 克利夫角:克利夫·莫尔谈数学和计算机
克利夫角:克利夫·莫尔谈数学和计算机 罗兰关于MATLAB的艺术
罗兰关于MATLAB的艺术 用MATLAB进行图像处理
用MATLAB进行图像处理 在simuli金宝appnk上的家伙
在simuli金宝appnk上的家伙 深度学习
深度学习 开发人员区
开发人员区 斯图尔特的MATLAB视频
斯图尔特的MATLAB视频 在标题后面
在标题后面 本周文件交换精选
本周文件交换精选 汉斯在某地面
汉斯在某地面 学生休息室
学生休息室 初创公司,加速器和企业家
初创公司,加速器和企业家 MATLAB社区
MATLAB社区 matlabユーザーコミュニティー
matlabユーザーコミュニティー深度学习的HRTF模型的优化
今天的帖子来自Sunil Bharitkar,他在惠普实验室人工智能与新兴计算实验室(AIECL)领导音频/语音研究。他将讨论他的研究使用深度学习建模和合成头部相关传递函数(HRTF)使用MATLAB。这项工作已经发表在一篇IEEE论文中,链接在文章的底部。
今天,我想讨论我的研究,专注于模拟如何使用深度学习的所有角度如何合成声音的新方法。
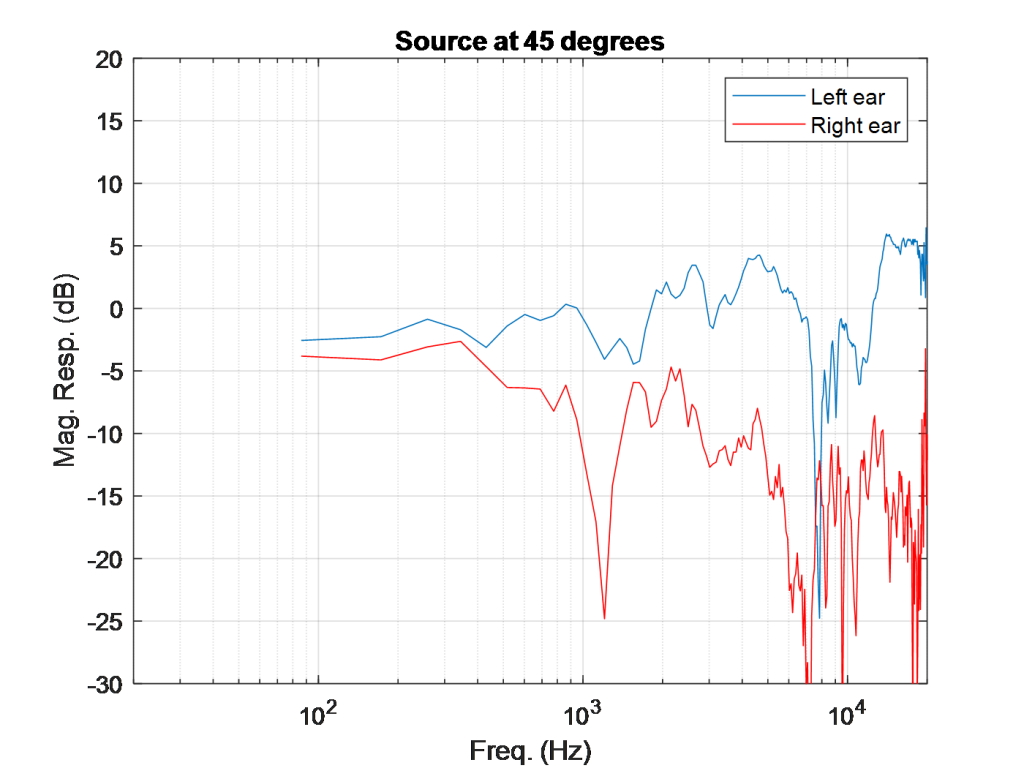
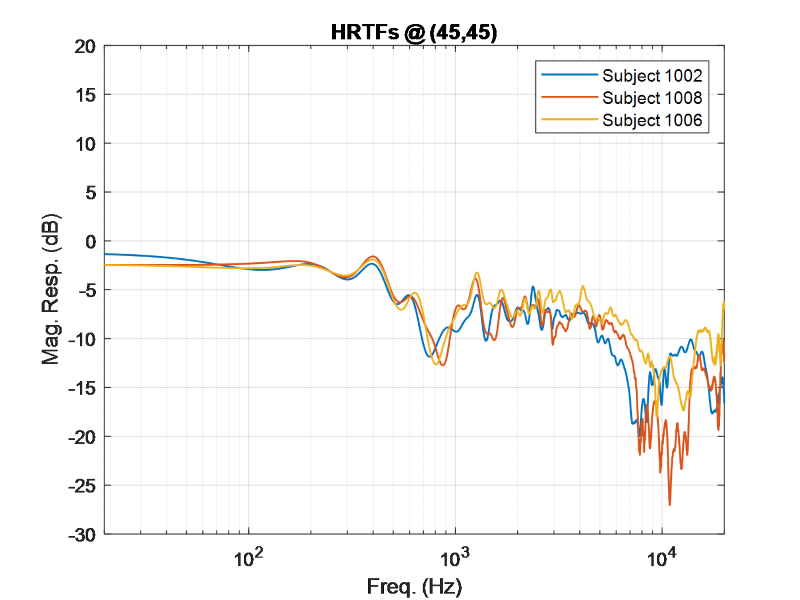
如果我们看这张图,你可以看到当一个声音在离中心45度的方向播放时,在这个角度左耳的声音的振幅比右耳的高。图中还包含了左耳和右耳到达时间的差异,只有几毫秒的差异可以对我们感知声音的位置产生重要影响。在潜意识里,我们根据频谱和延迟的差异来解释声源的位置。将此与人类落后180度的声音进行比较:
左耳和右耳的频谱细节在所有频率上几乎是相同的,因为声源与两耳的距离基本上是相等的。对于180度的声源来说,到达时间的差异将是微不足道的。这些差异(或缺乏)帮助我们确定声音的来源。我们非常擅长定位特定频率的声音,而不擅长其他频率。这取决于声音的频率和位置。
*有趣的是要注意,人类在确定某些角度是否在确定声音是否(例如,在混乱的锥体上)。如果我们混淆的是,我们可以帮助本地化的最佳方式是将我们的脑袋移动以便优化左耳和右耳之间的差异。我相信你现在很想在家里用你的下一个哔哔声警告尝试这个实验。
这项研究有许多应用,其中声音的定位是至关重要的。例如在电子游戏设计或虚拟现实中,声音必须与视频相匹配才能获得真正的沉浸式体验。为了让声音与视频匹配,我们必须在用户周围的期望位置匹配双耳的期望线索。这项研究有很多方面,这使得这是一个具有挑战性的问题来解决:
我们的身体结构和听觉是每个人独有的特质。唯一能百分百确定声音对一个人来说是完美的方法是在一个暗室里测量他们的个性化头部相关传递功能。这是非常不切实际的,因为我们的目标是让用户拥有最少的安装时间。这就引出了我研究的主要方面:
我们可以使用深度学习,以估计所有角度的HRTF,以获得大量听众的真正体验吗?
这个公式说的是,对于一个给定的用户,在一个给定的角度和特定的频率仓,比较实际振幅和网络的给定响应。对于PCA来说,我们发现,10个PC与我们的模型相比(如下图所示),因为这允许通过此方法正确覆盖大部分大型数据集。
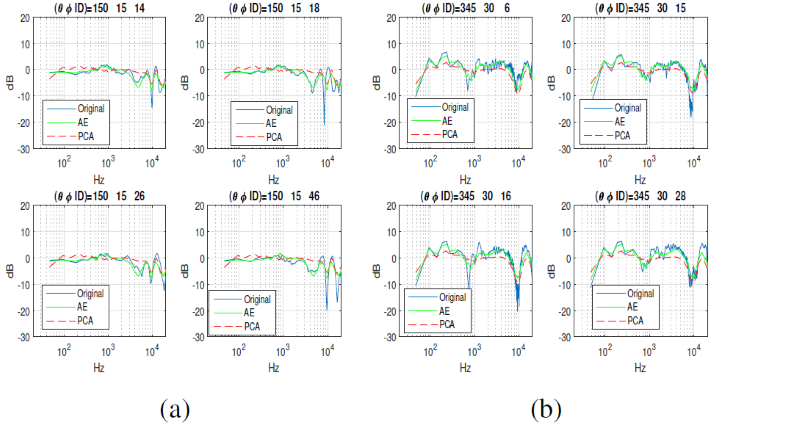
 这是一个随机抽样的测试对象,为给定的角度,显示了AE方法与PCA之间的结果。你可以看到大部分情况下,你可以看到使用深度学习方法的显著改善。
这是一个随机抽样的测试对象,为给定的角度,显示了AE方法与PCA之间的结果。你可以看到大部分情况下,你可以看到使用深度学习方法的显著改善。
 我创建的另一个很好的可视化清楚地显示了模型之间的区别:
我创建的另一个很好的可视化清楚地显示了模型之间的区别:
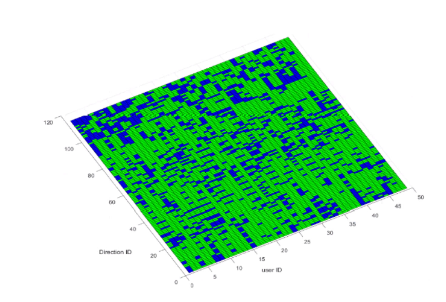
利用对数谱失真(dLS)对每个角度和每个用户进行了比较。绿框表示dLS低于PCA(越低越好)。蓝色部分表示基于PCA的方法优于自动编码器。正如您所看到的,在大多数情况下,AE编码器优于PCA。AE方法并不是100%的更好,但总体上肯定是一个更好的结果。
总之,我们展示了一种新的深度学习方法,表明,在最先进的PCA方法上表现出代表大型主题池HRTF的重大改善。我们正在继续测试大量的数据集,即使在更大的数据集大小,我们也在继续看到可重复的结果,因此我们确信这种方法正在产生一致的结果。如果你想了解更多关于这个主题的信息,请点击这里查看获得IEEE杰出论文奖的整篇论文的链接https://ieeexplore.ieee.org/document/8966196.
空间音频速成课程
这项研究的一个重要方面是声音的定位。这在音频应用中得到了广泛的研究,并与我们人类如何听到和理解声音来自哪里有关。这因人而异,但通常与每只耳朵(低于~ 800hz)的延迟和频率大于~ 800hz时每只耳朵的频谱细节有关。这些主要是我们在日常生活中用来定位声音的线索鸡尾酒会效应).下面是显示Head-Related脉冲响应在人体两个耳道入口的消声室中测量(左图),傅里叶域表示即,与头部相关的传递函数(右图),它显示了人类如何在可听频率的特定位置(例如,向左45度,向前和向上0度)听到双耳的声音。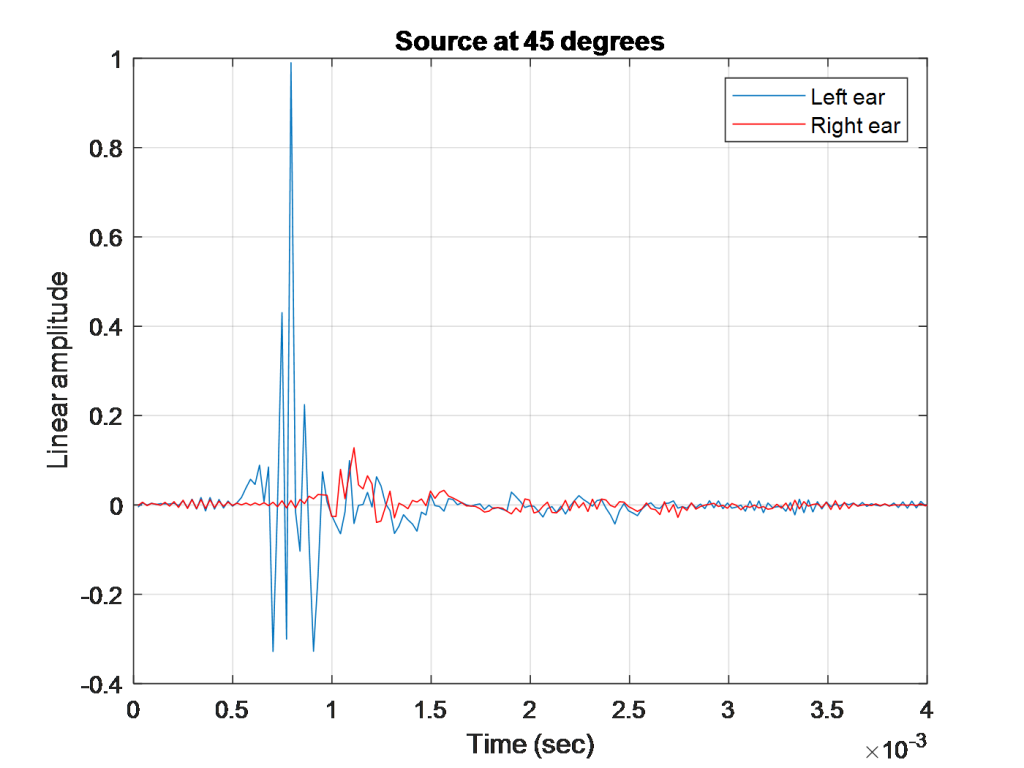 |
 |

- 人类非常擅长识别声音的差异,这些差异会让用户觉得是虚假的,从而导致体验不真实。
- 对于各个角度,头部相关传递函数对不同的人不同。
- 每个HRTF是依赖于方向的,对于任何给定的人,每个角度都会变化。
目前的技术状况和我们的新方法
你可能会问"如果每个人都是不同的,为什么不取所有图的平均值并创建一个平均HRTF呢"对此,我说"如果取平均值,你就会得到一个平均值"深度学习能帮助我们提高平均水平吗?在我们的研究之前,进行这种分析的主要方法是HRTF在一组人员上建模的原理分析分析。在过去,研究人员发现了5或6个组件,这些组件概括以及它们可以用于大约20个受试者的小型测试集([1] [2] [3]),但我们希望概括更大的数据集和一个大量的角度。我们将展现使用深度学习的新方法。我们将通过非线性函数来学习HRTFS的较低维度表示(潜伏表示)的自动统计方法,然后使用另一个网络(在这种情况下,在这种情况下)来映射到潜在表示来映射角度。我们从1个隐藏层的AutoEncoder开始,然后我们通过用验证度量进行贝叶斯优化(日志光谱失真度量)来优化隐藏层的数量和GRNN中的高斯RBF的扩展。下一节显示了这种新方法的细节。新的方法
对于我们的方法,我们使用IRCAM数据集,该数据集由49名受试者组成,每个受试者有115个声音方向。我们将使用一个自动编码器模型,并将其与主成分分析模型进行比较,(主成分分析模型是一个线性最优解,以PC的数量为条件),我们将使用客观比较,使用对数谱失真度量来比较性能的结果。数据设置
正如我提到的,数据集有49个受试者,115个角度,每个HRTF是通过计算1024个频率仓的FFT来创建的。问题陈述:我们能找到每个角度的HRTF表示来最大程度地满足所有受试者对这个角度的拟合吗?我们本质上是在寻找最好的一般化,对于所有的题目,对于115个角度中的每一个。- 我们还对深度学习模型使用了超参数调优(bayesopt)。
- 我们采取整个HRTF数据集(1024x5635)并培训AutoEncoder。隐藏层的输出为您提供了紧凑的输入数据表示。我们拍摄AutoEncoder,我们提取该表示,然后使用概括的RNN映射到角度。我们还添加了我们为每个角度和每个主题添加的抖动或噪音。这将有助于网络概括而不是过度装备,因为我们不寻找完美的答案(这不存在!),而是最适合所有测试对象的概括。
- 贝叶斯优化用于:
- AutoEncoder网络的大小(图层数)
- 抖动/噪声方差添加到每个角度
- GRNN的RBF扩展
结果
我们优化了对数谱失真以确定结果: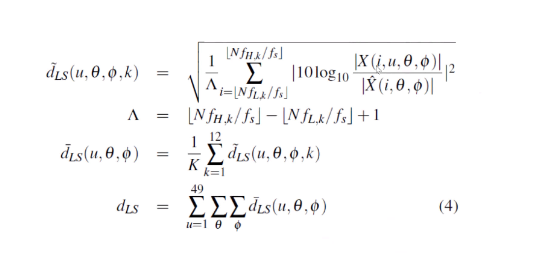

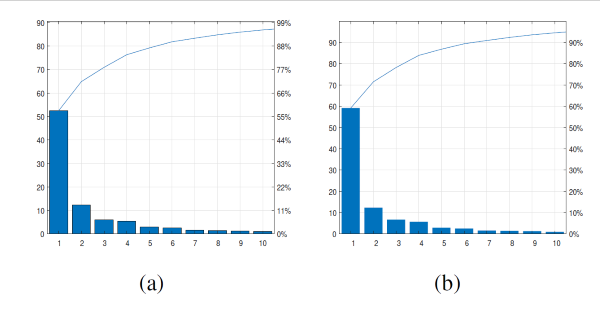
选择PCA订单(横坐标:没有。PC,纵坐标:解释方差),(a)左耳(b)右耳)

使用ae模型(绿色)与真实HRTF(蓝色)进行左耳HRTF重建比较的例子。主成分分析模型被用作锚,用红色表示。
参考
[1] . D. Kistler,和F. Wightman,“基于主成分分析和最小相位重构的头部相关传递函数模型”,J. Acoust。Soc。阿米尔。,vol. 91(3), 1992, pp. 1637-1647.[2] W. Martens,“对感知方向的光谱线索的主成分分析和再合成”,《中国科学(d辑)》。广告样稿,亩。Conf., 1987, 274-281页。[3] J. Sodnik,A. Umek,R. Susnik,G. Bobojevic和S. Tomazic,“与主要成分分析的头相关转移职能表示,”2004年11月“。
|
- 범주:
- 深度学习






댓글
댓글을남기려면링크를클릭하여MathWorks계정에로그인하거나계정을새로만드십시오。