simsmooth
模拟平滑的贝叶斯向量自回归(VAR)模型
语法
描述
simsmooth适合高级应用,如样本外预测条件的后预测分布的贝叶斯VAR (p)模型VARX (p)模型预测、缺失值归责,参数估计的缺失值。同时,simsmooth使您能够为样本外预测调整吉布斯采样器。从贝叶斯VAR估计样本外预测(p)模型,看预测。
(返回1000个随机系数向量的吸引λCoeffDraws,SigmaDraws)= simsmooth (PriorMdl,Y)多项式系数和创新协方差矩阵Σσ来自前结合形成的后验分布贝叶斯VAR (p)模型PriorMdl和响应数据Y。
抽样程序包括一个贝叶斯数据增加使用卡尔曼滤波器(参见步骤算法)。在抽样,simsmooth取代non-presample缺失值Y表示,由南值,估算值。
(使用附加选项指定一个或多个参数名称-值对。例如,您可以设置随机从分布的数量或指定presample响应数据。CoeffDraws,SigmaDraws)= simsmooth (PriorMdl,Y,名称,值)
(还返回估算每个画的响应值CoeffDraws,SigmaDraws,NaNDraws)= simsmooth (___)NaNDraws使用任何输入参数组合在前面的语法。
(还返回的意思CoeffDraws,SigmaDraws,NaNDraws,YMean,YStd)= simsmooth (___)YMean和标准偏差YStd的后预测分布增强的数据。
例子
模拟参数后验分布存在缺失值
当模拟估计得出参数的后验分布,它删除所有行数据,包含至少一个缺失值(南)。然而,simsmooth使用贝叶斯数据后评估期间增加转嫁non-presample缺失值。
考虑三维VAR(4)模型对美国通货膨胀(影响力),失业率(UNRATE)和联邦基金(FEDFUNDS)率。
对所有 , 是一系列独立的3 d正常创新0和协方差的意思吗 。认为疲软的共轭先验分布的参数 。
加载和数据预处理
负载美国宏观经济数据集,计算通货膨胀率和失业率稳定和联邦基金利率。
负载Data_USEconModelseriesnames = [“影响力”“UNRATE”“FEDFUNDS”];数据表。影响力=100*[NaN; price2ret(DataTable.CPIAUCSL)]; DataTable.DUNRATE = [NaN; diff(DataTable.UNRATE)]; DataTable.DFEDFUNDS = [NaN; diff(DataTable.FEDFUNDS)]; seriesnames(2:3) =“D”+ seriesnames (2:3);
有几个系列主要南值,因为他们的测量没有其他可用的同时测量。因为领导南值可能会干扰presample规范,删除所有行包含至少一个主要缺失值。
rmldDataTable = rmmissing(数据表(:,seriesnames));
创建之前模型
创建一个弱共轭先验模型通过指定大系数先验方差。指定响应系列名称。
numseries =元素个数(seriesnames);numlags = 4;PriorMdl = conjugatebvarm (numseries numlags,“SeriesNames”,seriesnames);numcoeffseqn =大小(PriorMdl.V, 1);PriorMdl。V=1e4*eye(numcoeffseqn);
随机数据中的缺失值的地方
说明模拟的缺失值,随机的地方失踪presample时期后的数据值。
rng (1)%的再现性T =大小(rmldDataTable, 1);idxpre = 1: PriorMdl.P;% Presample时期idx = (PriorMdl。P + 1): T;%的评估期nmissing = 20;%模拟最多nmissing缺失值sidx = [randsample (idx nmissing,真的);randsample (1: numseries nmissing,真的)];lsidx = sub2ind (T, numseries, sidx (1:), sidx (2:));MissData = table2array (rmldDataTable);MissData (lsidx) =南;MissDataTable = rmldDataTable;MissDataTable {:,:} = MissData;
模拟参数后
吸引1000从后验分布通过调用参数设置simsmooth估计参数的后验分布,然后后预测分布形式。
[多项式系数,σ]= simsmooth (PriorMdl MissDataTable.Variables);
多项式系数是一个39 -到- 1000矩阵的随机引起了后的系数向量。σ是一个3 -通过- 3 - 1000组随机吸引创新协方差矩阵。
默认情况下,simsmooth初始化VAR模型通过使用第一个四观测数据。
把行多项式系数系数,通过使用获得先验分布的总结总结。在一个表中,显示第一组随机系数与相应的名称。
摘要=总结(PriorMdl,“关闭”);表(多项式系数(:1),“RowNames”Summary.CoeffMap)
ans =39×1表Var1 __________ AR{1}(1,1) 0.22109基于“增大化现实”技术的{1}(1、2)-0.24034基于“增大化现实”技术的{1}(1、3)0.093315基于“增大化现实”技术的{2}(1,1)0.18329基于“增大化现实”技术的{2}(1、2)-0.23178基于“增大化现实”技术的{2}(1、3)-0.026301 AR {3} (1,1) 0.39991 AR {3} (1、2) 0.41141 AR {3} (1、3) 0.054702 AR {4} (1,1) 0.024944 AR {4} (1、2) -0.37372 AR{4}(1、3) -0.0095642常数0.21499 AR(1){1}(2, 1) -0.073776基于“增大化现实”技术的{1}(2,2)0.36086基于“增大化现实”技术的{1}⋮0.071088 (2、3)
或者,您可以创建一个吸引的经验模型,和使用总结通过指定任何显示选项来显示模型。
显示汇总后将作为一个方程。
EmpMdl = empiricalbvarm (numseries numlags,“SeriesNames”seriesnames,…“CoeffDraws”多项式系数,“SigmaDraws”σ);总结(EmpMdl“方程”)
VAR方程|影响力(1)DUNRATE (1) DFEDFUNDS(1)影响力(2)DUNRATE (2) DFEDFUNDS(2)影响力(3)DUNRATE (3) DFEDFUNDS(3)影响力(4)DUNRATE (4) DFEDFUNDS(4)常数- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -影响力| 0.1447 -0.3685 0.1013 0.2974 -0.0959 0.0360 0.4115 0.2244 0.0474 0.0265 -0.2321 0.0030 0.1095 | (0.0744)(0.1314)(0.0370)(0.0833)(0.1509)(0.0398)(0.0833)(0.1440)(0.0403)(0.0879)(0.1301)(0.0370)(0.0744)DUNRATE | -0.0187 0.4445 0.0314 0.0836 0.2372 0.0489 -0.0407 -0.0548 -0.0064 0.0483 -0.1753 0.0027 -0.0597 | (0.0447) (0.0808) (0.0234) (0.0514) (0.0863) (0.0230) (0.0507) (0.0906) (0.0243) (0.0514) (0.0779) (0.0225) (0.0466) DFEDFUNDS | -0.2046 -1.1927 -0.2524 0.2864 -0.2282 -0.2657 0.2709 -0.6231 0.0289 -0.0404 0.1043 -0.1236 -0.2952 |(0.1530)(0.2931)(0.0816)(0.1832)(0.3123)(0.0857)(0.1736)(0.3105)(0.0900)(0.1866)(0.2880)(0.0758)(0.1684)创新协方差矩阵|影响力DUNRATE DFEDFUNDS - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -影响力| 0.1346 | 0.2842 - -0.0098 (0.0286)(0.0122)(0.0464)DUNRATE | -0.1496 | -0.0098 - 0.1062 (0.0122) (0.0106) (0.0296) DFEDFUNDS | 1.3187 | 0.1346 - -0.1496 (0.0464) (0.0296) (0.1422)
检查的数据
考虑的3 d VAR(4)模型模拟参数后验分布存在缺失值。
负载美国宏观经济数据集,计算通货膨胀率和失业率稳定和联邦基金利率。
负载Data_USEconModelseriesnames = [“影响力”“UNRATE”“FEDFUNDS”];数据表。影响力=100*[NaN; price2ret(DataTable.CPIAUCSL)]; DataTable.DUNRATE = [NaN; diff(DataTable.UNRATE)]; DataTable.DFEDFUNDS = [NaN; diff(DataTable.FEDFUNDS)]; seriesnames(2:3) =“D”+ seriesnames (2:3);
删除所有行包含主要缺失值。
rmldDataTable = rmmissing(数据表(:,seriesnames));
创建一个弱共轭先验模型。指定响应系列名称。
numseries =元素个数(seriesnames);numlags = 4;PriorMdl = conjugatebvarm (numseries numlags,“SeriesNames”,seriesnames);numcoeffseqn =大小(PriorMdl.V, 1);PriorMdl。V=1e4*eye(numcoeffseqn);
随机的地方失踪presample时期后的数据值。
rng (1)%的再现性T =大小(rmldDataTable, 1);idxpre = 1: PriorMdl.P;% Presample时期idx = (PriorMdl。P + 1): T;%的评估期nmissing = 20;%模拟最多nmissing缺失值sidx = [randsample (idx nmissing,真的);randsample (1: numseries nmissing,真的)];lsidx = sub2ind (T, numseries, sidx (1:), sidx (2:));MissData = table2array (rmldDataTable);MissData (lsidx) =南;MissDataTable = rmldDataTable;MissDataTable {:,:} = MissData;
吸引1000从后验分布通过调用参数设置simsmooth。返回值,仿真平滑背景为失踪的观察。
[~,~,NaNDraws] = simsmooth (PriorMdl MissDataTable.Variables);
NaNDraws19 - - 1000矩阵的随机响应向量来自后预测分布。元素对应于数据中的缺失值列搜索命令。例如,NaNDraws (3,1)是第一个随机画第三个缺失值的估算响应数据。找到相应的值的数据。
[idxi, idxj] =找到(ismissing (MissDataTable), 3);responsename = seriesnames (idxj(结束)
responsename = "影响力"
observationtime = MissDataTable.Time (idxi(结束)
observationtime =datetime第三季度- 65
情节的经验分布的估算值在第三季度- 65年通货膨胀率。
标题:直方图(NaNDraws (3)) (“第三季度- 65年通货膨胀率经验分布”)

调整抽样方案的模拟更平稳
考虑的3 d VAR(4)模型模拟参数后验分布存在缺失值。
美国宏观经济数据集加载。计算通货膨胀率,稳定失业率和联邦基金利率,和删除缺失值(数据只包括主要缺失值)。
负载Data_USEconModelseriesnames = [“影响力”“UNRATE”“FEDFUNDS”];数据表。影响力=100*[NaN; price2ret(DataTable.CPIAUCSL)]; DataTable.DUNRATE = [NaN; diff(DataTable.UNRATE)]; DataTable.DFEDFUNDS = [NaN; diff(DataTable.FEDFUNDS)]; seriesnames(2:3) =“D”+ seriesnames (2:3);rmDataTable = rmmissing(数据表);
创建一个弱共轭先验模型。指定响应系列名称。
numseries =元素个数(seriesnames);numlags = 4;PriorMdl = conjugatebvarm (numseries numlags,“SeriesNames”,seriesnames);numcoeffseqn =大小(PriorMdl.V, 1);PriorMdl。V=1e4*eye(numcoeffseqn);
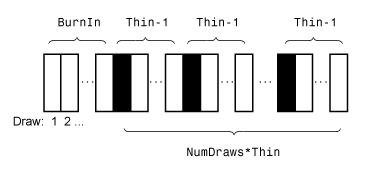
模拟5000系数和创新协方差矩阵的后验分布。指定一个老化1000和稀释5倍。
rng (1);%的再现性[多项式系数,σ]= simsmooth (PriorMdl rmDataTable {:, seriesnames},…“NumDraws”,5000,“燃烧”,1000,“薄”5);
多项式系数是39 -到- 5000系数矩阵,然后呢σ是一个3 -通过- 3 - 5000创新协方差矩阵的数组。这两个多项式系数和σ是随机的后验分布。
指定起始值模拟平滑系数
考虑的3 d VAR(4)模型模拟参数后验分布存在缺失值。在这种情况下,假设semiconjugate之前模型。
美国宏观经济数据集加载。计算通货膨胀率,稳定失业率和联邦基金利率,和删除缺失值(数据只包括主要缺失值)。
负载Data_USEconModelseriesnames = [“影响力”“UNRATE”“FEDFUNDS”];数据表。影响力=100*[NaN; price2ret(DataTable.CPIAUCSL)]; DataTable.DUNRATE = [NaN; diff(DataTable.UNRATE)]; DataTable.DFEDFUNDS = [NaN; diff(DataTable.FEDFUNDS)]; seriesnames(2:3) =“D”+ seriesnames (2:3);rmDataTable = rmmissing(数据表);
创建一个semiconjugate先验模型。指定响应系列名称。
numseries =元素个数(seriesnames);numlags = 4;PriorMdl = bayesvarm (numseries numlags,“ModelType”,“semiconjugate”,…“SeriesNames”,seriesnames);
获得值系数,开始考虑从VAR模型系数安装前30的观察。
定义索引,分区数据集分成四组:
长度p= 4初始化期间的动态的组件模型
= 30观测的VAR估计系数初始值
长度p= 4初始化期间动态组件的贝叶斯VAR模型
剩下的 观察评估后
T =大小(rmDataTable);n0 = 30;idxpre0 = 1: PriorMdl.P;idxest0 = (idxpre0(结束)+ 1):(idxpre0(结束)+ 1 + n0);idxpre1 = (idxest0(结束)+ 1 - PriorMdl.P): idxest0(结束);idxest1 = (idxest0(结束)+ 1):T;n1 =元素个数(idxest1);
获得初始值的拟合系数VAR模型对第一个34的观察。使用前四presample观测。
Mdl0 = varm (PriorMdl.NumSeries PriorMdl.P);EstMdl0 =估计(Mdl0 rmDataTable {idxest0, seriesnames},“Y0”rmDataTable {idxpre0 seriesnames});
估计返回一个包含AR系数估计的模型对象在一个向量矩阵形式和常量。贝叶斯VAR功能需要初始向量系数值。格式最初的系数值。
(EstMdl0 Coeff0 =。一个R{:} EstMdl0.Constant].'; Coeff0 = Coeff0(:);
模拟1000系数和创新协方差矩阵的后验分布。指定的评估后的观察。初始化VAR模型通过指定最后四观察在前面presample估计样本,并指定初始系数向量来初始化后样品。
rng (1);%的再现性[多项式系数,σ]= simsmooth (PriorMdl rmDataTable {idxest1, seriesnames},…“Y0”rmDataTable {idxpre1 seriesnames},“Coeff0”,Coeff0);
多项式系数是39 - - 1000系数矩阵和σ是一个3 -通过- 3 - 1000创新协方差矩阵的数组。这两个多项式系数和σ是随机的后验分布。
从后预测分布预测的反应
考虑的3 d VAR(4)模型模拟参数后验分布存在缺失值。
加载和数据预处理
美国宏观经济数据集加载。计算通货膨胀率,稳定失业率和联邦基金利率,和删除缺失值(数据只包括主要缺失值)。
负载Data_USEconModelseriesnames = [“影响力”“UNRATE”“FEDFUNDS”];数据表。影响力=100*[NaN; price2ret(DataTable.CPIAUCSL)]; DataTable.DUNRATE = [NaN; diff(DataTable.UNRATE)]; DataTable.DFEDFUNDS = [NaN; diff(DataTable.FEDFUNDS)]; seriesnames(2:3) =“D”+ seriesnames (2:3);rmDataTable = rmmissing(数据表);
创建之前模型
创建一个弱共轭先验模型。指定响应系列名称。
numseries =元素个数(seriesnames);numlags = 4;PriorMdl = conjugatebvarm (numseries numlags,“SeriesNames”,seriesnames);numcoeffseqn =大小(PriorMdl.V, 1);PriorMdl。V=1e4*eye(numcoeffseqn);
预测反应使用预测
直接预测两年(8个季度)的观察后预测分布。预测估计参数的后验分布,然后后预测分布形式。
rng (1);%的再现性numperiods = 8;YF =预测(PriorMdl、numperiods rmDataTable {:, seriesnames});
YF是一个8-by-3矩阵的预测反应。
画出预测反应。
跳频= rmDataTable.Time(结束)+ calquarters (1:8);为j = 1: PriorMdl。NumSeries次要情节(3 1 j)情节(rmDataTable。T我米e(end- - - - - -20:end),rmDataTable{end - 20:end,seriesnames(j)},“r”,…[rmDataTable.Time(结束)跳频]、[rmDataTable{结束,seriesnames (j)};YF (:, j)),“b”);传奇(“观察”,“预测”,“位置”,“西北”)标题(seriesnames (j))结束

预测反应使用simsmooth
配置数据集获取预测simsmooth通过连接一个numperiods——- - - - - -numseries时间表的缺失值的设置。
金融交易税= array2timetable (NaN (numperiods numseries),“RowTimes”跳频,…“VariableNames”,seriesnames);frmDataTable = [rmDataTable (:, seriesnames);金融交易税];尾(frmDataTable)
ans =8×3的时间表____时间影响力DUNRATE DFEDFUNDS _____ _____ _____ Q2-09南南南Q3-09南南南Q4-09南南南Q1-10南南南Q2-10南南南Q3-10南南南Q4-10南南南Q1-11南南南
预测使用的VAR模型simsmooth。就像预测,simsmooth估计后验分布,所以它需要先验模型和数据。指定数据包含落后南年代。
[~,~,~,YMean] = simsmooth (PriorMdl frmDataTable.Variables);
YMean几乎等于frmDataTable,这些异常:
YMean不包括行对应presample时期frmDataTable (1:4,:)。如果
frmDataTable (j,k)是南,YMean (j,k)后预测分布的反应k在时间j。
建立一个时间表YMean。
YMeanTT = array2timetable (YMean,“RowTimes”frmDataTable.Time ((PriorMdl。P + 1):结束),…“VariableNames”,seriesnames);
画出预测反应。
为j = 1: PriorMdl。NumSeries次要情节(3 1 j)情节(YMeanTT。T我米e((end- - - - - -20- - - - - - numperiods):(end - numperiods)),YMeanTT{(end - 20 - numperiods):(end - numperiods),j},“r”,…YMeanTT。T我米e((end- - - - - -numperiods):end),YMeanTT{(end - numperiods):end,j},“b”);传奇(“观察”,“预测”,“位置”,“西北”)标题(seriesnames (j))结束

估计条件预测
考虑的3 d VAR(4)模型模拟参数后验分布存在缺失值。
美国宏观经济数据集加载。计算通货膨胀率,稳定失业率和联邦基金利率,和删除缺失值(数据只包括主要缺失值)。
负载Data_USEconModelseriesnames = [“影响力”“UNRATE”“FEDFUNDS”];数据表。影响力=100*[NaN; price2ret(DataTable.CPIAUCSL)]; DataTable.DUNRATE = [NaN; diff(DataTable.UNRATE)]; DataTable.DFEDFUNDS = [NaN; diff(DataTable.FEDFUNDS)]; seriesnames(2:3) =“D”+ seriesnames (2:3);rmDataTable = rmmissing(数据表);
创建一个弱共轭先验模型。指定响应系列名称。
numseries =元素个数(seriesnames);numlags = 4;PriorMdl = conjugatebvarm (numseries numlags,“SeriesNames”,seriesnames);numcoeffseqn =大小(PriorMdl.V, 1);PriorMdl。V=1e4*eye(numcoeffseqn);
条件预测响应值时已知或假设预测地平线,和未知值预测条件的已知值。假设失业率变化(DUNRATE通过两年的预测地平线)仍然保持在百分之一。
配置数据集获取预测simsmooth通过连接一个numperiods——- - - - - -numseries时间表的缺失值的设置。失业率的变化,将缺失的值替换为一个向量的。
rng (1);%的再现性numperiods = 8;跳频= rmDataTable.Time(结束)+ calquarters (1:8);金融交易税= array2timetable (NaN (numperiods numseries),“RowTimes”跳频,…“VariableNames”,seriesnames);frmDataTable = [rmDataTable (:, seriesnames);金融交易税];frmDataTable。DUNRATE((end- - - - - -numperiods+1):end) = ones(numperiods,1); tail(frmDataTable)
ans =8×3的时间表____时间影响力DUNRATE DFEDFUNDS _____ _____ _____ Q2-09南南Q3-09南1南Q4-09南南Q1-10南1南Q2-10南南Q3-10南1南Q4-10南1南Q1-11南南
获得预期通货膨胀率和联邦基金利率变化系列,鉴于失业率的变化是一个用于整个地平线。
[~,~,~,YMean] = simsmooth (PriorMdl frmDataTable.Variables);
YMean几乎等于frmDataTable,这些异常:
YMean不包括行对应presample时期frmDataTable (1:4,:)。如果
frmDataTable (j,k)是南,YMean (j,k)后预测分布的反应k在时间j。
建立一个时间表YMean。
YMeanTT = array2timetable (YMean,“RowTimes”frmDataTable.Time ((PriorMdl。P + 1):结束),…“VariableNames”,seriesnames);
画出预测反应。
为j = 1: PriorMdl。NumSeries次要情节(3 1 j)情节(YMeanTT。T我米e((end- - - - - -20- - - - - - numperiods):(end - numperiods)),YMeanTT{(end - 20 - numperiods):(end - numperiods),j},“r”,…YMeanTT。T我米e((end- - - - - -numperiods):end),YMeanTT{(end - numperiods):end,j},“b”);传奇(“观察”,“预测”,“位置”,“西北”)标题(seriesnames (j))结束

VARX预测模型
考虑到二维VARX(1)模型对美国实际国内生产总值(RGDP)和投资(全球教育运动)利率对个人消费(PCEC外生)率:
对所有 , 是一系列独立的二维正常创新0和协方差的意思吗 。假设先验分布如下:
,M是一个4×2的矩阵方法和矩阵 是一个4×4 among-coefficient尺度矩阵。同样, 。
Ω是2×2矩阵规模和在哪里 的自由度。
美国宏观经济数据集加载。计算实际国内生产总值,投资和个人消费系列。删除所有缺失的值产生的系列。
负载Data_USEconModel数据表。RGDP=数据表。GDP./DataTable.GDPDEF; seriesnames = [“PCEC”;“RGDP”;“全球教育运动”];率= varfun (@price2ret DataTable,“数据源”,seriesnames);率= rmmissing(率);rates.Properties。V一个r我一个bleNames = seriesnames;
创建一个二维VARX共轭先验模型(1)模型参数。
numseries = 2;numlags = 1;numpredictors = 1;PriorMdl = conjugatebvarm (numseries numlags,“NumPredictors”numpredictors,…“SeriesNames”seriesnames(2:结束));
创建索引,分区数据集到估计和预测样本。指定一个预测地平线的两年。
T =大小(利率,1);numperiods = 8;idx = 1: (T - numperiods);%包括presampleidxf = (T - numperiods + 1): T;idxtot = [idx idxf];
仿真平滑预测冠之缺失值。因此,创建一个数据集,其中包含缺失值的响应预测地平线。
missingrates =利率;missingrates {idxf PriorMdl。SeriesNames} =南(numperiods PriorMdl.NumSeries);
预测反应预测地平线。指定外生presample观察和预测数据。返回后预测分布的标准偏差。
rng (1)%的再现性[~,~,~,YMean YStd] = simsmooth (PriorMdl, missingrates {:, PriorMdl.SeriesNames},…“X”seriesnames missingrates {: (1)});
建立一个时间表YMean。
YMeanTT = array2timetable (YMean,“RowTimes”rates.Time ((PriorMdl。P + 1):结束),…“VariableNames”,PriorMdl.SeriesNames);
画出预测反应。
为j = 1: PriorMdl。NumSeries次要情节(PriorMdl.NumSeries 1 j)情节(利率。T我米e((end- - - - - -20):end),rates{(end - 20):end,PriorMdl.SeriesNames(j)},“r”,…YMeanTT。T我米e((end- - - - - -numperiods):end),YMeanTT{(end - numperiods):end,PriorMdl.SeriesNames(j)},“b”);传奇(“观察”,“预测”,“位置”,“西北”)标题(PriorMdl.SeriesNames (j))结束

输入参数
输出参数
更多关于
提示
蒙特卡罗模拟是可能变更。如果
simsmooth使用蒙特卡罗模拟,那么当你叫估计和推断可能有所不同simsmooth在看似同等条件下多次。复制估算结果,设置一个随机数种子通过使用rng在调用之前simsmooth。
算法
引用
[1]Litterman罗伯特•B。“与贝叶斯向量自回归预测:五年的经验。”商业和经济统计》杂志上4,没有。1(1986年1月):25-38。https://doi.org/10.2307/1391384。
