Train DDPG Agent for Path-Following Control
This example shows how to train a deep deterministic policy gradient (DDPG) agent for path-following control (PFC) in Simulink®. For more information on DDPG agents, seeDeep Deterministic Policy Gradient Agents(Reinforcement Learning Toolbox)。
Simulink Model
此示例的增强学习环境是自我汽车的简单自行车模型,也是铅车的简单纵向模型。训练目标是通过控制纵向加速度和制动,在保持距离汽车的安全距离,同时保持自我的汽车通过控制前转向角,保持自我沿着车道的中心线行驶,以使自我汽车以固定的速度行驶。有关PFC的更多信息,请参阅Path Following Control System(Model Predictive Control Toolbox)。EGO CAR动力学由以下参数指定。
m = 1600;百分比总车辆质量(kg)Iz = 2875;% yaw moment of inertia (mNs^2)lf = 1.4;% longitudinal distance from center of gravity to front tires (m)lr = 1.6;% longitudinal distance from center of gravity to rear tires (m)CF = 19000;% cornering stiffness of front tires (N/rad)Cr = 33000;% cornering stiffness of rear tires (N/rad)tau = 0.5;% longitudinal time constant
指定两辆车的初始位置和速度。
x0_lead = 50;铅车的初始位置(M)v0_lead = 24;% initial velocity for lead car (m/s)x0_ego = 10;% initial position for ego car (m)v0_ego = 18;自我汽车的初始速度百分比(m/s)
指定停滞默认间距(m), gap (s), and driver-set velocity (m/s).
D_default = 10; t_gap = 1.4; v_set = 28;
To simulate the physical limitations of the vehicle dynamics, constrain the acceleration to the range[–3,2](m/s^2),转向角度与范围[–0.2618,0.2618](rad), that is -15 and 15 degrees.
amin_ego = -3; amax_ego = 2; umin_ego = -0.2618;% +15 degumax_ego = 0.2618;% -15 deg
The curvature of the road is defined by a constant 0.001 ( )。横向偏差的初始值为0.2 m,相对偏航角的初始值为–0.1 rad。
rho = 0.001; e1_initial = 0.2; e2_initial = -0.1;
Define the sample timeTsand simulation durationTf在seconds.
TS = 0.1;TF = 60;
Open the model.
mdl ='rlPFCMdl'; open_system(mdl) agentblk = [mdl' / RL代理'];

For this model:
The action signal consists of acceleration and steering angle actions. The acceleration action signal takes value between –3 and 2 (m/s^2). The steering action signal takes a value between –15 degrees (–0.2618 rad) and 15 degrees (0.2618 rad).
The reference velocity for the ego car 定义如下。如果相对距离小于安全距离,则自我汽车跟踪铅车速和驾驶员速度的最小值。以这种方式,自我汽车与铅汽车保持一定距离。如果相对距离大于安全距离,则自我汽车跟踪驾驶员速度。在此示例中,安全距离被定义为自我汽车纵向速度的线性函数 , that is, 。The safe distance determines the tracking velocity for the ego car.
来自环境的观察结果包含纵向测量:速度误差 , its integral 和自我汽车纵向速度 。In addition, the observations contain the lateral measurements: the lateral deviation , relative yaw angle , their derivatives and , and their integrals and 。
The simulation terminates when the lateral deviation , when the longitudinal velocity , or when the relative distance between the lead car and ego car 。
The reward , provided at every time step , is
where is the steering input from the previous time step , is the acceleration input from the previous time step. The three logical values are as follows.
如果终止模拟,否则
if lateral error , otherwise
if velocity error , otherwise
The three logical terms in the reward encourage the agent to make both lateral error and velocity error small, and in the meantime, penalize the agent if the simulation is terminated early.
Create Environment Interface
Create an environment interface for the Simulink model.
创建观察规范。
obsvervationInfo = rlnumericspec([9 1],,'LowerLimit',-inf*ones(9,1),'UpperLimit',inf*ones(9,1)); observationInfo.Name ='observations';
Create the action specification.
actionInfo = rlNumericSpec([2 1],'LowerLimit',[-3;-0.2618],'UpperLimit',[2;0.2618]); actionInfo.Name ='accel;steer';
Create the environment interface.
env = rl金宝appSimulinkenv(MDL,AgentBlk,ObsevervingInfo,ActionInfo);
To define the initial conditions, specify an environment reset function using an anonymous function handle. The reset functionlocalResetFcn,在示例的末尾定义了该定义,将铅车的初始位置随机,横向偏差和相对偏航角。
env.ResetFcn = @(in)localResetFcn(in);
修复随机发电机种子以获得可重复性。
rng(0)
Create DDPG Agent
DDPG代理通过使用评论家的价值函数表示,在观察和动作给定的情况下近似长期奖励。要创建评论家,首先创建一个具有两个输入的深度神经网络,即状态和动作以及一个输出。有关创建深神网络值函数表示的更多信息,请参见Create Policies and Value Functions(Reinforcement Learning Toolbox)。
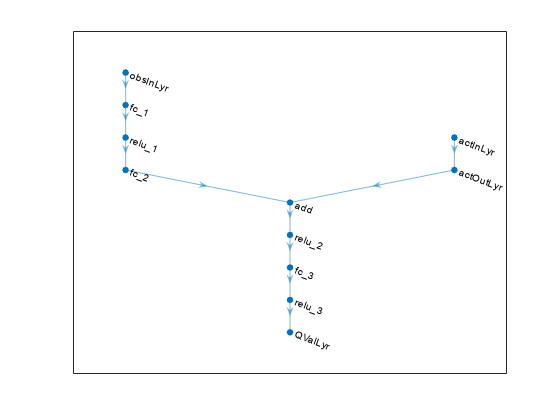
L = 100;% number of neuronsstatePath = [featurenputlayer(9,'Normalization','none','Name','observation') fullyConnectedLayer(L,'Name','fc1') reluLayer('Name','relu1') fullyConnectedLayer(L,'Name','fc2') additionLayer(2,'Name','add') reluLayer('Name','relu2') fullyConnectedLayer(L,'Name','fc3') reluLayer('Name','relu3') fullyConnectedLayer(1,'Name','fc4');actionPath = [ featureInputLayer(2,'Normalization','none','Name','action') fullyConnectedLayer(L,'Name','fc5');critisnetwork = layergraph(statePath);criticnetwork = addlayers(critisnetwork,actionpher);评论家= Connectlayers(评论家,'fc5','add/in2'); criticNetwork = dlnetwork(criticNetwork);
View the critic network configuration.
figure plot(layerGraph(criticNetwork))
Specify options for the critic optimizer usingrlOptimizerOptions。
criticOptions = rlOptimizerOptions(“LearnRate”,1e-3,'GradientThreshold',1,“ L2ReminizationFactor”,1e-4);
Create the critic function using the specified deep neural network. You must also specify the action and observation info for the critic, which you obtain from the environment interface. For more information, seerlQValueFunction(Reinforcement Learning Toolbox)。
评论家= rlqvaluefunction(评论家,观察,ActionInfo,。。。“观察名称”,'observation','ActionInputNames','action');
A DDPG agent decides which action to take given observations by using an actor representation. To create the actor, first create a deep neural network with one input, the observation, and one output, the action.
Construct the actor similarly to the critic. For more information, seerlContinuousDeterministicActor(Reinforcement Learning Toolbox)。
actorNetwork = [ featureInputLayer(9,'Normalization','none','Name','observation') fullyConnectedLayer(L,'Name','fc1') reluLayer('Name','relu1') fullyConnectedLayer(L,'Name','fc2') reluLayer('Name','relu2') fullyConnectedLayer(L,'Name','fc3') reluLayer('Name','relu3') fullyConnectedLayer(2,'Name','fc4')tanhlayer('Name','tanh1') scalingLayer('Name','ActorScaling1','Scale',[2.5;0.2618],'Bias',[-0.5;0])]; actorNetwork = dlnetwork(actorNetwork); actorOptions = rlOptimizerOptions(“LearnRate”,1e-4,'GradientThreshold',1,“ L2ReminizationFactor”,1e-4); actor = rlContinuousDeterministicActor(actorNetwork,observationInfo,actionInfo);
To create the DDPG agent, first specify the DDPG agent options usingrlDDPGAgentOptions(Reinforcement Learning Toolbox)。
agentOptions = rlDDPGAgentOptions(。。。'SampleTime',Ts,。。。'ActorOptimizerOptions',actorOptions,。。。'CriticOptimizerOptions',criticOptions,。。。'ExperienceBufferLength',1e6); agentOptions.NoiseOptions.Variance = [0.6;0.1]; agentOptions.NoiseOptions.VarianceDecayRate = 1e-5;
Then, create the DDPG agent using the specified actor representation, critic representation, and agent options. For more information, seerlDDPGAgent(Reinforcement Learning Toolbox)。
agent = rlddpgagent(演员,评论家,代理商);
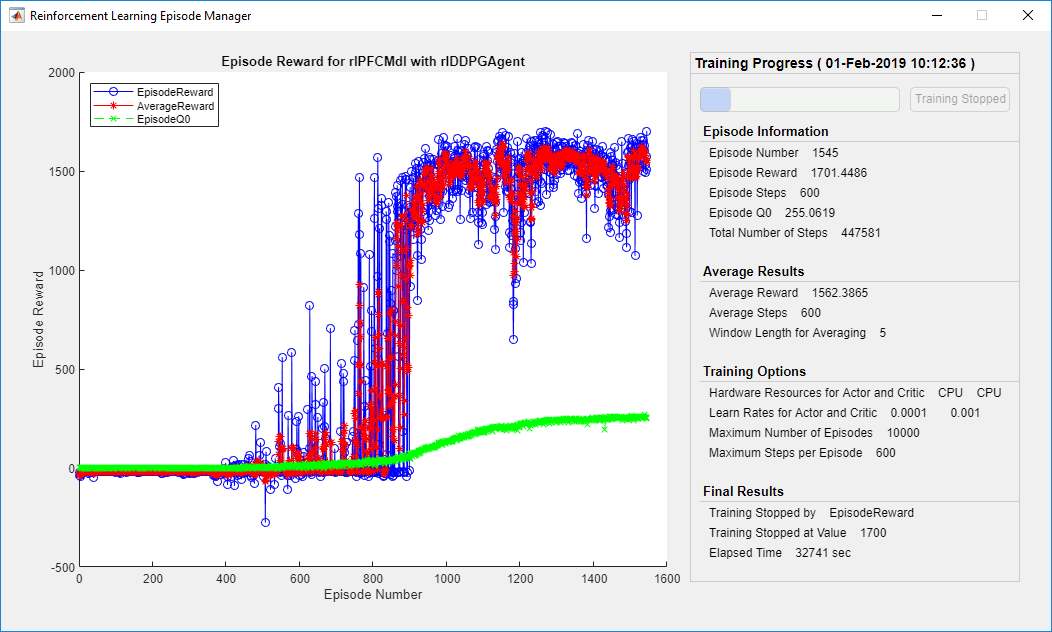
Train Agent
要培训代理商,请首先指定培训选项。对于此示例,请使用以下选项:
最多运行每个训练剧集
10000episodes, with each episode lasting at mostmaxstepstime steps.Display the training progress in the Episode Manager dialog box (set the
VerboseandPlotsoptions).Stop training when the agent receives an cumulative episode reward greater than
1700。
有关更多信息,请参阅rlTrainingOptions(Reinforcement Learning Toolbox)。
maxepisodes = 1e4; maxsteps = ceil(Tf/Ts); trainingOpts = rlTrainingOptions(。。。“ maxepisodes”,maxepisodes,。。。'MaxStepsperperepisode',maxsteps,。。。'Verbose',false,。。。“阴谋”,'training-progress',。。。'StopTrainingCriteria','EpisodeReward',。。。'StopTrainingValue',1700);
使用train(Reinforcement Learning Toolbox)function. Training is a computationally intensive process that takes several minutes to complete. To save time while running this example, load a pretrained agent by settingdoTrainingtofalse。To train the agent yourself, setdoTrainingtotrue。
doTraining = false;ifdoTraining% Train the agent.trainingStats = train(agent,env,trainingOpts);else% Load a pretrained agent for the example.load('SimulinkPFCDDPG.mat','agent')end
Simulate DDPG Agent
To validate the performance of the trained agent, simulate the agent within the Simulink environment by uncommenting the following commands. For more information on agent simulation, seerlsimulationptions(Reinforcement Learning Toolbox)andsim(Reinforcement Learning Toolbox)。
% simOptions = rlSimulationOptions('MaxSteps',maxsteps);% experience = sim(env,agent,simOptions);
To demonstrate the trained agent using deterministic initial conditions, simulate the model in Simulink.
e1_initial = -0.4;e2_initial = 0.1;x0_lead = 80;SIM(MDL)
The following plots show the simulation results when the lead car is 70 (m) ahead of the ego car.
在前35秒内,相对距离大于安全距离(右下角图),因此自我汽车跟踪设置速度(右上角)。为了加快速度并达到集合速度,加速度主要是无负(左上图)。
From 35 to 42 seconds, the relative distance is mostly less than the safe distance (bottom-right plot), so the ego car tracks the minimum of the lead velocity and set velocity. Because the lead velocity is less than the set velocity (top-right plot), to track the lead velocity, the acceleration becomes nonzero (top-left plot).
从42秒到58秒,EGO汽车跟踪设定速度(右上角),加速度保持零(左上图)。
From 58 to 60 seconds, the relative distance becomes less than the safe distance (bottom-right plot), so the ego car slows down and tracks the lead velocity.
The bottom-left plot shows the lateral deviation. As shown in the plot, the lateral deviation is greatly decreased within 1 second. The lateral deviation remains less than 0.05 m.

Close the Simulink model.
bdclose(mdl)
Reset Function
functionin = localResetfcn(in)in = setVariable(in,,'x0_lead',40+randi(60,1,1));% random value for initial position of lead carin = setVariable(in,'e1_initial', 0.5*(-1+2*rand));% random value for lateral deviationin = setVariable(in,'e2_initial', 0.1*(-1+2*rand));% random value for relative yaw angleend
See Also
train(Reinforcement Learning Toolbox)
Related Topics
- Train Reinforcement Learning Agents(Reinforcement Learning Toolbox)
- Create Policies and Value Functions(Reinforcement Learning Toolbox)
You can also select a web site from the following list:
Americas
- AméricaLatina(Español)
- Canada(英语)
- United States(英语)
Europe
- Belgium(英语)
- 丹麦(英语)
- Deutschland(Deutsch)
- España(Español)
- Finland(英语)
- France(Français)
- Ireland(英语)
- Italia(Italiano)
- Luxembourg(英语)
- Netherlands(英语)
- Norway(英语)
- Österreich(Deutsch)
- Portugal(英语)
- Sweden(英语)
- Switzerland
- 英国(英语)