个信号长度的柱状图。
LenSig = 0(元素个数(ads.Files), 1);nr = 1;而hasdata(广告)数字=阅读(广告);LenSig (nr) =元素个数(数字);nr = nr + 1;结束重置(广告)直方图(LenSig)网格在包含(的信号长度(样本))ylabel (“频率”)
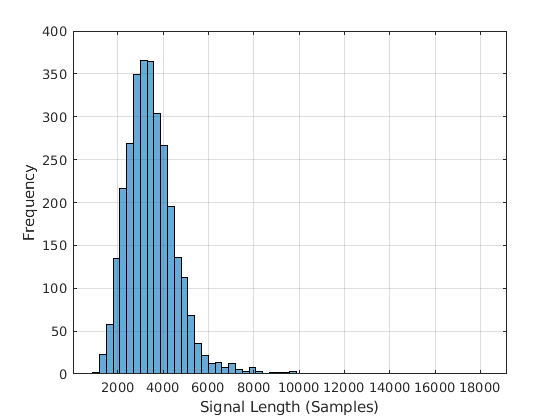
直方图显示,记录长度的分布是积极倾斜。分类,这个示例使用常见的8192个样本信号长度。价值8192,一个保守的选择,确保删除再录音不影响(切断)演讲内容。如果信号大于8192个样本,或1.024秒,在长度,记录是8192个样本截断。如果信号小于8192样本长度、信号对称前缀和附加零长度为8192个样本。
小波时间散射
创建一个小波时间散射网络使用一个不变的规模0.22秒。因为特征向量将由平均散射变换样本,设置OversamplingFactor2。设置值为2将导致散射系数的数量增加到了原来的4倍为每个路径对批判性downsampled价值。
sn = waveletScattering (“SignalLength”,8192,“InvarianceScale”,0.22,…“SamplingFrequency”,8000,“OversamplingFactor”2);
散射的设置在326年网络的结果路径。你可以用下面的代码验证这一点。
[~,npaths] =路径(sn);总和(npaths)
ans = 326
把FSDD分成训练集和测试集。分配80%的数据训练集和测试集保留20%。训练分类器的训练数据是基于散射变换。测试数据是评估模型的泛化能力看不见的数据。
rng默认的;广告= shuffle(广告);[adsTrain, adsTest] = splitEachLabel(广告,0.8);总结(adsTrain.Labels)
0 240 240 240 240 240 4 240 5 6 240 7 240 240 240 9
总结(adsTest.Labels)
60 60 60 60 60 0 1 2 3 4 5 6 60 60 60 60 60 7 8 9
形成一个8192 -,- 2400矩阵,其中每一列是一个spoken-digit录音。辅助函数helperReadSPData或垫数据进行截断长度8192和规范每个记录的最大值。helper函数将数据转换为单精度。
Xtrain = [];scatds_Train =变换(adsTrain @ (x) helperReadSPData (x));而hasdata (scatds_Train) smat =阅读(scatds_Train);Xtrain =猫(2 Xtrain smat);结束
重复这个过程了测试集。由此产生的矩阵是8192 - 600。
Xtest = [];scatds_Test =变换(adsTest @ (x) helperReadSPData (x));而hasdata (scatds_Test) smat =阅读(scatds_Test);Xtest =猫(2 Xtest smat);结束
散射变换应用到训练集和测试集。训练和测试数据集移动到GPUgpuArray。的使用gpuArray与NVIDIA GPU的人提供了一个巨大的加速度。这种散射网络、批量大小和GPU, GPU实现计算散射特性大约15倍CPU版本。如果您不希望使用GPU,集useGPU来假。你也可以替代的价值useGPUGPU与CPU性能进行比较。
useGPU =真正的;如果useGPU Xtrain = gpuArray (Xtrain);应变= sn.featureMatrix (Xtrain);Xtrain =收集(Xtrain);Xtest = gpuArray (Xtest);圣= sn.featureMatrix (Xtest);Xtest =收集(Xtest);其他的应变= sn.featureMatrix (Xtrain);圣= sn.featureMatrix (Xtest);结束

获得的散射特性训练集和测试集。
TrainFeatures =应变(2:,:,);TrainFeatures =挤压(平均(TrainFeatures, 2))的;TestFeatures =圣(2:,:,);TestFeatures =挤压(平均(TestFeatures, 2))的;
这个示例使用支持向量机(SVM)分类器与金宝app一个二次多项式的内核。支持向量机模型的散射特性。
模板= templateSVM (…“KernelFunction”,多项式的,…“PolynomialOrder”2,…“KernelScale”,“汽车”,…“BoxConstraint”,1…“标准化”,真正的);classificationSVM = fitcecoc (…TrainFeatures,…adsTrain.Labels,…“学习者”模板,…“编码”,“onevsone”,…“类名”分类({' 0 ';' 1 ';' 2 ';“3”;“4”;“5”;“6”;“7”;“8”;“9”}));
使用k倍交叉验证预测模型的泛化精度。将训练集分成五组交叉验证。
partitionedModel = crossval (classificationSVM,“KFold”5);[validationPredictions, validationScores] = kfoldPredict (partitionedModel);validationAccuracy = (1 - kfoldLoss (partitionedModel“LossFun”,“ClassifError”))* 100
validationAccuracy = 97.2500
估计泛化精度约为97%。现在使用支持向量机模型预测了测试集。
predLabels =预测(classificationSVM TestFeatures);testAccuracy = (predLabels = = adsTest.Labels) /元素个数之和(predLabels) * 100
testAccuracy = 97
准确性也伸出测试集上大约97%。
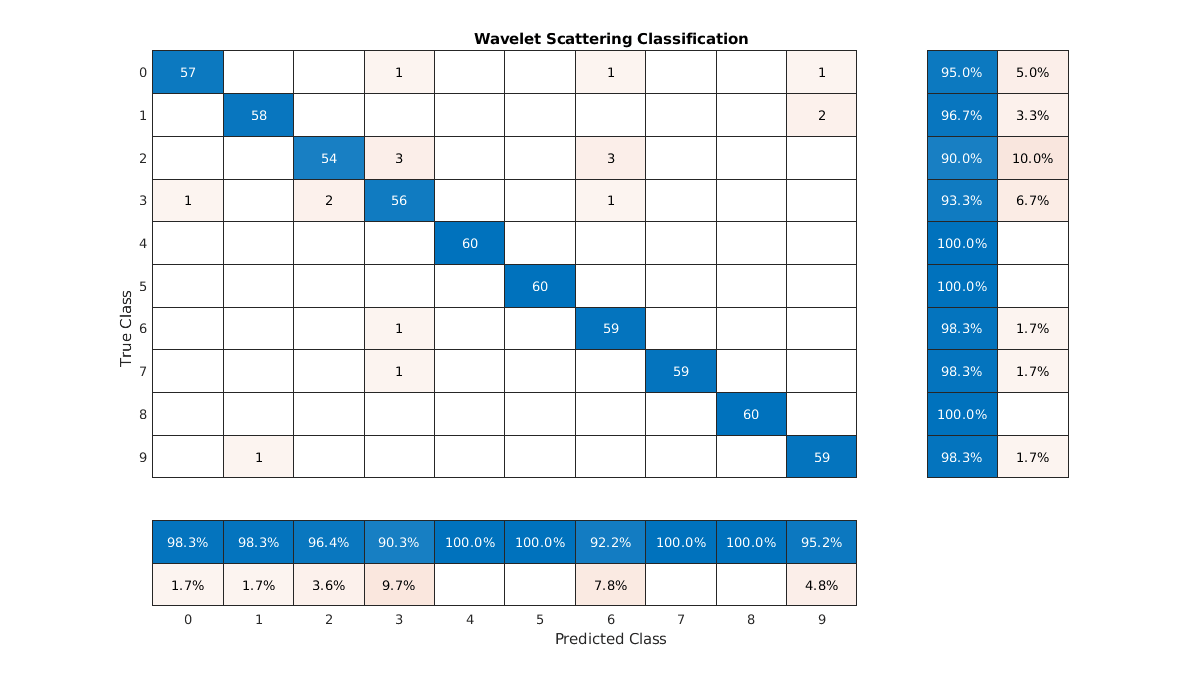
总结的性能模型在测试集上的混乱。显示每个类的精度和召回通过使用列和行摘要。表的底部的混乱图表显示了每个类的精度值。桌子右边的图表显示混乱召回值。
图(“单位”,“归一化”,“位置”(0.2 - 0.2 0.5 - 0.5));ccscat = confusionchart (adsTest.Labels predLabels);ccscat。Title =“小波散射分类”;ccscat。ColumnSummary =“column-normalized”;ccscat。RowSummary =“row-normalized”;
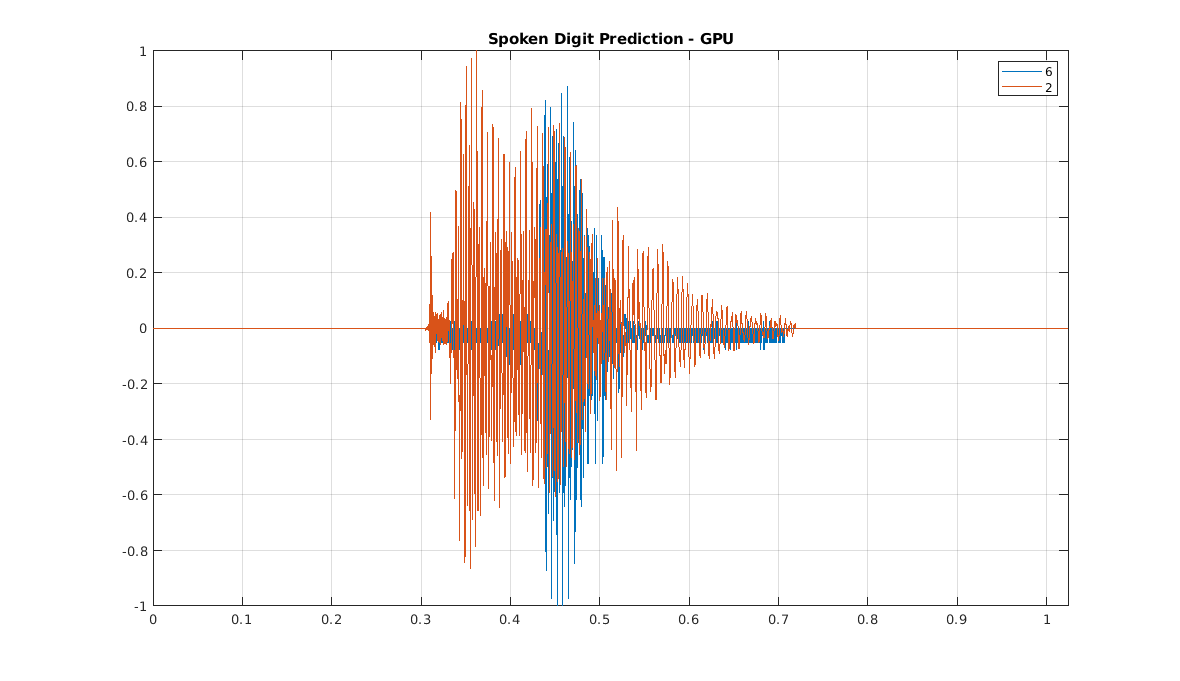
最后一个例子是,读前两个记录的数据集,计算散射特性,预测数字使用SVM训练和口语散射特性。
重置(广告);sig1 = helperReadSPData(阅读(广告);scat1 = sn.featureMatrix (sig1);scat1 =意味着(scat1 (2:,:), 2) ';plab1 =预测(classificationSVM scat1);
读下一个记录和预测数字。
sig2 = helperReadSPData(阅读(广告);scat2 = sn.featureMatrix (sig2);scat2 =意味着(scat2 (2:,:), 2) ';plab2 =预测(classificationSVM scat2);
t = 0:1/8000: -1/8000(即:8192 * 1/8000);情节(t) [sig1 sig2])网格在轴紧传奇(char (plab1), char (plab2))标题(“数字预测- GPU口语”)
附录
本例中使用以下辅助函数。
helpergenLabels——生成标签FSDD基于文件名。
函数标签= helpergenLabels(广告)%这个函数只用于小波工具箱的例子。它可能是%在将来发布的版本中修改或删除。tmp =细胞(元素个数(ads.Files), 1);表达=“[0 - 9]+ _”;为nf = 1:元素个数(ads.Files) idx = regexp (ads.Files {nf},表达式);tmp {nf} = ads.Files {nf} (idx);结束标签=分类(tmp);结束
helperReadSPData——确保每个spoken-digit记录长8192个样本。
函数x = helperReadSPData (x)%这个函数只用于小波工具箱的例子。它可能改变或%在将来的版本中被删除。N =元素个数(x);如果N > 8192 x = x (1:8192);elseifN < 8192垫= 8192 - N;前置液=地板(垫/ 2);postpad =装天花板(垫/ 2);x =[0(前置液,1);x;0 (postpad 1)];结束x =单(x / max (abs (x)));结束