 Cleve's Corner:数学和计算上的Clyver
Cleve's Corner:数学和计算上的Clyver Loren在Matlab的艺术上
Loren在Matlab的艺术上 史蒂夫在图像处理与matlab
史蒂夫在图像处理与matlab Simulin金宝appk上的家伙
Simulin金宝appk上的家伙 深度学习
深度学习 开发人员区
开发人员区 斯图尔特的MATLAB视频
斯图尔特的MATLAB视频 在头条线后面
在头条线后面 本周的文件交换选择
本周的文件交换选择 汉斯在某种程度上
汉斯在某种程度上 赛车休息室
赛车休息室 初创公司,加速器和企业家
初创公司,加速器和企业家 MATLAB社区
MATLAB社区 matlabユーザーコミュニティー
matlabユーザーコミュニティー
步行机器人控制:从PID到强化学习
在一个以前的博客文章,我描述了建模,并以一个高层次的讨论结束,即一旦你建立了一个模型,你将如何实现控制器。
在这篇文章中,我们将深入研究控制的细节。我们将描述可以控制人形机器人的不同方式,以及何时何地你应该使用不同的策略。虽然概念扩展到许多类型的系统,我们将集中在两足类人机器人的运动为我们的例子。
基于模型的方法 - 控制设计
控制工程是一个非常成熟的领域,其技术已成功应用于许多双足机器人。一些最著名的包括本田的ASIMO(最近在2018年退休)和波士顿动力公司阿特拉斯。
与大多数控制设计方法一样,创建一个成功的控制器的核心是一个数学模型。一个模型通常有冲突的需求,因为它必须是
- 简单到足以应用众所周知的控制设计技术,如PID, LQR,和MPC。
- 复杂地足以现实地近似真正的机器人行为,使控制器在实践中工作。
通过这些信息,维护简单并不罕见低保真型号用于控制器设计和复杂高保真模型用于仿真和测试。
用于腿机器人的常见低保性模型是线性倒立摆模型(Lipm),由诸如Tomomichi Sugihara博士的领域中广泛使用。看到他的出版物之一。
对于一个有腿的机器人,如着名Raibert Hopper.,重要的是建模接触阶段(当脚在地面上,并假定是固定的)和飞行阶段(当脚离开地面)。对于多足机器人,如两足机器人,一种方法是假设机器人总是有一只脚在地面上,因此系统总是被建模为LIPM。与之形成对比的是更动态的行为,比如跑步,你可能会有双脚离开地面的阶段——这导致更快的运动,但更复杂的控制。现在我们假设总是有一只脚在接触。
要了解有关Lipm方法的更多信息,请观看我们的人形行走模型控制视频。
要知道的另一个重要概念是零时刻点(ZMP)。这被定义为引起的时刻由于重力而平衡的瞬间平衡了由于与地面接触而平衡的时刻,从而使摆动系统稳定。
控制步行机器人使其稳定的一种典型方法是确保ZMP在金宝app支持多边形机器人的,也就是说,质心在一个范围内使机器人静态稳定。只要机器人在支撑多边形内行走,其行走运动理论上是稳定的。金宝app我说“理论上”是因为,记住,真正的机器人并不是一个线性倒立摆,所以设置一个安全系数总是一个好主意!
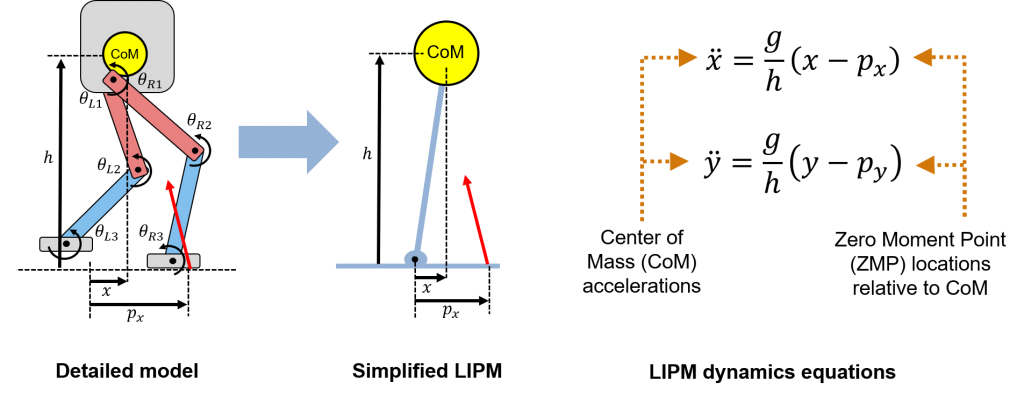
最后,该相同的线性模型可以与模型预测控制(MPC)一起使用,以产生物理上一致的行走模式。这是由舒吉博士议员展示的这个出版物。我也喜欢这篇博客作为Lipm在腿部机器人控制中发挥作用的概要。
当然,控制脚相对于质心的位置只是完整系统的一部分。一旦建立了行走模式,仍有其他较低级别的控制问题可以解决,以使机器人遵循这种模式。这包括将目标脚动转换为目标致动器运动(逆运动学),控制致动器本身,稳定和鲁棒性与扰动等等。您可以在下面看到一些典型组件的图表。
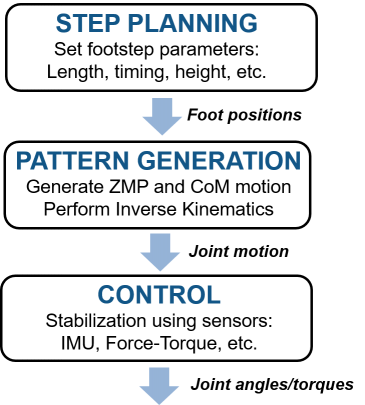
此时,您可能需要考虑使用高保真模拟来测试算法,因为LIPM模型不足以测试所有这些低级控制组件。
你可以学习更多的控制双足类人机器人使用MATLAB和Simulink通过观看我们的金宝app行走机器人图案生成视频。
无模型方法-机器学习
机器学习算法和计算能力的急剧增加(这两个是相关的)开启了一整个研究领域,专门用于让计算机学习如何控制物理系统 - 而这种物理系统通常是一个机器人,如在着名的谷歌深度出版物富裕环境中运动行为的出现。
在这种情况下,“控制器”是指我们想要分配给控制我们机器人的软件的任何数值结构。从技术上讲,你可以使用机器学习来参数化简单的东西,如PID控制器;然而,这些模型结构受到它们的线性行为和接受简单数字数据的能力的限制,因此您不会从机器学习中获得太多 - 事实上,我只需称之为“优化”。控制控制机器的真正力量来自深神经网络,它可以近似极端非线性的行为,并处理更复杂的输入和输出数据。
应用于控制的深度神经网络可能需要两种口味:
- 监督学习 -使用现有数据集进行培训,其目标是概括为新情况。例如,我们可以从附加到运动捕获系统的行走人员,远程控制机器人的专家或基于模型的控制器中的专家收集数据。然后,监督学习可用于参数化神经网络。
- 强化学习- 通过经验或试验和错误学习参数化神经网络。与监督学习不同,这不需要收集任何数据先验,它以培训为代价,随着加强学习算法探讨(通常)庞大的参数搜索空间。
当然,总有可能将这两种方法结合起来。例如,可以使用现有的控制策略来收集初始数据集,该数据集引导强化学习问题——这通常被称为模仿学习。这提供了“不从零开始”的明显好处,这大大缩短了训练时间,并且产生合理结果的可能性更大,因为理想地证明初始条件在某种程度上已经起作用了。
您可以通过观看我们的方式了解更多关于使用MATLAB和SIMULINK的信息金宝app行走机器人的深度强化学习视频。
更一般地,采用机器学习的利弊控制机器人系统。
好处:
- 机器学习可以实现端到端工作流,直接使用复杂的传感器数据,如图像和点云。相比之下,传统的控制方法需要首先处理这些数据——例如,创建一个可以识别感兴趣的位置的对象检测器。
- 可以学习复杂的非线性行为,这将是困难的,甚至是不可能的,以传统的控制设计方法实现。
- 通常,设计控制器的人需要较少的领域专业知识。
缺点:
- 机器学习方法容易受到特定问题的“过度装箱”,这意味着结果不一定会引向其他任务。当您使用模拟来训练控制器时,这是特别困难的,因为控制器可以利用真实机器人中不存在的模拟伪像。这个问题很常见,所以它被给出了这个名字SIM2REAL.。
- 机器学习还有另一个臭名昭著的“可解释性”挑战——换句话说,一旦一个控制器使用你最喜欢的机器学习技术进行了训练,我们如何解释学习到的行为并将其应用于其他问题?
- 一般来说,控制器设计人员需要更少的领域专业知识(是的,这是一个有利和不利的方面)。
结合控制和机器学习
关键的外卖是基于机器的基于机器的控制方法具有很大的潜力,但是已经有多年的研究和成功实施了基于模型的控制器,这些控制器使用了很好的地理知识,这些控制器对行走机器人动态进行了很好的身体知识......而且我们将被遗弃抛弃所有这些信息!
重要的是,机器学习和传统控制可以(并且应该!)组合。例如,拍下下图
- 使用机器学习将数字数据和感知传感器(例如颜色和深度图像,LIDAR等)的组合转换为机器人的“良好”运动计划和操作模式。
- 采用基于模型的控制技术来定位机器人的脚,将其转换为接头角度,并控制各个执行器以执行此动作。安全关键因素如稳定性也将完全独立于培训的代理人可以决定。
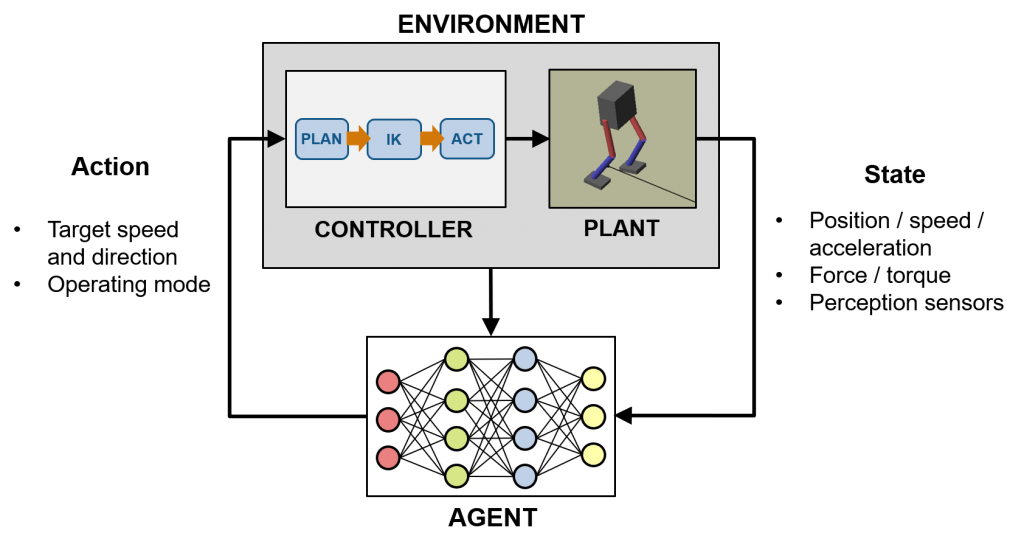
上面只是一个例子,您应该随意探索在可解释的分析算法与“黑匣子”学习策略中绘制解释,分析算法与特定问题的“黑匣子”策略之间的分区。两者的仔细考虑结合可以导致强大而复杂的自主行为,可以超出培训环境和平台,并提供一些对可能需要安全至关重要的行为的保证。
我们希望你喜欢阅读这篇文章,我们期待你的评论和讨论。


也可以看看
-

使用强化学习演奏乒乓球
博客
-
-




注释
要发表评论,请点击这里登录您的MathWorks帐户或创建新的。