推断出
推断条件方差模型的条件方差
描述
例子
推断GARCH模型条件方差
从已知系数的GARCH(1,1)模型推断条件方差。当您使用,然后不使用预样例数据,比较结果推断出.
指定一个参数已知的GARCH(1,1)模型。从模型中模拟101个条件方差和响应(创新)。将每个系列的第一次观察结果放在一边作为前样本数据。
Mdl = garch (“不变”, 0.01,“四国”, 0.8,“拱”, 0.15);rng默认的;%的再现性(vS, y) =模拟(Mdl, 101);y0 = y (1);v0 = vS (1);y = y(2:结束);v = vS(2:结束);图subplot(2,1,1) plot(v) title(“有条件的差异”) subplot(2,1,2) plot(y) title(“创新”)
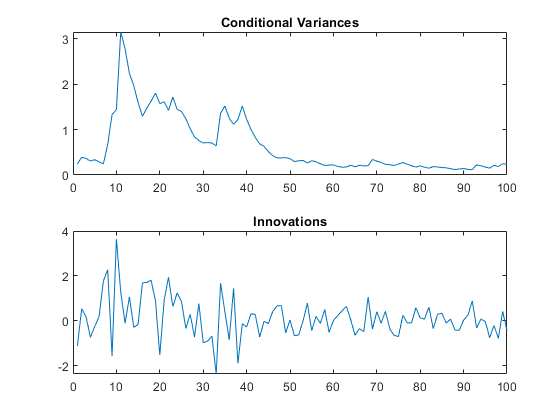
的条件方差y不使用前样例数据。将它们与已知(模拟的)条件方差进行比较。
vI =推断(Mdl y);图绘制(1:10 0 v,“r”,“线宽”, 2)在情节(1:10 0,vI,凯西:”,“线宽”传说,1.5)(“模拟”,“推断”,“位置”,“东北”)标题(“推断条件方差-无样本”)举行从

注意由于缺少前采样数据而导致的早期瞬态响应(差异)。
使用预留样本前创新来推断条件方差,y0.将它们与已知(模拟的)条件方差进行比较。
vE =推断(Mdl y“E0”, y0);图绘制(1:10 0 v,“r”,“线宽”, 2)在情节(1:10 0、vE、凯西:”,“线宽”传说,1.5)(“模拟”,“推断”,“位置”,“东北”)标题(推断条件方差-样本E)举行从

在早期阶段,瞬态响应略有降低。
使用预先准备好的条件方差来推断条件方差,半.将它们与已知(模拟的)条件方差进行比较。
签证官=推断(Mdl y“半”v0);图绘制(v)情节(1:10 0 v,“r”,“线宽”, 2)在情节(1:10 0,签证官,凯西:”,“线宽”传说,1.5)(“模拟”,“推断”,“位置”,“东北”)标题(推断条件方差-前例V)举行从
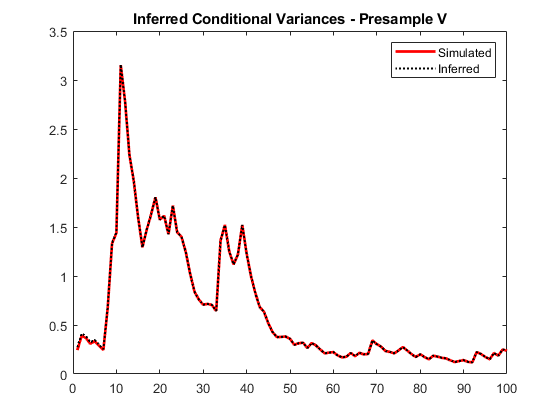
在早期阶段,瞬态响应要小得多。
使用前样本创新和条件方差来推断条件方差。将它们与已知(模拟的)条件方差进行比较。
vEO =推断(Mdl y“E0”, y0,“半”v0);图绘制(v)情节(1:10 0 v,“r”,“线宽”, 2)在vEO情节(1:10 0,凯西:”,“线宽”传说,1.5)(“模拟”,“推断”,“位置”,“东北”)标题(“推断条件方差-样本”)举行从

当您使用足够的前样例创新和条件方差时,推断出的条件方差是准确的(没有瞬态响应)。
推断EGARCH模型条件方差
从已知系数的EGARCH(1,1)模型推断条件方差。当您使用,然后不使用预样例数据,比较结果推断出.
指定一个参数已知的EGARCH(1,1)模型。从模型中模拟101个条件方差和响应(创新)。将每个系列的第一次观察结果放在一边作为前样本数据。
Mdl = egarch (“不变”, 0.001,“四国”, 0.8,…“拱”, 0.15,“杠杆”, -0.1);rng默认的;%的再现性(vS, y) =模拟(Mdl, 101);y0 = y (1);v0 = vS (1);y = y(2:结束);v = vS(2:结束);图subplot(2,1,1) plot(v) title(“有条件的差异”) subplot(2,1,2) plot(y) title(“创新”)

的条件方差y不使用任何预样例数据。将它们与已知(模拟的)条件方差进行比较。
vI =推断(Mdl y);图绘制(1:10 0 v,“r”,“线宽”, 2)在情节(1:10 0,vI,凯西:”,“线宽”传说,1.5)(“模拟”,“推断”,“位置”,“东北”)标题(“推断条件方差-无样本”)举行从
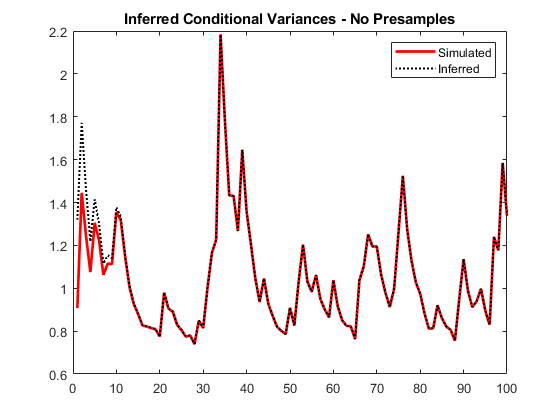
注意由于缺少前采样数据而导致的早期瞬态响应(差异)。
使用预留样本前创新来推断条件方差,y0.将它们与已知(模拟的)条件方差进行比较。
vE =推断(Mdl y“E0”, y0);图绘制(1:10 0 v,“r”,“线宽”, 2)在情节(1:10 0、vE、凯西:”,“线宽”传说,1.5)(“模拟”,“推断”,“位置”,“东北”)标题(推断条件方差-样本E)举行从
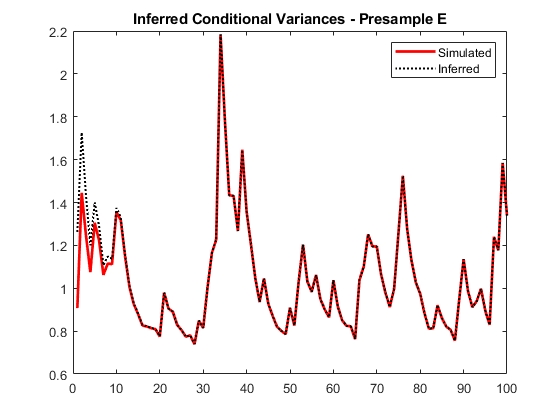
在早期阶段,瞬态响应略有降低。
使用预留的前样本方差推断条件方差,半.将它们与已知(模拟的)条件方差进行比较。
签证官=推断(Mdl y“半”v0);图绘制(v)情节(1:10 0 v,“r”,“线宽”, 2)在情节(1:10 0,签证官,凯西:”,“线宽”传说,1.5)(“模拟”,“推断”,“位置”,“东北”)标题(推断条件方差-前例V)举行从

瞬态响应几乎被消除。
使用前样本创新和条件方差来推断条件方差。将它们与已知(模拟的)条件方差进行比较。
vEO =推断(Mdl y“E0”, y0,“半”v0);图绘制(v)情节(1:10 0 v,“r”,“线宽”, 2)在vEO情节(1:10 0,凯西:”,“线宽”传说,1.5)(“模拟”,“推断”,“位置”,“东北”)标题(“推断条件方差-样本”)举行从

当您使用足够的前样例创新和条件方差时,推断出的条件方差是准确的(没有瞬态响应)。
推断GJR模型条件方差
从已知系数的GJR(1,1)模型推断条件方差。当您使用,然后不使用预样例数据,比较结果推断出.
指定已知参数的GJR(1,1)模型。从模型中模拟101个条件方差和响应(创新)。将每个系列的第一次观察结果放在一边作为前样本数据。
Mdl = gjr (“不变”, 0.01,“四国”, 0.8,“拱”, 0.14,…“杠杆”, 0.1);rng默认的;%的再现性(vS, y) =模拟(Mdl, 101);y0 = y (1);v0 = vS (1);y = y(2:结束);v = vS(2:结束);图subplot(2,1,1) plot(v) title(“有条件的差异”) subplot(2,1,2) plot(y) title(“创新”)

的条件方差y不使用任何预样例数据。将它们与已知(模拟的)条件方差进行比较。
vI =推断(Mdl y);图绘制(1:10 0 v,“r”,“线宽”, 2)在情节(1:10 0,vI,凯西:”,“线宽”传说,1.5)(“模拟”,“推断”,“位置”,“东北”)标题(“推断条件方差-无样本”)举行从
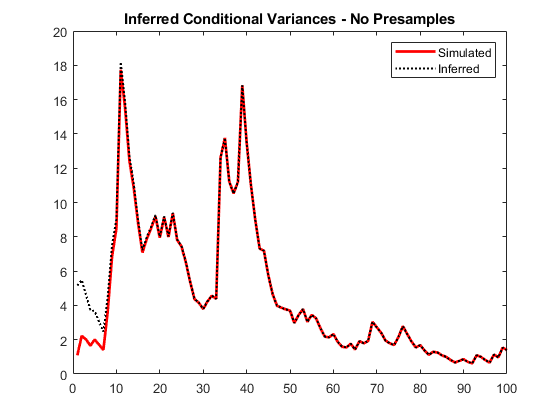
注意由于缺少前采样数据而导致的早期瞬态响应(差异)。
使用预留样本前创新来推断条件方差,y0.将它们与已知(模拟的)条件方差进行比较。
vE =推断(Mdl y“E0”, y0);图绘制(1:10 0 v,“r”,“线宽”, 2)在情节(1:10 0、vE、凯西:”,“线宽”传说,1.5)(“模拟”,“推断”,“位置”,“东北”)标题(推断条件方差-样本E)举行从

在早期阶段,瞬态响应略有降低。
使用预先准备好的条件方差来推断条件方差,签证官.将它们与已知(模拟的)条件方差进行比较。
签证官=推断(Mdl y“半”v0);图绘制(v)情节(1:10 0 v,“r”,“线宽”, 2)在情节(1:10 0,签证官,凯西:”,“线宽”传说,1.5)(“模拟”,“推断”,“位置”,“东北”)标题(推断条件方差-前例V)举行从

在早期阶段,瞬态响应要小得多。
使用前样本创新和条件方差来推断条件方差。将它们与已知(模拟的)条件方差进行比较。
vEO =推断(Mdl y“E0”, y0,“半”v0);图绘制(v)情节(1:10 0 v,“r”,“线宽”, 2)在vEO情节(1:10 0,凯西:”,“线宽”传说,1.5)(“模拟”,“推断”,“位置”,“东北”)标题(“推断条件方差-样本”)举行从

当您使用足够的前样例创新和条件方差时,推断出的条件方差是准确的(没有瞬态响应)。
进行EGARCH拟合比较的似然比检验
推导出符合纳斯达克综合指数收益的EGARCH(1,1)和EGARCH(2,1)模型的对数似然目标函数值。为了确定哪个模型是更节俭,适当的拟合,进行似然比检验。
加载工具箱中包含的纳斯达克数据,并将索引转换为返回值。先把前两个观察结果放在一边,用作样本前数据。
负载Data_EquityIdx纳斯达克= DataTable.NASDAQ;r = price2ret(纳斯达克);r0 = r (1:2);rn = r(3:结束);
对收益拟合EGARCH(1,1)模型,并推断对数似然目标函数值。
Mdl1 = egarch (1,1);EstMdl1 =估计(Mdl1 rn,“E0”、r0);
EGARCH(1,1)条件方差模型(高斯分布):值StandardError TStatistic PValue _________ _____________ __________ __________ Constant -0.13518 0.022134 -6.1074 1.0129e-09 GARCH{1} 0.98386 0.0024268 405.41 0 ARCH{1} 0.19997 0.013993 14.29 2.5182 -46 Leverage{1} -0.060244 0.0056558 -10.652 1.7129e-26
[~, logL1] =推断(EstMdl1 rn,“E0”、r0);
对收益拟合EGARCH(2,1)模型,并推断对数似然目标函数值。
Mdl2 = egarch (2, 1);EstMdl2 =估计(Mdl2 rn,“E0”、r0);
EGARCH(2,1)条件方差模型(高斯分布):Value StandardError TStatistic PValue _________ _____________ __________ __________ Constant -0.1456 0.028436 -5.1202 3.0524e-07 GARCH{1} 0.85307 0.14018 6.0854 1.1618e-09 GARCH{2} 0.12952 0.13838 0.93597 0.34929 ARCH{1} 0.21969 0.029465 7.456 8.9205e-14 Leverage{1} -0.067936 0.01088 -6.2444 4.2552 -10
[~, logL2] =推断(EstMdl2 rn,“E0”、r0);
以更简约的EGARCH(1,1)模型为原模型,EGARCH(2,1)模型为备选模型,进行似然比检验。测试的自由度为1,因为EGARCH(2,1)模型比EGARCH(1,1)模型多一个参数(一个额外的GARCH项)。
(h p) = lratiotest (logL2 logL1 1)
h =逻辑0
p = 0.2256
原假设未被拒绝(h = 0).在0.05显著水平下,EGARCH(1,1)模型不被拒绝,而倾向于EGARCH(2,1)模型。
对GARCH和GJR拟合比较进行似然比检验
GARCH (P,问)模型嵌套在GJR(P,问)模型。因此,您可以执行似然比检验来比较GARCH(P,问)和GJR (P,问)模型。
对符合纳斯达克综合指数收益的GARCH(1,1)和GJR(1,1)模型的对数似然目标函数值进行推断。进行似然比测试,以确定哪个模型是更节俭,更充分的拟合。
加载工具箱中包含的纳斯达克数据,并将索引转换为返回值。先把前两个观察结果放在一边,用作样本前数据。
负载Data_EquityIdx纳斯达克= DataTable.NASDAQ;r = price2ret(纳斯达克);r0 = r (1:2);rn = r(3:结束);
对收益拟合GARCH(1,1)模型,并推断对数似然目标函数值。
Mdl1 = garch (1,1);EstMdl1 =估计(Mdl1 rn,“E0”、r0);
GARCH(1,1)条件方差模型(高斯分布):值StandardError TStatistic PValue _________ _____________ __________ __________ Constant 2.005e-06 5.4298e-07 3.6926 0.00022197 GARCH{1} 0.88333 0.0084536 104.49 0 ARCH{1} 0.10924 0.0076666 14.249 4.5737e-46
[~, logL1] =推断(EstMdl1 rn,“E0”、r0);
对收益拟合GJR(1,1)模型,并推断对数似然目标函数值。
Mdl2 = gjr (1,1);EstMdl2 =估计(Mdl2 rn,“E0”、r0);
GJR(1,1)条件方差模型(高斯分布):值StandardError TStatistic PValue __________ _____________ __________ __________常量GARCH{1} 0.88102 0.0095104 92.637 0 ARCH{1} 0.064015 0.0091849 6.9696 3.1787e-12杠杆{1}0.089297 0.0099211 9.0007 2.2426e-19
[~, logL2] =推断(EstMdl2 rn,“E0”、r0);
采用更简约的GARCH(1,1)模型作为原模型,GJR(1,1)模型作为备选模型,进行似然比检验。测试的自由度为1,因为GJR(1,1)模型比GARCH(1,1)模型多一个参数(杠杆项)。
(h p) = lratiotest (logL2 logL1 1)
h =逻辑1
p = 4.5816平台以及
原假设被拒绝(h = 1).在0.05显著性水平下,拒绝GARCH(1,1)模型,采用GJR(1,1)模型。
输入参数
输出参数
参考文献
[1] Bollerslev, T.“广义自回归条件异方差”。计量经济学杂志》上。1986年第31卷,307-327页。
关于投机性价格和收益率的条件异方差时间序列模型。《经济学与统计评论》.1987年第69卷,第542-547页。
[3] Box, G. E. P. G. M. Jenkins和G. C. Reinsel。时间序列分析:预测与控制.3版。恩格尔伍德悬崖,NJ: Prentice Hall, 1994。
恩德斯[4],W。应用计量经济时间序列.霍博肯:约翰·威利父子公司,1995。
[5] Engle, R. F. <英国通货膨胀方差估计的自回归条件异方差性>。费雪.第50卷,1982年,987-1007页。
[6] Glosten, L. R., R. Jagannathan, D. E. Runkle。“关于期望值与股票名义超额收益波动的关系”。金融杂志.第48卷,第5期,1993年,1779-1801页。
j·D·汉密尔顿时间序列分析.普林斯顿:普林斯顿大学出版社,1994。
你也可以从以下列表中选择一个网站:
