 克利夫的角落:克里夫·莫勒尔对数学和计算机
克利夫的角落:克里夫·莫勒尔对数学和计算机 在MATLAB的艺术洛伦
在MATLAB的艺术洛伦 史蒂夫图像处理与MATLAB
史蒂夫图像处理与MATLAB 人在仿真软件金宝app
人在仿真软件金宝app 深度学习
深度学习 开发区域
开发区域 斯图尔特的MATLAB视频
斯图尔特的MATLAB视频 新闻标题背后
新闻标题背后 文件本周交易所选择
文件本周交易所选择 汉斯在物联网
汉斯在物联网 车队休息室
车队休息室 MATLAB社区
MATLAB社区 MATLABユーザーコミュニティー
MATLABユーザーコミュニティー
使用机器学习和音频工具箱建立一个实时音频插件
本周的博客文章是的2019年金奖得主音频工程学会MATLAB插件学生大赛。
介绍
我的名字是基督教斯坦梅茨我目前Pompeu Fabra大学硕士研究生学习的声音和音乐计算。我有经验,既作为音频工程师,努力录制,混音,掌握音乐,以及一研究员,建立新的工具音乐创作者和音频工程师。我在信号处理和机器学习的应用感兴趣的是对音乐制作领域的问题。我会在这里分享的项目,flowEQ,是我在使用机器学习的最新尝试,以使现有的音频信号处理工具时,参量均衡,更容易使用。
竞争
这个项目是我在进入音频工程学会MATLAB插件学生大赛。我提出这个工作在147 AES大会在纽约市,以及其他来自世界各地的学生(所有的参赛作品都可以找到)在这里),我的项目获得了金奖。
本次比赛的目标是使用音频工具箱构建一个实时音频插件,可以帮助音频工程师实现一些新的东西。音频工具箱是独一无二的,因为它可以让你写MATLAB代码,定义要如何自动处理音频,然后将其编译成一个VST / AU插件,可以在大多数的数字音频工作站(DAW系统)一起使用。这使得它相当简单构建插件,然后我们就可以更专注于算法的开发。
flowEQ
的目标flowEQ是提供一个高层次接口到一个传统的五个波段参数均衡器,可以简化施加音色处理的过程中(即,如何改变的记录的声音)为新用户使用。为了有效地利用该参数均衡器,音频工程师必须有增益,中心频率,和Q控制的一个亲密的理解,以及频带如何多个可以串联使用,以达到期望的音色调整。对于业余音频工程师或音乐家,这往往呈现太多的复杂性,并flowEQ旨在通过提供对这些类型的用户面向智能接口来解决这个问题。此外,该接口可以提供经验丰富的工程师很快跨越多个音色配置文件搜索的新方法,也有解锁新的创意效果的可能性。
为达到这个,flowEQ使用解缠结变自动编码器(β-VAE),以构建均衡器的参数空间的一个低维表示。通过遍历解码器网络的这个教训潜在空间,用户可以通过一个五个波段参数均衡的配置更快速地搜索。这种方法旨在促进利用一个人的耳朵上看着传递函数或特定的频率控制,以确定合适的均衡器设置。
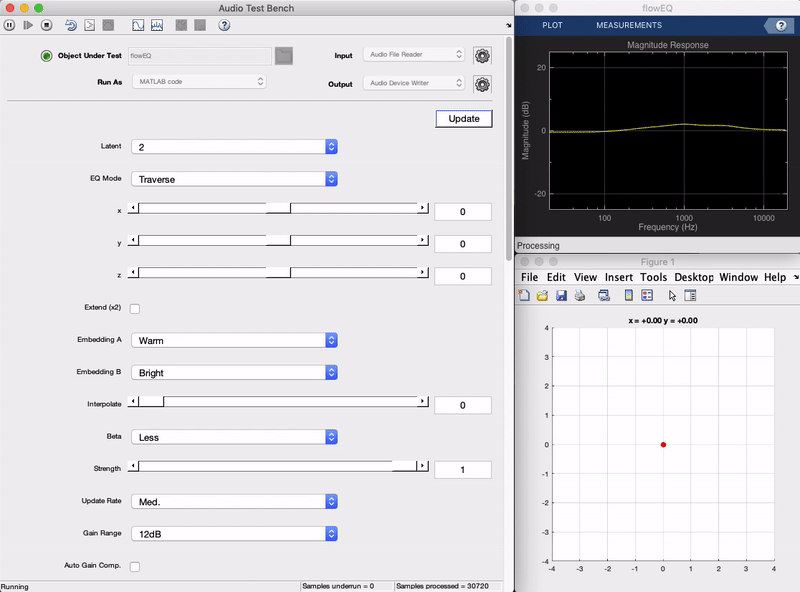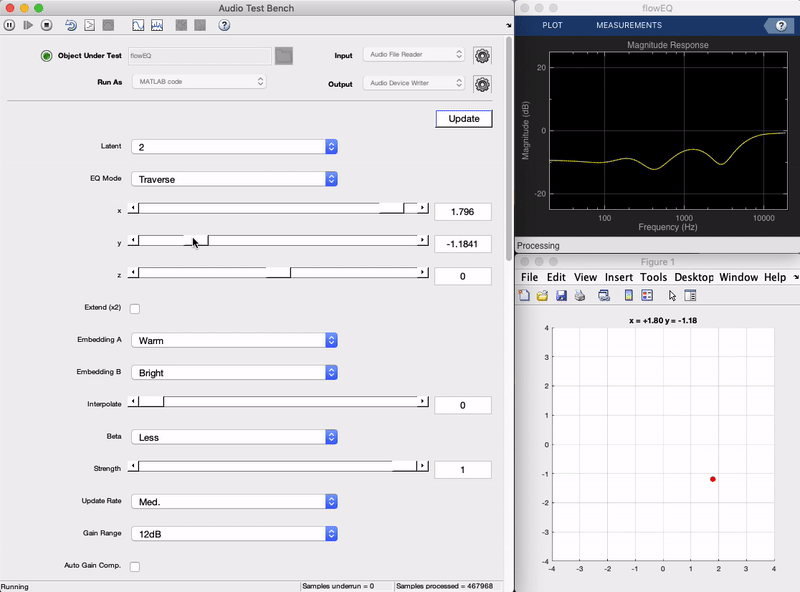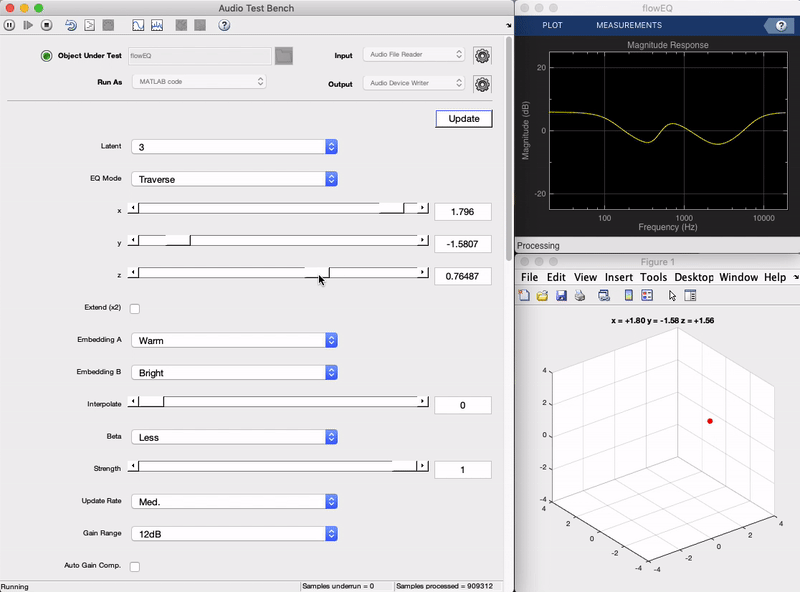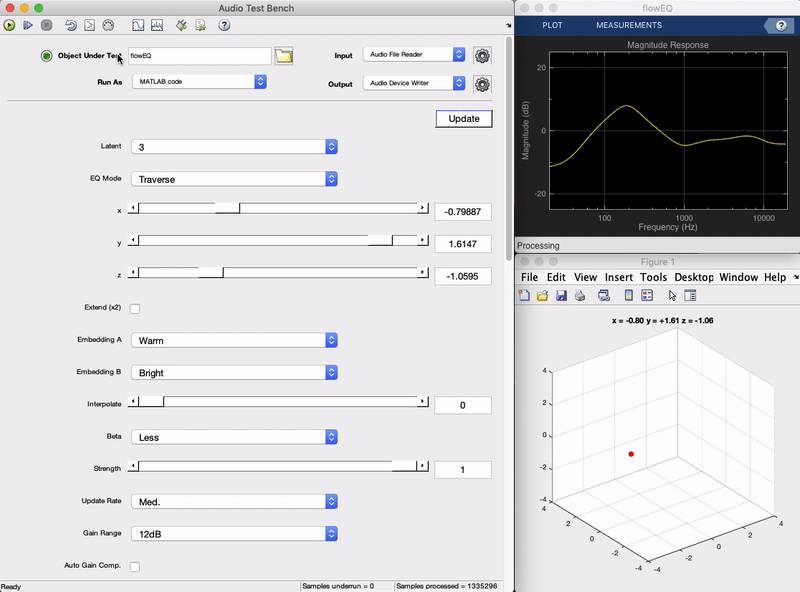
插件演示
下面是最终的操作插件的演示。可以看到作为左侧的滑块移动时,在以平滑的方式右上方变化示出的均衡器的频率响应。每五个条带(系列五个二阶滤波器)的产生的总频率调整,和什么一次将需要在同一时间,以达到改变13个参数,现在可以通过调整两个滑块(在2维模式)来实现。在下面的章节中,我们将进入细节的背后是如何工作从一个高的水平,以及它是如何实现的。(听到这听起来像检查出短现场演示的插件视频。)
细节
数据集
要培养任何一种模式,我们需要的数据。对于这个项目,我们使用SAFE-DB均衡数据集,其特点是从五段均衡使用真实音频工程师设置的集合,每个设置语义描述符一起。在数据集中的每个样本包含均衡器的配置(适用于13个参数设置)以及一个语义描述符(例如温暖,明亮,尖等)。
在我们的公式中,我们实现了均衡器的参数空间非常大(如果我们说每个参数可以取20个不同的值,那将给我们~4e15可能的配置,比细胞数量在人体内。)然后,我们做的是,在数据集中的样本表示该参数的空间,是最有可能的,而音频工程师正在处理音乐信号被利用的部分假设。然后,我们的目标是建立学习本空间的结构良好,低维结构,所以我们可以从它样开模。
模型
为了实现这一目标,我们使用变自动编码器。对于一个很好的介绍话题我推荐这个YouTube的视频来自Arxiv insight频道。自动编码器是一种独特的公式,学习有关的数据分布在一个无监督的方式。这是通过在输入通过瓶颈(因此模型不能简单地将输入传递到输出)之后,强制模型重构它自己的输入来实现的。变分自动编码器扩展了一般的自动编码器配方,为我们的用例提供了一些良好的特性。在这里,我将简要概述我们如何使用这个模型来构建插件的核心。
在训练期间,我们的模型学会使原始输入通过低维瓶颈(1,2,或3维)之后重构均衡器的13个参数。我们测量输出和输入(重建损耗)之间的误差,然后更新编码器和解码器的权重减小此误差为当前的例子。
虽然这可能看起来不是一个有用的任务,我们发现,如果我们使用该模型,它接受作为输入的低维向量的解码器部分,我们可以使用非常只有少数旋钮重建宽范围均衡器曲线的(1,2,或3取决于潜在空间的维数)。下面的图说明此操作。这里,我们已经丢弃从2维平面上的编码器和采样点和饲料这些点到解码器。然后,解码器试图重建完整的13个参数。此低维潜在空间提供了一种简便的方式穿过的可能均衡器参数的空间中进行搜索。

解码器操作
到更多的灵活性和实验与潜在空间的复杂性提供给用户,我们培养具有不同潜在空间维度(1,2和3)的模型。在插件中,用户将能够在这些之中选择,这将改变需要为了控制整个均衡器将被改变滑块的数量。例如,在一维情况下,用户仅需要移动一个单一的滑座,以控制均衡器。
我们通过引入进一步扩展此解缠结变自动编码器(β-VAE),这使得一个轻微修改的损失函数(参见纸了解详细信息)。最重要的一点是这为我们提供了一个新的超参数,β,而我们正在训练改变什么样的代表性模式将学习修改。因此,我们列车共有12款车型,都在β和不同的潜在空间维度的不同值。然后,我们提供这些车型的插件,用户可以选择之中,并通过听来评价。

现在我们了解了从高层次的模型中,我们将简要介绍一下一些实施细节。该编码器和解码器均具有只是一个单一的完全连接隐藏1024个单元和RELU激活层。中央瓶颈层具有任一,1,2,或3个隐藏单元具有线性活化。解码器的最终输出层是具有13个单元的完全连接层和一个S形的激活函数(所有输入已0和1之间归一化)。这使得一个非常小的模型(约30K参数),但由于非线性我们可以学习强大的映射(比更强大PCA,例如)。一个小模型是,我们可以更快地训练它不错,但还推断时间要快得多。甲直传通过解码器网络呈现CPU只有约300微秒秒。

网络架构
该模型实施和训练有素Keras框架,你可以看到所有的代码与在最终的权重一起训练模型培养的目录GitHub库。这些模型在MATLAB后来实现,因此他们可能被包含在该插件。见我们如何实现了以下详细说明的挑战部分。
插件
该插件可以被分成两个主要部分:过滤器和训练解码器。我们实现一个基本五个波段参数均衡器,它是由放置在五个系列双二阶滤波器(这反映了均衡器在建立原始训练数据的过程中使用的建筑)。最低及最高频段为滤除滤波器,中心三条带峰值过滤器。有关过滤器实现更多详情请参阅经典音频EQ食谱。架式滤波器有两个控件:增益和截止频率,而峰值过滤器有三种:增益,截止频率,并问:这些控件组成均衡的13个参数。我们使用这些参数和上述过滤器公式的值时,他们被改变计算系数为所有的过滤器,然后使用基本过滤在MATLAB函数的过滤器应用于音频块。
现在,我们在MATLAB中执行的解码器,其输出连接到均衡器的控制。当用户移动的X,Y,Z潜在空间滑块,这些值通过解码器传递到生成相应的均衡器参数,以及新的过滤器系数被计算出来。操作方式有两种主要模式:特拉弗斯和语义。
该特拉弗斯模式允许用户自由地研究模型的潜在空间。在这种模式下三个X,Y,Z滑块可以用于遍历解码器的潜在空间。每个潜在矢量解码为一组在五个频带均衡器的13个参数值。
该语义模式允许从潜在空间采样的不同的方法。在x,y和z滑块被去激活,并且嵌入的一个和嵌入乙组合框被使用,与内插滑块沿。训练结束后,语义标签用于潜在空间内确定相关的集群。这些集群代表其与某些语义描述符相关联的潜在空间的区域。所述内插控制允许用户在潜在空间两个语义描述符之间无缝移动。

插件框图
上面的框图提供了到目前为止我们所提到的所有元素的概述。顶部部分显示带有五个级联biquad滤波器的音频信号处理路径。中心部分显示解码器,解码器的输出连接到滤波器的参数。在底部,我们看到用户可以从插件界面调整的控件(详细如下所示)。调谐参数从12个不同的训练解码器模型中选择,而不考虑模式和参数特拉弗斯和语义模式被示出为好。在手册模式在界面的底部中示出的最初的13个参数有效,以控制均衡器,而不是使用的解码器。

完整的插件接口
评估
这种性质的模型的评估是具有挑战性的,因为我们没有一个“好”的潜表示的客观度量。请记住,我们的目标是不是一定要建立一个模型,可以完美地重建任何一组参数,而是有一个很好的结构潜表示,允许用户搜索的空间迅速找到他们正在寻找的声音。因此,我们的评估的第一项措施是通过目测检查潜在空间的歧管。我们将做到这一点的二维模型,因为这是可视化的最好的。

二维潜在空间流形
在这里,我们示出了频率响应曲线(与y轴为增益在-20dB至20dB和x轴从20赫兹到20千赫兹的频率),用于在二维潜在空间的每个点从-2到2中均x和y的尺寸,这为我们提供了这方面的例子格。我们在所有β的,我们一起训练的价值观我们的每一个二维模型的做到这一点。这将让我们看到β的效果以及每个模型的潜在空间的结构。
我们观察到,随着β增加,潜在空间变得更加规范化,并为其中β= 0.020,很多点的出现解码相同的均衡器传递函数,我们不希望这种行为的情况。这是可能被视为过正规化的例子。因此,使用β= 0.001的模型,可能是最好的选择,因为它表现出最大多样性,同时保持一致和光滑结构。这意味着,整个空间内的用户搜索,将有一些解释变化的声音,并在某种程度上,是不是太突然变化。总之,使用较大的β动力的值的模型结构的单位高斯形状的潜在空间,并因此失去其表现力。
评估这些不同模型的最佳方法是进行用户研究,其中音频工程师被盲目地给予不同的模型,并要求达到一定的目标。用户最快找到他们想要的目标的模型就是最好的模型。出于这个原因,我们在插件中包含了所有的12个模型,希望我们能得到用户关于哪个模型工作得最好的反馈。
挑战
一个与实现在内的音频软件(例如,音频插件或嵌入式软件)常用开源框架(例如Keras)开发的深学习模型的当前的挑战是缺乏的自动化方法的这些网络传送到C或C ++。MATLAB提供了一个自动化的方法来构建并运行我们与Keras模型importKerasNetwork从功能深度学习工具箱。这将在Keras训练后,装载HDF5模型权重和体系结构和实现模型作为DAGNetwork宾语。不幸的是,这些对象目前不支持自动生成的通用C ++代码(尽管其它类型的从深度学习工具箱网络金宝app体系结构和层可生成优化的CUDA和C代码在GPU上,ARM,或英特尔核心上运行)。对于我们的音效插件,我们最终需要的目标无关的C ++代码,跨操作系统在不同的CPU为目标运行。
为了解决这个问题,我们实现纯MATLAB代码自己的网络。这是非常简单的,因为我们的网络是比较小的。我们先转换。H5从Keras所保存的权重文件。垫文件,然后加载这些权重矩阵(W1和W2用于解码器隐藏层和输出层)。预测函数被示出的下方,并与输入潜变量组成只是几个矩阵运算ž和层的重量,加上激活功能。要看到模型的整个实施见解码器课堂上,我们构建的。
功能y_hat =预测(OBJ,z)的%需要潜矢量z与适当的维数%输出是归一化(0到1)的均衡器参数的13X1矢量。z1 = (z * obj.W1) + obj.b1;a1 = obj.ReLU (z1);z2 = (a1 * obj.W2) + obj.b2;a2 = obj.sigmoid (z2);y_hat = a2;结束
顺便说一句,我也碰到过MathWorks公司内部开发的工具,它能够自动生成类似于上面从高层次深网络对象的片段低级别的MATLAB代码。对于这个项目,这将进一步简化,从训练的Keras模型的插件实现的过渡。据我所知,工具目前不与任何官方MATLAB附加产品发布,但你可能要接触到MathWorks公司,如果你有兴趣。
在实时音频插件实现深度学习模式仍然相对未知的领域。我们仍然没有与最小的摩擦实现这一明确的方法,无论使用什么框架。实时音频应用还规定了严格的运行时间限制,这意味着我们深模型必须足够快,以免引起中断的音频流,或者发声滞后较差的用户体验在用户更改参数。
未来发展方向
flowEQ在很大程度上仍然是一个概念的证明,目前的实现在一定程度上受到MATLAB框架的限制。下面是进一步改进插件和扩展其功能的一些未来开发领域。
- 元参数潜在空间均衡器链接到手动的均衡器控制
- 自适应潜在空间(即有条件的VAE)空调上的音频内容
- 查找/收集与语义描述符更多的数据以扩大潜在空间的多样性
- 进一步hyperparameter优化确定培训时间,β,网络体系结构等。
资源
- 关于该项目的全部细节,包括变自动编码的详细介绍见项目网站。
- 阅读所有的代码GitHub库(MATLAB +的Python)。
- YouTube上的其他视频包括五分钟的概述和一个现场演示的插件。
- 从在AES大会给我的谈话幻灯片可以发现在这里。
- 如果你想建立自己的插件中,音频插件例如画廊是个好地方得到一些启示。
如果你发现这个项目感兴趣的按照我的Twitter @csteinmetz1关于我的最新项目,也结帐我已经与MATLAB +深度学习+音频,在工作的其他项目一样的更新NeuralReverberator而合成使用卷积的自动编码新的混响效果。


也可以看看
-

神经网络的可视化功能
博客
-

呜呜祖拉降噪与参量均衡器
博客
-

机器学习来救援!
博客
-





评论
要发表评论,请点击在这里在您的帐户MathWorks公司签署或创建一个新的。