连接词的错误方式风险
这个例子展示了一种使用高斯copula来模拟交易对手信用风险错误路径的方法。
交易对手信用风险(CCR)的基本方法(见交易对手信用风险和CVA假设市场和信用风险因素是相互独立的。对市场风险因素的模拟驱动了投资组合中所有合约的敞口。在另一个单独的步骤中,信用违约掉期(CDS)市场报价决定每个交易对手的违约概率。风险暴露、违约概率和给定的回收率被用来计算每个交易对手的信用价值调整(CVA),这是预期损失的衡量标准。风险因素的模拟和违约概率的模拟是相互独立的。
在实践中,违约概率和市场因素是相互关联的。这种关系对于某些类型的工具可能可以忽略不计,但对于其他类型的工具,市场和信用风险因素之间的关系可能太重要了,以至于在计算风险度量时不能忽视。
当交易对手违约概率和特定合同导致的风险敞口一起增加时,我们称该合同存在错误方向风险(WWR)。
这个例子演示了Garcia Cespedes等人所描述的错误风险方法的实现(见参考文献)。
接触模拟
许多金融机构都有模拟市场风险因素的系统,并在给定的模拟日期对其投资组合中的所有工具进行估值。这些模拟被用来计算暴露和其他风险措施。由于模拟是计算密集型的,因此重用它们进行后续风险分析是很重要的。
本例使用的数据和仿真结果来自交易对手信用风险和CVA示例,以前保存在ccr中。垫文件。ccr。垫文件包含:
RateSpec:计算合同价值时的费率规格解决:计算合同金额的结算日期simulationDates:模拟日期向量掉期交易:包含交换参数的结构体值:NUMDATESxNUMCONTRACTxNUMSCENARIOS每个日期/场景的模拟合同值的立方体
本例只考察一年时间范围内的预期损失,因此数据是在一年的模拟之后裁剪的。第一年的模拟日期以月为频率,所以第13个模拟日期是我们一年的时间范围(第一个模拟日期是确定日期)。
负载ccr.matoneYearIdx = 13;值=值(1:oneYearIdx,:,);日期= simulationDates (1: oneYearIdx);numScenarios =大小(价值观,3);
信用风险敞口是从模拟的合同价值中计算出来的。这些风险敞口是每个交易对手从结算日到我们的一年时间范围的月度信贷风险敞口。
由于违约可能在一年期期间的任何时间发生,因此通常基于预期正暴露(EPE)的思想对违约暴露(EAD)进行建模。计算每个场景的时间平均曝光量,称为PE(正曝光)。PE的平均值,包括所有场景,是EPE,也可以从exposureprofiles函数。
正曝光矩阵体育每个模拟场景包含一行,每个交易方包含一列。这在我们的分析中用作EAD。
计算交易对手风险敞口[敞口,交易对手]=信用敞口(价值,互换)。交易对手,...“NettingID”, swaps.NettingID);numCP =元素个数(对手);计算每个场景的PE(时间平均曝光)intervalWeights = diff(日期)/(日期(结束)-日期(1));exposureMidpoints = 0.5 *(曝光(1:end-1,:,:) +曝光(2:end,:));weightedContributions = bsxfun (@times intervalWeights exposureMidpoints);PE =挤压(sum (weightedContributions));计算每个场景的总投资组合风险totalExp = (PE、2)之和;%PE和totalExp的显示大小谁体育totalExp
名称大小字节类属性PE 1000x5 40000 double totalExp 1000x1 8000 double
信贷模拟
模拟信用违约的常见方法是基于“单因素模型”,有时也被称为“资产价值方法”(参见Gupton et al., 1997)。这是模拟相关默认值的一种有效方法。
每个公司我是否与随机变量相关彝族,这样
在哪里Z为“单因素”,这是一个标准的正态随机变量,代表一个系统信用风险因素,其值影响所有公司。公司之间的相关性我公因数由下式给出beta_i,公司之间的相关性我和j是beta_i * beta_j.特殊的冲击εi是另一个标准的正常变量,它可以减少或增加系统因素的影响,独立于任何其他公司的情况。
如果公司的违约概率我是PDi,则默认为
在哪里 为累积标准正态分布。
的彝族变量有时被解释为资产收益,有时被称为潜在变量。
这个模型是一个高斯关联函数,它引入了信用违约之间的相关性。copula提供了一种特殊的方式来引入相关,或者更普遍地说,两个相互依赖未知的随机变量之间的相互依赖。
利用CDS息差来引导每个交易对手一年的违约概率。CDS报价来自《华尔街日报》使用的掉期投资组合电子表格交易对手信用风险和CVA的例子。
为每一交易对手进口CDS市场信息swapFile =“cva掉期投资组合.xls”;cd = readtable (swapFile,“床单”,“CDS利差”);cdsDates = datenum (cds.Date);cdsSpreads = table2array (cds(:, 2:结束));每个交易对手的启动默认概率zeroData=[RateSpec.EndDates RateSpec.Rates];defProb=零(1,大小(cdsSpreads,2));为i = 1:numel(defProb) probData = cdsbootstrap(zeroData, [cdsDates cdsSpreads(:,i)],...解决,“probDates”、日期(结束));defProb (i) = probData (2);结束
现在模拟信贷场景。因为违约很少见,所以通常会模拟大量信贷场景。
敏感性参数β被设置为0.3所有交易对手。这个值可以被校准或调整以探索模型的灵敏度。有关更多信息,请参阅参考资料。
numCreditScen = 100000;rng (“默认”);% Z是单个信用因素Z=randn(numcreditsen,1);%是特殊因素ε= randn (numCreditScen numCP);%是交易对手对信用因素的敏感性β=0.3*个(1,numCP);%交易对手潜在变量Y=bsxfun(@times,beta,Z)+bsxfun(@times,sqrt(1-beta.^2),ε);%默认指示器isDefault = bsxfun (@lt normcdf (Y), defProb);
关联风险敞口和信贷情景
既然已经有了一组分类过的投资组合风险敞口场景和一组默认场景,那么可以遵循Garcia Cespedes等人的方法,使用高斯关联函数生成相关的风险敞口-默认场景对。
定义一个潜在变量耶映射到模拟曝光的分布。耶被定义为
在哪里Z是信贷模拟中计算的系统因素,εe是一个独立的标准正态变量和ρ被解释为市场信用相关参数。通过构造,耶一个标准正态变量是否与Z与相关参数ρ.
之间的映射耶模拟的风险敞口要求我们根据某种可排序的标准,以有意义的方式对风险敞口场景进行排序。标准可以是任何有意义的数量,例如,它可以是合同价值(如利率)、总投资组合风险敞口等的潜在风险因素。
在本例中,使用总投资组合风险敞口(totalExp)作为风险敞口情景准则,将信用因素与总风险敞口关联起来。如果ρ是负的,低价值的信贷因素Z往往与高价值的耶因此,风险敞口较高。这意味着ρ介绍WWR。
要实现耶还有暴露场景,把暴露场景分类totalExp价值观假设暴露场景的数量为年代(numScenarios).鉴于耶,求值j以致
然后选择场景j从排序的暴露场景。
耶是否与模拟暴露有关Z与模拟的默认值相关。的相关性ρ之间耶和Z因此,是风险敞口和信用模拟之间的关联。
%排序总曝光[~,totalExpIdx]=排序(totalExp);场景切割点切割点=0:1/numScenarios:1;% epsilonExp是潜在变量的特殊因素epsilonExp = randn (numCreditScen, 1);%设置市场信用关联值ρ= -0.75;%潜变量y = rho * Z +根号(1 - rho^2) * epsilonExp;%找到相应的曝光场景binidx =离散化(normcdf(你们),割点);scenIdx = totalExpIdx (binidx);totalExpCorr = totalExp (scenIdx);PECorr = PE (scenIdx:);
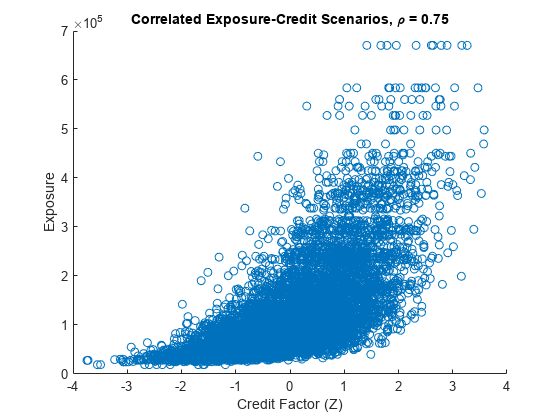
下图显示了总投资组合风险敞口以及第一个交易对手的相关风险敞口信用情景。由于负相关,信用因子的负值Z对应于高暴露水平(错误的风险)。
%我们最多只能策划10000个场景numScenPlot = min(10000年,numCreditScen);图;散射(Z (1: numScenPlot) totalExpCorr (1: numScenPlot))在散射(Z (1: numScenPlot) PECorr (1: numScenPlot, 1)包含(“信贷因素(Z)”) ylabel (“曝光”)标题('相关风险敞口-信贷情况,\rho = 'num2str(ρ)])传说(“总曝光量”,“CP1曝光”)举行从

为正值时ρ,信用因素和风险暴露之间的关系是反向的(正确的风险)。
ρ= 0.75;y = rho * Z +根号(1 - rho^2) * epsilonExp;binidx =离散化(normcdf(你们),割点);scenIdx = totalExpIdx (binidx);totalExpCorr = totalExp (scenIdx);图;散射(Z (1: numScenPlot) totalExpCorr (1: numScenPlot))包含(“信贷因素(Z)”) ylabel (“曝光”)标题('相关风险敞口-信贷情况,\rho = 'num2str(ρ)))
对相关的敏感性
您可以探索的敏感性暴露或其他风险措施的一个范围的值ρ.
对于每个值ρ,计算每个信贷场景的总损失以及每个交易对手的预期损失。本示例假设恢复率为40%。
复苏= 0.4;rhoValues = 1:0.1:1;totalLosses = 0 (numCreditScen元素个数(rhoValues));expectedLosses = 0 (numCP, nummel (rhoValues));为i = 1:numel(rhoValues) rho = rhoValues(i);%潜变量y = rho * Z +根号(1 - rho^2) * epsilonExp;%找到相应的曝光场景binidx =离散化(normcdf(你们),割点);scenIdx = totalExpIdx (binidx);simulatedExposures = PE (scenIdx:);%根据风险暴露和违约事件计算实际损失损失= isDefault .* simulateexposure * (1-Recovery);totalLosses (:, i) =(损失,2)之和;我们计算每个交易对手的预期损失expectedLosses(:,我)=意味着(损失);结束显示预期损失(rhoValues,ExpectedLoss)
预计损失Rho CP1 CP2 CP3 CP4 CP5-----------------------------------------------------------------1.0 604.10 260.44 194.70 1234.17 925.95-0.9 583.67 250.45 189.02 1158.65 897.91-0.8 560.45 245.19 183.23 1107.56 865.33-0.7 541.08 235.86 177.16 1041.39 835.12-0.6 521.89 228.78 170.49 991.70 803.22-0.5 502.68 165.25 926.27-0.211.29160.80 881.03 746.15-0.3 471.17 203.55 154.79 828.90 715.63-0.2 450.91 197.53 149.33 781.81 688.13-0.1 433.87 189.75 144.37 744.00 658.19 0.0 419.20 181.25 138.76 693.26 630.38 0.1 399.36 174.41 134.83 650.66 605.89 0.2 385.21 169.86 130.93 617.91 579.01 0.3 371.21 164.19 124.62 565.78 552.83 0.4 355.57 158.14 119.92 530.79 530.19 0.5 342.58 152.10 116.38 496.27 508.86 0.6 324.73 145.42 111.90 466.57 485.05 0.7 319.18 140.76 108.14 429.48 465.84 0.8 303.71 136.13 103.95 405.88 446.36 0.9 290.36 131.54 100.20 381.27 422.79 1.0 278.89 126.77 95.77 358.71 405.40
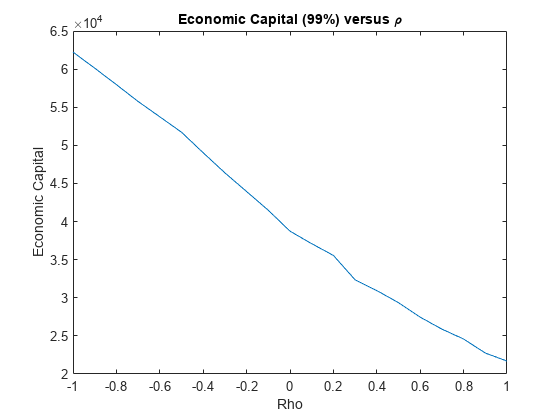
你可以想象经济资本(EC)对市场信用相关参数的敏感性。将EC定义为一个百分点之间的差异问损失的分布,减去预期损失。
负的ρ导致更高的资本要求,因为WWR。
pct=99;ec=百分比(总骨数,pct)-平均值(总骨数);图形绘图(rhoValues,ec)标题(“经济资本(99%)vs . rho”)包含(的ρ);ylabel (“经济资本”);
最后发言
这个例子实现了一种基于连接的WWR方法,遵循Garcia Cespedes等人的方法。该方法可以有效地重用现有的风险敞口和信贷模拟,并且可以有效地计算出所有相关值对市场信贷相关参数的敏感性,并方便地可视化。
本文提出的单参数copula方法可以扩展,以便更深入地研究投资组合的WWR。例如,可以应用不同类型的连接词,并且可以使用不同的标准对暴露场景进行排序。其他扩展包括模拟多个系统性信用风险变量(多因素模型),或从一年期框架转换为多期框架,以计算信用价值调整(CVA)等措施,如Rosen和Saunders(见参考文献)。
参考文献
《巴塞尔协议II中错误路径风险、交易对手信用风险资本和阿尔法的有效建模》,《金融研究》,风险模型验证杂志,第4卷/第1期,第71-98页,2010年春季。
Gupton,G.,C.Finger和M.Bathia,CreditMetrics™-技术文档jp·摩根,纽约,1997年。
罗森,D.和D.桑德斯,《CVA错误的方式》金融机构风险管理杂志, Vol. 5, No. 3, pp. 252-272, 2012。
本地函数
函数displayExpectedLosses (rhoValues expectedLosses)流(“预期损失\ n”);流(' Rho CP1 CP2 CP3 CP4 CP5\n');流(“-------------------------------------------------------------\n”);为i=1:numel(值)%显示预期损失流(' % .1f % 9.2 f % 9.2 f % 9.2 f % 9.2 f % 9.2 f ',rho值(i),预期损失(:,i));结束结束
另请参阅
cdsbootstrap|cdsprice|cdsrpv01|cdsspread
相关的话题
外部网站
你也可以从以下列表中选择一个网站:
