{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
本文介绍了您可以使用的技术来加速MATLAB®算法和应用程序。涵盖的主题包括:
评估代码性能
采用高效的串行编程实践
使用系统对象
在多核处理器和GPU上执行并行计算
生成C代码
每个部分都侧重于特定技术,描述了底层加速技术,并在最适用时解释。您的编程专业知识,您希望加速的算法类型以及您所提供的硬件可以帮助指导您的选择选择1。
评估代码性能
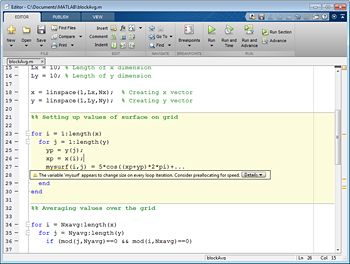
在修改代码之前,您需要确定将您的努力集成的位置。支持此过程的两个关键工具是代码分析仪和Mat金宝applab Profiler。MATLAB编辑器中的代码分析器检查您的代码是否在写作时。代码分析仪识别潜在的问题,并建议修改以最大化性能和可维护性(图1)。代码分析器报告可以在整个文件夹上运行,使您可以查看单个文档中一组文件的所有代码分析仪建议。
Profiler显示您的代码在哪里度过它的时间。它提供了一份报告总结了代码执行,包括调用所有函数的列表,调用每个函数的次数,以及每个函数内所花费的总时间(图2)。Profiler还提供有关每个功能的时序信息,例如哪条代码线使用最多的处理时间。
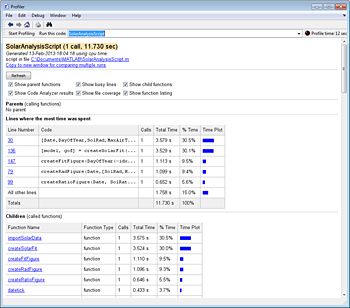
一旦确定了瓶颈,您就可以专注于改善这些特定代码部分性能的方法。当您实现加速算法的优化和技术时,Profiler可以帮助您衡量改进。
采用高效的串行编程实践
在考虑并行计算,代码生成或其他方法之前,它通常是优化序列代码的序列代码。两个有效的编程技术加速您的MATLAB代码是预先分配和矢量化。
使用preLocation,使用该数组所需的最终大小初始化数组。预架分配可帮助您避免动态调整阵列,特别是当代码包含时为了和尽管循环。由于MATLAB中的数组被保持在连续的内存块中,因此反复调整大小阵列通常需要MATLAB来花时间寻找更大的邻接内存块,然后将数组移动到这些块中。通过预分配数组,您可以避免这些不必要的内存操作并提高整体执行时间。
矢量化是将代码转换为使用矩阵和矢量操作转换代码的过程。Matlab使用处理器优化的库进行矩阵和矢量计算。因此,您通常可以通过将代码传染措施来提高性能。
使用较大阵列的矢量化Matlab计算可能是使用GPU加速的好候选者。在其中的情况下为了-loops无法矢量化,您通常可以使用并行为了-环形 (议案)或C代码生成,以加速算法。有关这些技术的更多详细信息,请参阅并行计算和生成C代码的部分。
您可以使用系统对象™在很大程度上在信号处理和通信领域加速MATLAB代码。系统对象是系统工具箱中可用的MATLAB面向对象实现的算法,包括通信系统工具箱™和DSP系统工具箱™。通过使用System对象,将声明(系统对象创建)从系统对象中的算法执行解耦(系统对象创建)。这种解耦导致基于循环的循环的计算,因为它允许您执行一次参数处理和初始化。您可以在循环之外创建和配置系统对象的实例,然后调用循环中的步骤方法以执行它。
DSP系统工具箱和通信系统工具箱中的大多数系统对象都以MATLAB可执行文件实现(MEX文件)。此实现可以加速模拟,因为许多算法优化包含在对象的MEX实现中。有关MAX-Files的更多详细信息,请参阅MATLAB生成C代码的部分。
执行并行计算
到目前为止所描述的技术专注于优化串行MATLAB代码的方法。您还可以通过使用额外的计算能力来获得性能改进。MATLAB并行计算产品提供计算技术,让您利用多核处下载188bet金宝搏理器,计算机集群和GPU。
使用Matlab Workers在多核处理器和集群上
并行计算工具箱™允许您在台式电机上运行多个MATLAB工人(MATLAB计算引擎)。您可以通过划分这些工人的计算来加速您的应用程序。这种方法使您可以更好地控制并行性,而不是在MATLAB中找到的内置多线程。它通常用于粗糙粒度的问题,例如参数扫描和蒙特卡罗模拟。有关使用MATLABPRILLART服务器的更大加速,使用MATLAB工人使用MATLAB工人的并行应用程序可以缩放到计算机群集或云™。
几个工具箱,包括优化工具箱™和统计和机器学习工具箱™,提供可以利用多工作方行行的算法来加速您的计算2。在大多数情况下,您可以通过简单地打开一个选项来使用并行算法。例如,运行粉刺在“并行”的优化工具箱中,您将“始终”设置为“useparallel”选项。
并行计算工具箱提供高级编程构造,例如议案。使用议案你可以加速为了- 通过划分循环迭代来在多个MATLAB工人划分的循环迭代中划分MATLAB代码(图3)。

使用议案,循环迭代必须是独立的,没有迭代依赖于任何其他。为了加速依赖或基于状态的循环,您可以重新排序计算,以便循环变为秩序无关。或者,您可以并行化包含该的外环为了-环形。如果这些选项不可行,可以优化身体为了- 播充或考虑生成C代码。
通过在客户端和Matlab工人之间传输数据议案循环,您会产生沟通成本。这意味着使用可能没有有利议案当您只有少数简单计算时。如果是这种情况,请重点关注并行化外部为了-loop包含更简单的为了-环形。
这批命令可用于在Matlab Workers跨Matlab工人分发独立计算集,以便脱机处理作为批处理作业。当这些计算需要很长时间运行时,这种方法特别有用,并且您需要释放桌面MATLAB以进行其他工作。
使用GPU.
最初用于加速图形渲染,图形进度单位(GPU)也可以应用于信号处理,计算金融,能源生产和其他领域的科学计算。
您可以直接从MATLAB执行NVIDIA GPU上的计算。FFT,IFFT和线性代数操作是可以直接在GPU上直接执行的100多个内置MATLAB函数中的100多个内置MATLAB函数中。这些重载的功能在GPU或CPU上运行,具体取决于传递给它们的参数的数据类型。当给定GPUArray的输入参数时(并行计算工具箱提供的特殊数组类型),这些函数将在GPU上自动运行(图4)。几个工具箱,包括通信系统工具箱和信号处理工具箱™,还提供GPU加速算法。

两项拇指规则将确保您的计算密集型问题适合GPU。首先,当所有核心都忙碌时,您将看到GPU上的最佳性能,利用GPU的固有并行性质。使用在较大的数组上使用矢量化MATLAB计算的代码和支持GPU的工具箱功能适合此类别。其次,应用程序在GPU上运行所需的时间应显着超过在应用程序执行期间在CPU和GPU之间传输数据所需的时间。
为了更高级使用GPU,如果您熟悉CUDA编程,您可以直接从MATLAB运行基于CUDA的GPU内核。然后,您可以使用MATLAB中的数据分析和可视化功能,同时更直接控制GPU算法。
了解更多信息议案和批那在多核和多处理器机器上运行matlab那GPU与MATLAB计算, 和工具箱与内置并行和支持GPU的算法。
从MATLAB代码生成C代码
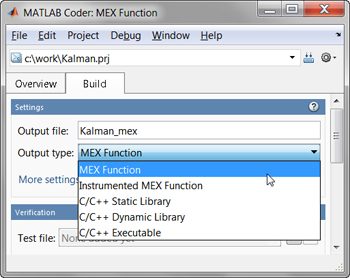
用自动生成的MATLAB可执行文件(MEX-函数)替换MATLAB代码的部分可能会产生加速。使用MATLAB编码器™,您可以生成可读和便携式的C代码并将其编译成MEX函数,替换MATLAB算法的等效部分(图5)。您还可以通过生成MEX函数来利用多核处理器议案结构体。
所实现的加速量取决于算法的性质。确定加速度的最佳方法是使用MATLAB编码器生成MEX函数,并测试加速第一手。如果您的算法包含单精度数据类型,定点数据类型,带有状态的循环,或者无法向矢量化的代码,您可能会看到加速。另一方面,如果您的算法包含MATLAB隐式多线程计算,例如FFT.和SVD.,调用IPP或BLAS库的功能,在PC上的MATLAB上进行优化的功能,或者可以将代码矢量化的算法,加速度不太可能。尝试matlab编码器,遵循最佳实践对于C代码生成,并咨询MathWorks技术专家来找到通过这种方法加速算法的最佳方法。
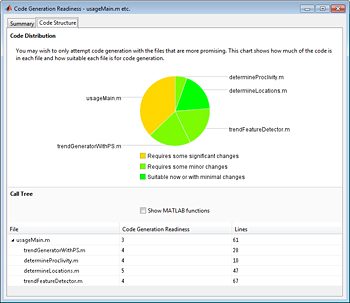
大部分Matlab语言和几个工具箱支持代码生成。金宝appMATLAB编码器提供自动化工具,以帮助您评估算法的代码生成准备情况,并指导您完成C代码生成的步骤(图6)。
学习更多关于从MATLAB到C代码以及如何Matlab编码器很快就开始了。
可能的性能收益
您可以通过编写高效算法,并行处理和代码生成来加速MATLAB应用程序。每种方法都有一系列可能的加速度,具体取决于您正在使用的问题和硬件。这里列出的基准和加速示例概述了可能的加速度。
学习更多关于性能获得使用议案那不同类型的支持GPU功能金宝app那内置GPU支持系统对象金宝app, 和C代码生成。