cusumtest
结构变化的测验
语法
描述
Cusum测试评估系数的稳定性β在多元线性回归模型的形式y=Xβ+ε.推理是基于从数据的嵌套子样本迭代计算的递归残差(标准化的超前一步预测误差)的和序列或平方和。在系数恒定的原假设下,序列值超出预期范围表明模型随时间的结构变化。
h= cusumtest (资源描述)资源描述.回归中的响应变量是最后一个表变量,所有其他变量都是预测变量。要为回归选择不同的响应变量,请使用ResponseVariable名称-值参数。要选择不同的预测变量,请使用PredictorNames名称-值参数。
例子
对结构变化进行Cusum测试
进行习惯测试,以评估粮食需求方程式中是否存在结构性断裂。以矩阵形式输入预测级数,以向量形式输入响应级数。
加载美国食品消费数据集Data_Consumption.mat其中包含1927年至1962年的年度测量数据,由于第二次世界大战,矩阵中缺少数据数据.
负载Data_Consumption
假设你想建立一个由食品价格和可支配收入决定的消费模型,并通过战争带来的经济冲击来评估其稳定性。
画出级数。
P =数据(:,1);食品价格指数I = Data(:,2);可支配收入指数Q =数据(:,3);食品消费指数图;plot(日期,[P I Q])轴紧网格在包含(“年”) ylabel (“指数”)传说([“价格”“收入”“消费”),位置=“东南”)
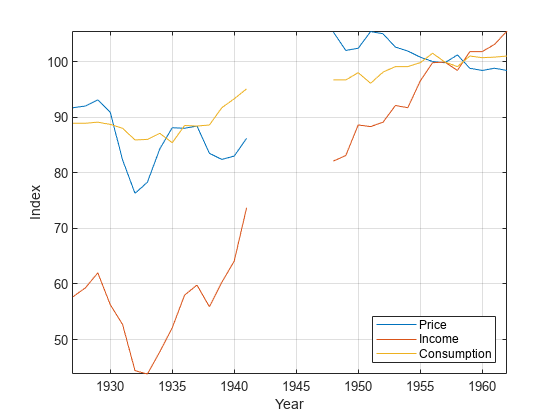
从1942年到1947年的测量数据缺失,这与二战相对应。
通过应用对数变换来稳定每个系列。
LP = log(P);LI = log(I);LQ = log(Q);
假设对数消费是食品价格和收入对数的线性函数。
是一个均值为0,标准差为0的高斯随机变量 .
确定二战前的指数。将消费与食品价格和收入进行对比。
preWarIdx =(日期<= 1941);李图scatter3 (LP (preWarIdx), (preWarIdx)、江西(preWarIdx), [],“罗”);持有在scatter3 (LP (~ preWarIdx),李(~ preWarIdx)、江西(~ preWarIdx), [],“b *”);传奇([“战前的观察”“战后的观察”),...位置=“最佳”)包含(“日志价格”) ylabel (“日志收入”) zlabel (“日志消费”)%获得更好的视野H = gca;h. camerposition = [4.3 -12.2 5.3];
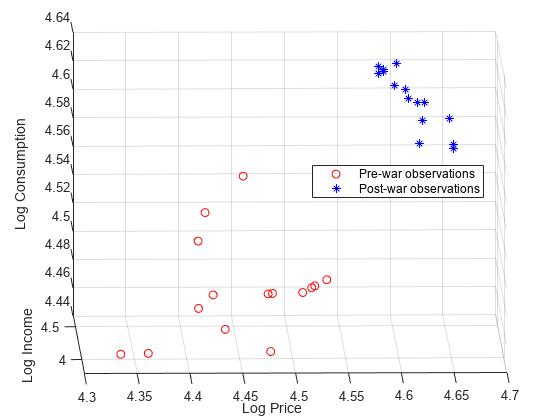
数据关系似乎受到了战争的影响。
进行习惯测试,以评估是否有重大的结构变化。使用默认值。
X = [lp li];y = LQ;h = cusumtest(X,y)
h =逻辑0
H = 0表明没有足够的证据来拒绝原假设,即子样本之间的系数是相等的。
对表变量进行结构变化的Cusum检验
进行习惯测试,以评估食品需求方程中是否存在结构性变化,其中时间序列是表格中的变量。
加载美国食品消费数据集Data_Consumption.mat其中包含1927年至1962年的年度测量数据,由于第二次世界大战,表格中缺少数据数据表.将表转换为时间表,并删除包含缺失值的行。
负载Data_ConsumptionDates = datetime(Dates,12,31);TT = table2时间表(数据表,RowTimes=日期);TT。Row = [];TT = rmmissing(TT);
对表中的所有变量应用日志转换。
LogTT = varfun(@log,TT);LogTT.Properties.VariableNames
ans =1 x3单元格{'log_P'} {'log_I'} {'log_Q'}
进行习惯检验,以评估原木食物消费的回归模型是否存在结构性变化log_Q原木价格log_P并记录收入log_I.
h = cusumtest(LogTT)
h =逻辑0
默认情况下,chowtest选择最后一个表变量作为响应,并选择所有其他变量作为预测器。属性可以选择不同的变量ResponseVariable参数的名称-值参数,并且可以使用PredictorVariables名称-值参数。
返回测试决策统计数据
加载美国食品消费数据集Data_Consumption.mat.考虑一个由对数食品价格和对数可支配收入决定的对数食品消费模型。
负载Data_ConsumptionLogDT = varfun(@log,DataTable);numObs = height(LogDT) - sum(any(ismissing(LogDT),2))
numObs = 30
numPreds = width(LogDT) - 1
numPreds = 2
使用默认值进行定制测试。返回所有测试决策统计信息。
[h, h, Stat,W] = cusumtest(LogDT)
h =逻辑0
H =表1×28H1 H2 H3 H4 H5类推H7 H8 H9 H10 H11 H12 H13 H14 H15 H16 H17 H18段H19 H20 H21 H22 H23 H24 H25 H26 H27 H28 _____ _____ _____ _____ _____ _____ _____ _____ _____ _____ _____ _____ _____ _____ _____ _____ _____ _____ _____ _____ _____ _____ _____ _____ _____ _____ _____ _____ 测试1假假假假假假假假假假假假假假假假假假假假假假假假假假假假的
统计=表1×28Stat1 Stat2 Stat3 Stat4 Stat5 Stat6 Stat7 Stat8 Stat9 Stat10 Stat11 Stat12 Stat13 Stat14 Stat15 Stat16 Stat17 Stat18 Stat19 Stat20 Stat21 Stat22 Stat23 Stat24 Stat25 Stat26 Stat27 Stat28 _____ _________ ________ ________ ________ ________ _______ _______ _______ _______ ______ ________ ________ ______ ______ ______ ______ ______ ______ ______ ______ ______ ______ ______ ______ _______ ________ ________ 测试1南-0.012438 0.064511 -0.50784 -0.55747 -0.42687 -2.7881 -3.0973 -3.7625 -3.5417-1.913 -0.65794 -0.35743 2.3762 3.3104 3.7509 2.8851 3.7395 4.2295 4.641 4.2412 4.496 3.2467 2.0001 1.5324 0.81729 0.053352 -0.98812
W =表1×28W1 W2 W3 W4 W5将支W7 W8 W9 W10 W11 W12确实W14 W15 W16 W17 W18 W19 W20 21 W22 W23 W24 W25 W26 W27 W28 ___ ___________ __________ __________ ___________ _________ _________ __________ __________ _________ ________ ________ ________ ________ _________ _________ __________ _________ _________ _________ __________ _________ _________ _________ __________ __________ __________ _________ 测试1南-0.00012823 0.00079327 -0.0059004 -0.00051169 0.0013464 -0.024342 -0.0031882 -0.0068572 0.00227620.016791 0.012938 0.003098 0.028181 0.0096305 0.0045417 -0.0089262 0.0088086 0.0050515 0.0042415 -0.0041209 0.0026269 -0.012879 -0.012851 -0.0048219 -0.0073721 -0.0078755 -0.010737
cusumtest返回总体拒绝决定h,以及包含来自该检验的正向递归的拒绝决策序列的表H,对应序列的检验统计量统计,和相应的递归残差W.每个表包含numObs - numPreds + Intercept = 28在cusum检验中,每个递归结果对应的变量。Stat1 = W1 = NaN指示模型截距的存在。
图递归残差和关键线
通过绘制递归残差来确定实际国民生产总值(RGNP)的解释模型是否稳定。
加载Nelson-Plosser数据集Data_NelsonPlosser.mat,其中包含数据表数据表.
负载Data_NelsonPlosser
数据集中的时间序列包含从1860年到1970年的年度宏观经济测量数据。有关详细信息、变量列表和描述,请输入描述在命令行中。
将表格转换为时间表。将样本聚焦到1915年底到1970年底的测量。
Dates = datetime(Dates,12,31);Span = isbetween(日期,datetime(1915,12,31),datetime(1970,12,31),“关闭”);TT = table2时间表(数据表,RowTimes=日期);TT。日期= [];TT = TT(span,:);
考虑一个美国RGNP的预测模型GNPR给定工业生产指数的测量值新闻学会,总就业人数E,以及实际工资或者说是.
在模型中绘制级数。
预名= [“他们”“E”“福”];tiledlayout (2, 2)为J = [“GNPR”nexttile plot(TT. time,TT{:,j})结束
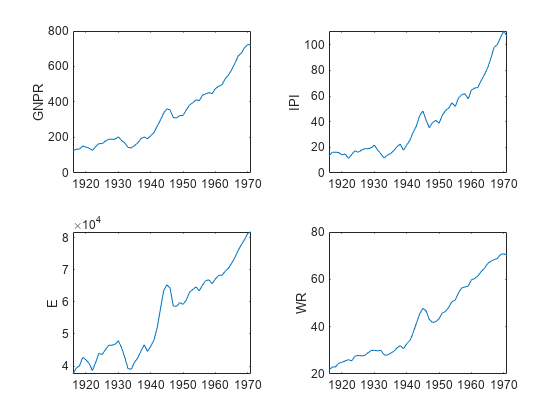
要处理指数增长,请对级数应用对数变换。
LogTT = varfun(@log,TT);
LogTT是否有包含转换变量的时间表TT,但在名字前加上log_.
假设一个合适的多元回归模型来描述真实的GNP是
进行习惯检验以评估所有回归系数是否稳定。将测试摘要打印到命令行。绘制测试统计数据。
lprednames =“log_”+ prednames;cusumtest (LogTT ResponseVariable =“log_GNPR”,...PredictorVariables = lprednames显示=“摘要”)
结果摘要***************试验1试验类型:cusum试验方向:正向拦截:是迭代次数:52决策:拒绝失败稳定性系数显著性水平:0.0500
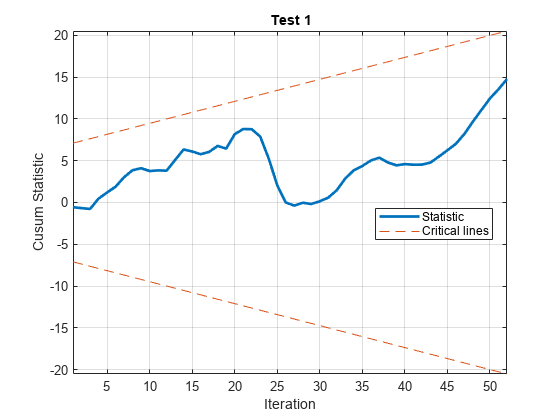
cusum级数没有越过临界线,表明模型稳定。
结构变化的测试消耗模型
进行习惯测试,以评估第二次世界大战前后粮食需求方程式是否存在结构性变化。实现正向和向后递归回归以获得测试统计信息。
加载美国食品消费数据集Data_Consumption.mat,其中包含1927年至1962年的年度测量数据,由于第二次世界大战,表格中缺少数据数据表.将表转换为时间表,并删除包含缺失值的行。
负载Data_ConsumptionDates = datetime(Dates,12,31);TT = table2时间表(数据表,RowTimes=日期);TT。Row = [];TT = rmmissing(TT);
考虑一个由对数食品价格和对数可支配收入决定的对数食品消费模型,并通过战争带来的经济冲击来评估其稳定性。
对表中的所有变量应用日志转换。
LogTT = varfun(@log,TT);
对每个测试使用5%的显著性水平进行正向和反向习惯测试。画出cusum。返回递归残差。
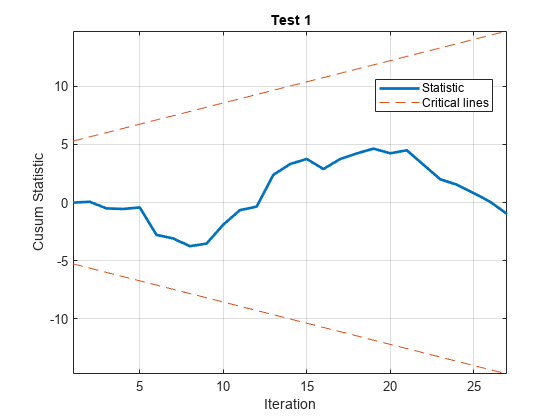
[h,~,~,W] = cusumtest(LogTT,方向=[“转发”“落后”),...情节=“上”);
结果摘要***************测试1测试类型:cusum测试方向:正向拦截:是迭代次数:27决策:拒绝失败稳定性系数显著性水平:0.0500
***************测试2测试类型:cusum测试方向:向后拦截:是迭代次数:27决策:拒绝失败系数稳定性显著性水平:0.0500
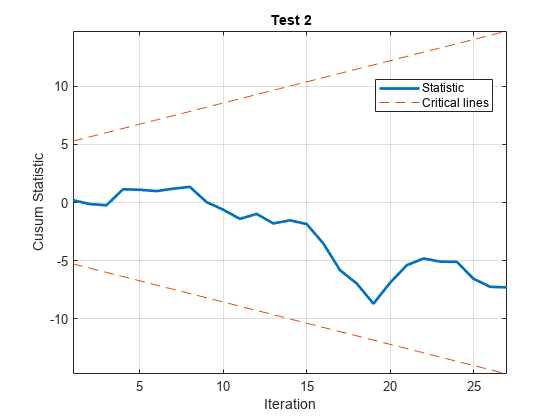
命令行上的图和检验结果表明,两个检验都没有拒绝系数稳定的零假设。
将cusum测试结果与Chow测试结果进行比较。与cusum试验不同,Chow试验需要对结构断裂发生的时间点进行猜测。指定断点为1941年。
bp = find(LogTT。时间>= datetime(1941,12,31),1);chowtest (LogTT, bp,显示=“摘要”);
结果摘要***************试验1样本量:30断点:15试验类型:断点被测系数:全部统计量:5.5400临界值:3.0088 P值:0.0049显著性水平:0.0500决定:拒绝稳定系数
检验结果否定了系数稳定的原假设。
Chow和cusum测试结果不一致。有关习惯测试限制的详细信息,请参见限制.
波动性中结构断裂的检验
检查平方检验是否可以检测模拟数据中波动率的结构断裂。
从这个回归模型中模拟一系列数据
是三个标准高斯预测变量的一系列观测结果。 而且 为均值为0,标准差分别为0.1和0.2的一系列高斯变换。
rng (1);%用于再现性T = 100;X = randn(T,3);Sigma1 = 0.1;Sigma2 = 0.2;e = [sigma1*randn(T/2,1);sigma2 * randn (T / 2,1)];B = (1:3)';y = X*b + e;
使用5%显著性水平进行平方检验。绘制测试统计数据和关键区域频带。表示没有模型截距。请求在每次迭代中返回测试统计数据是否跨越临界区域。
[~,H] = cusumtest(X,y,Test=“cusumsq”、情节=“上”,...方向= [“转发”“落后”),显示=“关闭”,...拦截= false);
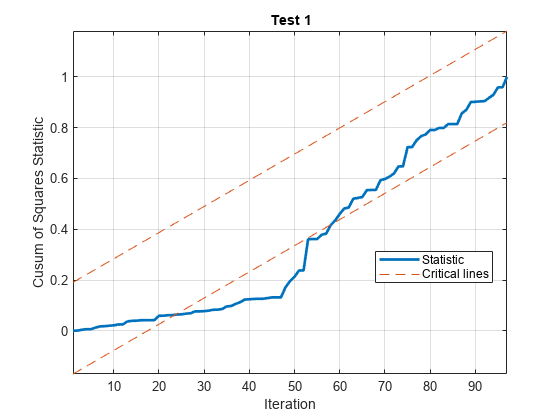
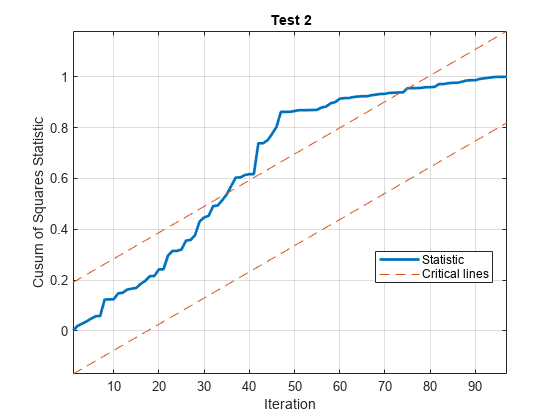
由于两个检验的检验统计量至少都越过了临界线一次,因此检验拒绝了5%水平波动率恒定的原假设。测试统计信息在迭代50左右改变方向,这与数据中模拟的波动中断是一致的。
H是一个2乘97的逻辑矩阵,包含每个平方检验的每次迭代的决策序列。第一行对应正方差检验,第二行对应后方差检验。
对于正向测试,确定导致测试统计数据越过临界线的迭代。
bp = find(H(1,:) == 1)
英国石油(bp) =1×3524 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58
输入参数
输出参数
限制
在以下情况下,Cusum测试几乎无法检测结构变化。
在样本周期的后期
当多个更改在习惯法中产生取消时
更多关于
提示
算法
cusumtest使用中建议的方法处理初始常数预测器数据[1].如果第一个预测者的数据是恒定的numCoeffs观察和这导致多重共线性与截距或另一个预测,然后cusumtest从回归和递归残差的计算中删除预测器,直到其数据发生变化。同样的,cusumtest暂时从向后回归中提出最终常数预测。逆向回归中的初始常数预测因子,或正向回归中的最终常数预测因子,都不能由cusumtest并且可能导致终端迭代中的秩不足。cusumtest以本质上不同的方式为两个测试统计值计算推理的关键行。cusums,cusumtest的CDF方程[1]的每一个值α.对于平方的积分检验,cusumtest中插入表中的参数值[2]中所建议的方法[1].自由度小于4的样本量低于表中值,且cusumtest无法计算关键线。自由度大于202的样本量在表值以上,且cusumtest使用与最大表列样本量相关的临界值。
参考文献
布朗、R. L.德宾和J. M.埃文斯。测试回归关系随时间恒常性的技术皇家统计学会杂志B辑.第37卷,1975,第149-192页。
[2]德宾,J。基于最小二乘残差周期图的回归分析中的序列相关性检验生物统计学.卷56,1969,第1-15页。
版本历史
在R2016a中引入另请参阅
您也可以从以下列表中选择一个网站: