使用命令行识别线性模型
简介
目标
从多输入/单输出(MISO)数据中估计和验证线性模型,以找到最能描述系统动态的模型。
完成本教程后,您将能够使用命令行完成以下任务:
创建数据对象来表示数据。
绘制数据图。
通过去除输入和输出信号的偏移量来处理数据。
根据数据估计和验证线性模型。
模拟和预测模型输出。
请注意
本教程使用时域数据演示如何估计线性模型。同样的工作流程也适用于频域数据的拟合。
数据描述
本教程使用数据文件co2data.mat,其中包含来自稳态的双输入单输出(MISO)时域数据的两个实验,该算子从平衡值扰动。
在第一个实验中,操作员向两个输入输入都输入了脉冲波。在第二个实验中,操作员向第一个输入输入脉冲波,向第二个输入输入步进信号。
准备数据
将数据载入MATLAB工作空间
加载数据。
负载co2data
这个命令将以下五个变量加载到MATLAB工作区中:
Input_exp1而且Output_exp1分别是第一个实验的输入和输出数据。Input_exp2而且Output_exp2分别为第二次实验的输入和输出数据。时间时间向量是从0到1000分钟,是以相等的增量增加的吗0.5分钟。
对于这两个实验,输入数据由两列值组成。第一列值是化学品消耗速率(单位为千克/分钟),第二列值是电流(单位为安培)。输出数据是二氧化碳产生速率的单列(以毫克每分钟为单位)。
绘制输入/输出数据
画出两个实验的输入和输出数据。
情节(时间、Input_exp1时间,Output_exp1)传说(输入1的,“输入2”,“输出1”)图(时间,Input_exp2,时间,Output_exp2)输入1的,“输入2”,“输出1”)

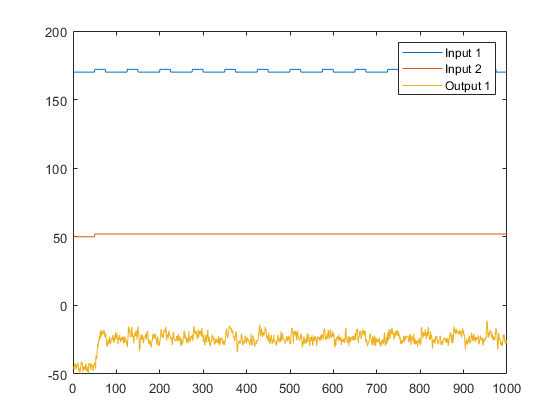
第一个图显示了第一个实验,其中操作员对每个输入施加脉冲波以使其从稳态平衡中扰动。
第二个图显示了第二个实验,其中操作员对第一个输入施加脉冲波,对第二个输入施加步进信号。
从数据中去除均衡值
绘制数据,如中所述绘制输入/输出数据,表明输入和输出具有非零均衡值。在本教程的这一部分中,您将从数据中减去平衡值。
从每个信号中减去平均值的原因是,通常情况下,您要建立线性模型来描述偏离物理平衡时的响应。对于稳态数据,可以合理地假设信号的平均水平对应于这种平衡。因此,您可以在零附近寻找模型,而无需在物理单位中建模绝对平衡水平。
放大图,可以看到操作员对输入施加扰动的最早时刻发生在稳态条件下25分钟之后(或在前50个样本之后)。因此,前50个样本的平均值代表平衡条件。
使用以下命令删除两个实验中输入和输出的平衡值:
Input_exp1 = Input_exp1-...(大小(Input_exp1, 1), 1) *意味着(Input_exp1 (1:50,:));Output_exp1 = Output_exp1-...意思是(Output_exp1 (1:50,:));Input_exp2 = Input_exp2-...(大小(Input_exp2, 1), 1) *意味着(Input_exp2 (1:50,:));Output_exp2 = Output_exp2-...意思是(Output_exp2 (1:50,:));
使用对象表示系统标识的数据
系统识别工具箱™数据对象,iddata而且idfrd,将数据值和数据属性封装到单个实体中。可以使用“系统标识工具箱”命令方便地将这些数据对象作为单个实体操作。
在本教程的这一部分中,您将创建两个iddata对象,两个实验各一个。您使用来自实验1的数据进行模型估计,而来自实验2的数据用于模型验证。您使用两个独立的数据集,因为您使用一个数据集进行模型估计,而使用另一个数据集进行模型验证。
请注意
当没有两个独立的数据集时,可以将一个数据集分成两个部分,假设每个部分包含足够的信息来充分表示系统动态。
创建iddata对象
您必须已经将示例数据加载到MATLAB中®工作区,如中所述加载数据到MATLAB工作区.
使用这些命令创建两个数据对象,泽而且zv:
Ts = 0.5;%采样时间为0.5分钟ze = iddata(Output_exp1,Input_exp1,Ts);zv = iddata(Output_exp2,Input_exp2,Ts);
泽包含实验1和的数据zv包含实验2的数据。Ts是采样时间。
的iddata构造函数需要三个参数来获取时域数据,语法如下:
Data_obj = iddata(输出,输入,sampling_interval);
控件的属性iddata对象时,使用得到命令。例如,输入这个命令来获取估计数据的属性:
(泽)
ans = struct with fields: Domain: 'Time' Name: " OutputData: [2001x1 double] y: 'Same as OutputData' OutputName: {'y1'} OutputUnit: {"} InputData: [2001x2 double] u: 'Same as OutputData' InputName: {2x1 cell} InputUnit: {2x1 cell} Period: [2x1 double] InterSample: {2x1 cell} Ts: 0.5000 Tstart: [] SamplingInstants: [2001x0 double] TimeUnit: 'seconds' ExperimentName: 'Exp1' Notes: {} UserData: []
要详细了解此数据对象的属性,请参见iddata参考页面。
要修改数据属性,可以使用点表示法或集命令。例如,要分配通道名称和标记绘图轴的单元,请在MATLAB命令窗口中键入以下语法:
%设置时间单位为分钟泽。TimeUnit =“最小值”;设置输入通道的名称泽。InputName = {“ConsumptionRate”,“当前”};为输入变量设置单位泽。InputUnit = {公斤/分钟的,“一个”};设置输出通道名称泽。OutputName =“生产”;设置输出通道单位泽。OutputUnit =毫克/分钟的;设置验证数据属性zv。TimeUnit =“最小值”;zv。InputName = {“ConsumptionRate”,“当前”};zv。InputUnit = {公斤/分钟的,“一个”};zv。OutputName =“生产”;zv。OutputUnit =毫克/分钟的;
您可以验证InputName的属性泽更改,或“index”到此属性:
ze.inputname;
提示
属性名,例如InputUnit,不区分大小写。还可以缩写以。开头的属性名输入或输出用u为输入而且y为输出属性名。例如,OutputUnit等于yunit.
绘制数据对象中的数据
你可以画图iddata对象使用情节命令。
绘制估计数据。
情节(泽)
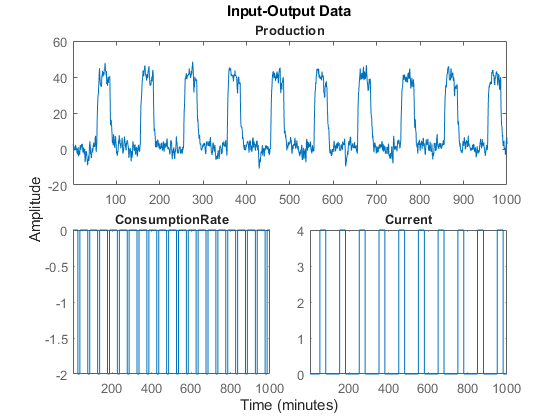
底部轴显示输入ConsumptionRate而且当前的,顶部轴显示输出ProductionRate.
在新的图形窗口中绘制验证数据。
数字打开一个新的MATLAB图窗口情节(zv)绘制验证数据

放大图,可以看到实验过程放大了第一个输入(ConsumptionRate)放大2倍,并放大第二个输入(当前的)是原来的10倍。
选择数据的子集
在开始之前,创建一个新的数据集,其中只包含原始估计和验证数据集的前1000个样本,以加快计算速度。
Ze1 = ze(1:1000);Zv1 = zv(1:1000);
有关索引的更多信息iddata对象,请参见相应的参考页。
估计脉冲响应模型
为什么要估计阶跃响应模型和频率响应模型?
频率响应和阶跃响应为非参数可以帮助您理解系统动态特性的模型。这些模型不是用一个具有可调参数的紧凑数学公式来表示的。相反,它们由数据表组成。
在本教程的这一部分中,您将使用数据集估计这些模型泽.你必须已经创建了泽,详见创建iddata对象.
这些模型的响应图显示了系统的以下特征:
从第一个输入到输出的响应可能是一个二阶函数。
从第二个输入到输出的响应可能是一阶函数或过阻尼函数。
估计频率响应
系统识别工具箱产品提供了三个用于估计频率响应的功能:
使用水疗中心估计频率响应。
Ge = spa(ze);
把频率响应画成波德图。
波德(Ge)
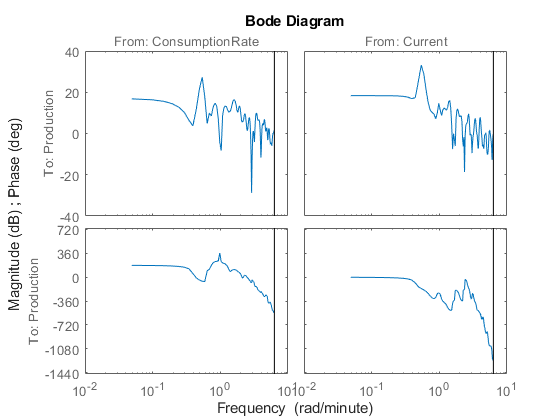
振幅在频率为0.54 rad/min时达到峰值,这表明第一输入-输出组合可能存在谐振行为(复极)ConsumptionRate来生产.
在这两个图中,相位迅速滚下,这表明输入/输出组合都有时间延迟。
估计经验阶跃响应
为了从数据中估计阶跃响应,首先从数据中估计非参数脉冲响应模型(FIR滤波器),然后绘制其阶跃响应。
%模型估计Mimp =冲量(Ze1,60);%阶跃响应步骤(Mimp)
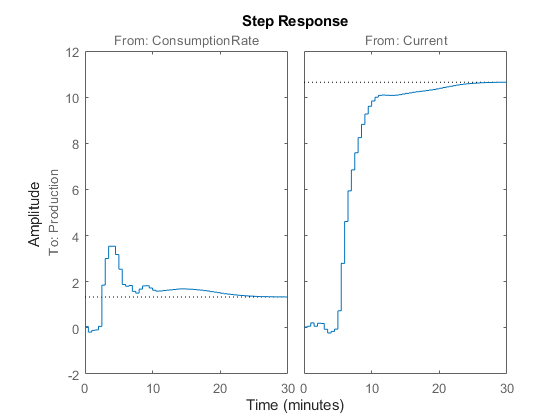
第一个输入/输出组合的阶跃响应表明了超调,这表明物理系统中存在欠阻尼模式(复极)。
从第二个输入到输出的阶跃响应没有显示超调,这表明要么是一阶响应,要么是具有实极的高阶响应(过阻尼响应)。
阶跃响应图表示系统中的非零延迟,这与您在创建的波德图中得到的快速相位滚转一致估计经验阶跃响应.
多输入系统的延迟估计
为什么要评估延迟?
为了识别参数化黑盒模型,您必须指定输入/输出延迟作为模型顺序的一部分。
如果您不能从实验中知道系统的输入/输出延迟,您可以使用系统识别工具箱软件来估计延迟。
使用ARX模型结构估计延迟
在单输入系统的情况下,您可以在脉冲-响应图上读取延迟。但是,在多输入系统(例如本教程中的系统)的情况下,您可能无法判断是哪个输入导致了输出中的初始更改,因此可以使用延迟命令。
该命令通过估计具有一定延迟范围的低阶离散ARX模型来估计动态系统中的时间延迟,然后选择与最佳拟合对应的延迟。
ARX模型结构是最简单的黑盒参数结构之一。在离散时间条件下,ARX结构是一个差分方程,形式如下:
y (t)表示当时的输出t,u (t)表示当时的输入t,n一个是极点的数目,nb是b参数(等于0的个数加1),nk输入之前的样本数量是否会影响系统的输出(称为延迟或死时间模型的),以及e (t)就是白噪声干扰。
延迟假设n一个=nb=2那就是噪音e是白色还是无关紧要,和估计nk.
要估计该系统中的延迟,输入:
延迟(泽)
Ans = 5 10
这个结果包括两个数字,因为有两个输入:第一个输入的估计延迟为5数据样本,第二次输入的估计延迟为10数据样本。因为实验的采样时间是0.5Min,这对应于a2.5-min第一次输入影响输出之前的延迟5.0-min第二次输入影响输出的延迟时间。
使用替代方法估计延迟
有两种方法可以估计系统中的时间延迟:
绘制输入和输出数据的时间图,并读取输入中的第一次变化与输出中的第一次变化之间的时间差。该方法仅适用于单输入/单输出系统;在多输入系统的情况下,您可能无法判断是哪个输入导致了输出中的初始变化。
绘制具有1个标准差置信区域的数据的脉冲响应。你可以用脉冲响应第一次出现在置信区外的时间来估计时间延迟。
使用ARX模型结构估计模型顺序
为什么估计模型顺序?
模型秩序定义模型复杂性的一个或多个整数。一般来说,模型的阶数与极点数、零数和响应延迟(输出响应输入之前的样本数表示的时间)有关。模型顺序的具体含义取决于模型的结构。
要计算参数化黑盒模型,必须提供模型顺序作为输入。如果你不知道你的系统的阶数,你可以估计它。
完成本节的步骤后,您将得到以下结果:
对于第一个输入/输出组合:n一个= 2,nb=2,和延迟nk= 5。
对于第二个输入/输出组合:n一个= 1,nb=1,延时nk= 10。
稍后,您将通过指定模型顺序值来探索不同的模型结构,这些值与这些初始估计略有不同。
用于估计模型顺序的命令
在本教程的这一部分,您将使用struc,arxstruc,selstruc对一定范围的模型阶数和延迟估计和比较简单多项式(ARX)模型,并根据模型质量选择最佳阶数。
各命令执行结果如下所示:
struc为的指定范围创建模型顺序组合的矩阵n一个,nb,nk值。arxstruc从struc,系统地估计每个模型订单的ARX模型,并将模型输出与测量输出进行比较。arxstruc返回损失函数对于每个模型,它是预测误差平方和的归一化和。selstruc从arxstruc并打开ARX模型结构选择窗口,如下图所示,以帮助您选择模型顺序。您可以使用这个图来选择最合适的模型。

横轴是参数的总数-n一个+nb.
纵轴,称为无法解释的输出方差(%),是模型未解释的输出部分——ARX模型对横轴上显示的参数数量的预测误差。
的预测误差是验证数据输出与模型提前一步预测输出之间差异的平方和。
nk就是延迟。
三个矩形在图中以绿色、蓝色和红色突出显示。每种颜色表示一种最佳拟合准则,如下所示:
红色-最佳拟合最小化验证数据输出和模型输出之间差异的平方和。这个矩形表示整体最合适。
绿色-最佳拟合最小化Rissanen MDL标准。
蓝色-最佳拟合最小化赤池AIC标准。
在本教程中,无法解释的输出方差(%)Value对于参数的组合数量从4到20保持大致不变。这种恒常性表明模型的性能在更高阶时没有改善。因此,低阶模型可能同样能很好地拟合数据。
请注意
当您使用相同的数据集进行估计和验证时,请使用MDL和AIC标准来选择模型顺序。这些标准弥补了使用太多参数导致的过拟合。有关这些标准的更多信息,请参见
selstruc参考页面。

第一个输入输出组合的模型顺序
在本教程中,系统有两个输入和一个输出,您可以独立地估计每个输入/输出组合的模型顺序。可以同时估计两个输入的延迟,也可以一次估计一个输入的延迟。
对于第一个输入/输出组合,尝试以下顺序组合是有意义的:
n一个=
2:5nb=
1:5nk=
5
这是因为你估计的非参数模型估计脉冲响应模型说明第一个输入/输出组合的响应可能有一个二阶响应。同样,在多输入系统的延迟估计时,该输入/输出组合的延迟估计为5。
估计第一个输入/输出组合的模型顺序:
使用
struc为可能的模型订单创建一个矩阵。NN1 = struc(2:5,1:5,5);
使用
selstruc计算ARX模型中订单的损失函数NN1.selstruc (arxstruc(泽(:,:1),zv (:,: 1), NN1))
请注意
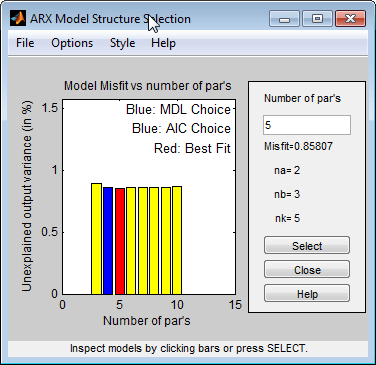
泽(:,:1)选择数据中的第一个输入。这个命令打开交互式ARX模型结构选择窗口。
请注意
Rissanen MDL和Akaike AIC标准产生相同的结果,均在图上用蓝色矩形表示。
红色矩形表示最佳的整体拟合,出现在n一个= 2,nb= 3,nk= 5。红色和蓝色矩形之间的高度差是不显著的。因此,可以选择模型阶数最低、模型最简单对应的参数组合。
单击蓝色矩形,然后单击选择要选择这样的顺序组合:
n一个=
2nb=
2nk=
5若要继续,请在MATLAB命令窗口中按任意键。

第二个输入输出组合的模型顺序
对于第二个输入/输出组合,尝试以下顺序组合是有意义的:
n一个=
1:3nb=
1:3nk=
10
这是因为你估计的非参数模型估计脉冲响应模型说明第二个输入/输出组合的响应可能具有一阶响应。同样,在多输入系统的延迟估计时,该输入/输出组合的延迟估计为10。
估计第二个输入/输出组合的模型顺序:
使用
struc为可能的模型订单创建一个矩阵。NN2 = struc(1:3,1:3,10);
使用
selstruc计算ARX模型中订单的损失函数NN2.selstruc (arxstruc(泽(:,:2),zv (:,: 2), NN2))
这个命令打开交互式ARX模型结构选择窗口。
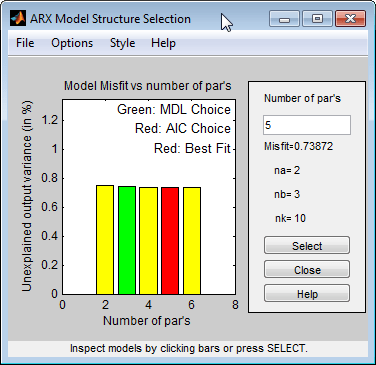
请注意
赤池AIC与整体最优拟合准则的结果相当。两者都在图上用相同的红色矩形表示。
所有矩形之间的高度差是不显著的,所有这些模型顺序导致相似的模型性能。因此,可以选择模型阶数最低、模型最简单对应的参数组合。
单击最左边的黄色矩形,然后单击选择选择最低的顺序:n一个= 1,nb= 1,nk= 10。
若要继续,请在MATLAB命令窗口中按任意键。

估计传递函数
指定传递函数的结构
在本教程的这一部分中,您将估计一个连续时间传递函数。您必须已经准备好数据,如准备数据.您可以使用以下估计模型顺序的结果来指定模型的顺序:
对于第一个输入/输出组合,使用:
两极,对应于
na = 2在ARX模型中。延迟5,对应
nk = 5样本(或2.5分钟)在ARX模型。
对于第二个输入/输出组合,使用:
一极,对应于
na = 1在ARX模型中延迟10,对应
nk = 10样本(或5分钟)在ARX模型。
你可以估计这些阶的传递函数使用特遣部队命令。对于评估,您还可以通过设置进度报告来选择查看进度报告显示选项在属性创建的选项集中tfestOptions命令。
Opt = tfestOptions(“显示”,“上”);
将模型订单和延迟收集到变量中传递特遣部队.
Np = [2 1];ioDelay = [2.5 5];
估计传递函数。
mtf = tfest(Ze1,np,[],ioDelay,Opt);

查看模型的系数。
mtf
mtf =从输入“ConsumptionRate”到输出“Production”:-1.382 s + 0.0008305 exp(-2.5*s) * ------------------------- s^2 + 1.014 s + 5.435e-12从输入“Current”到输出“Production”:5.93 exp(-5*s) * ---------- s + 0.5858连续时间识别传递函数。参数化:极点数:[2 1]零数:[10 0]自由系数数:6参数及其不确定性使用“tfdata”,“getpvec”,“getcov”。状态:使用TFEST对时域数据“Ze1”进行估计。拟合估计数据:78.92% FPE: 14.22, MSE: 13.97
模型显示与估计数据的拟合度超过85%。
验证模型
在本教程的这一部分中,您将创建一个比较实际输出和模型输出的图形比较命令。
比较(Zv1 mtf)
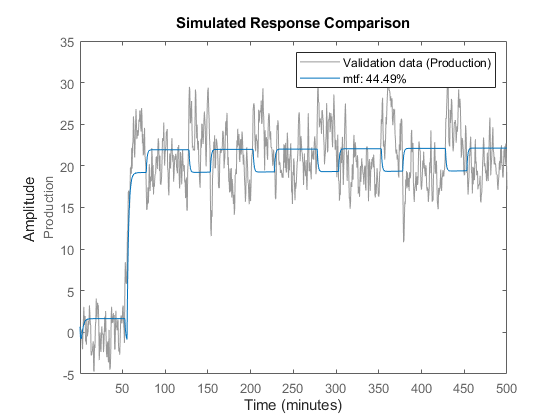
相比之下,大约60%的人适合。
残留分析
使用渣油命令来评估残差的特征。
渣油(Zv1 mtf)
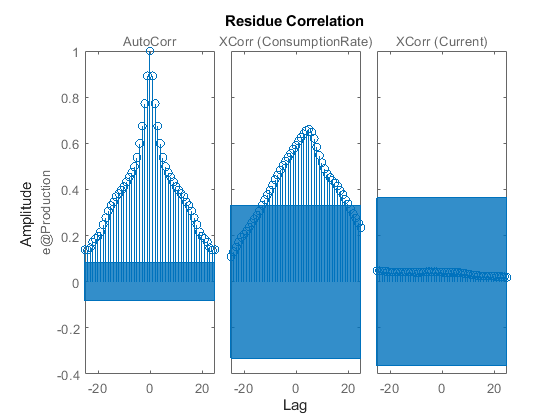
残差表现出高度的自相关。这并不意外,因为模型mtf没有任何分量可以单独描述噪声的性质。为了对测量的输入-输出动态和扰动动态进行建模,您将需要使用包含描述噪声成分的元素的模型结构。你可以使用bj,党卫军而且过程命令,分别创建多项式、状态空间和进程结构的模型。其中,这些结构包含捕获噪声行为的元素。
估计过程模型
指定流程模型的结构
在本教程的这一部分中,您将估计一个低阶连续时间传递函数(流程模型)。系统识别工具箱产品支持最多三个极点(可能包含欠阻尼极点)、一个零、一个延迟元件和一个金宝app积分器的连续时间模型。
您必须已经准备好数据,如准备数据.
您可以使用以下估计模型顺序的结果来指定模型的顺序:
对于第一个输入/输出组合,使用:
两极,对应于n一个ARX模型=2。
延迟5,对应nk=5个样本(或2.5分钟)在ARX模型。
对于第二个输入/输出组合,使用:
一极,对应于n一个ARX模型=1。
延迟10,对应nk=10个样本(或5分钟)在ARX模型。
请注意
由于离散时间ARX模型估计的零数量与其对应的连续时间ARX模型之间没有关系,因此您无法估计零的数量。在本教程中,您可以为第一个输入/输出组合指定一个零,而为第二个输出组合指定不为零。
使用idproc命令创建两个模型结构,分别对应输入/输出组合:
Midproc0 = idproc({“P2ZUD”,“P1D”},“TimeUnit”,“分钟”);
单元格数组{“P2ZUD”、“P1D”}指定每个输入/输出组合的模型结构:
“P2ZUD”表示具有两个极点的传递函数(P2),一个零(Z)、欠阻尼(复共轭)极(U)和延迟(D).“P1D”表示具有一个极点的传递函数(P1)和延迟(D).
该示例还使用TimeUnit参数指定使用的时间单位。
查看模型结构和参数值
查看两个结果模型。
midproc0
midproc0 =流程模型与2输入:y = G11 (s) u1 + G12 (s) u2从输入1输出1:1 + Tz * s G11 (s) = Kp * ---------------------- * exp (Td * s) 1 + 2 *ζ* Tw * s + (Tw * s) ^ 2 Kp =南Tw Td =南Tz = =南ζ=南南从输入2输出1:Kp G12 (s ) = ---------- * exp (Td * s) 1 + Tp1 * s Kp Td = =南Tp1 =南南参数化:{“P2DUZ”}{‘P1D}很多免费的系数:8使用“getpvec”、“getcov”参数及其不确定性。现状:由直接构建或改造而产生。不估计。
参数值设置为南因为它们还没有被估计出来。
指定时间延迟的初始猜测
将模型对象的时间延迟属性设置为2.5最小值和5每个输入/输出对的最小值作为初始猜测。另外,设置延迟的上限,因为可以获得良好的初始猜测。
midproc0.Structure .Td(1,1)。值= 2.5;midproc0.Structure .Td(1、2)。Value = 5;midproc0.Structure .Td(1,1)。最大值= 3;midproc0.Structure .Td(1、2)。最大值= 7;
请注意
在设置延迟约束时,必须根据实际时间单位(在本例中为分钟)指定延迟,而不是样本数量。
利用过程估计模型参数
过程是一个迭代过程模型的估计器,这意味着它使用迭代非线性最小二乘算法来最小化代价函数。的成本函数是误差平方和的加权和。
根据它的论点,过程估计不同的黑盒多项式模型。你可以使用过程例如,估计线性连续时间传递函数、状态空间或多项式模型结构的参数。使用过程时,你必须提供一个包含未知参数和估计数据的模型结构作为输入参数。
对于本教程的这一部分,您必须已经定义了模型结构,如中所述指定流程模型的结构.使用midproc0作为模型结构和Ze1作为估计数据:
midproc = procest(Ze1,midproc0);礼物(midproc)
midproc =流程模型与2输入:y = G11 (s) u1 + G12 (s) u2从输入输出“生产”:“ConsumptionRate”1 + Tz * s G11 (s) = Kp * ---------------------- * exp (Td * s) 1 + 2 *ζ* Tw * s + (Tw * s) ^ 2 Kp = -1.1807 + / - 0.29986太瓦= 1.6437 + / - 714.6ζ= 16.036 + / - 6958.9 Td = 2.426 + / - 64.276 Tz = -109.19 + / - 63.731从输入输出“生产”“当前”:Kp G12 (s ) = ---------- * exp (Td * s) 1 + Tp1 * s Kp = 10.264 + / - 0.048404 Tp1 = 2.049 + / - 0.054901 Td = 4.9175 + / - 0.034374参数化:{'P2DUZ'} {'P1D'}自由系数数:8参数及其不确定性使用"getpvec", "getcov"。状态:终止条件:达到的最大迭代次数。迭代次数:20次,函数评估次数:279次,在时域数据“Ze1”上使用PROCEST估计。拟合估计数据:86.2% FPE: 6.081, MSE: 5.984更多信息在模型的“报告”属性。
与离散时间多项式模型不同,连续时间模型允许您估计延迟。在这种情况下,估计的延迟值与您指定的初始猜测值不同2.5而且5,分别。的参数估计值存在较大的不确定性G_1里面(s)指示来自输入的动态1对输出都没有很好地捕捉。
要了解有关估计模型的更多信息,请参见流程模型.
验证模型
在本教程的这一部分中,您将创建一个比较实际输出和模型输出的图。
比较(Zv1 midproc)
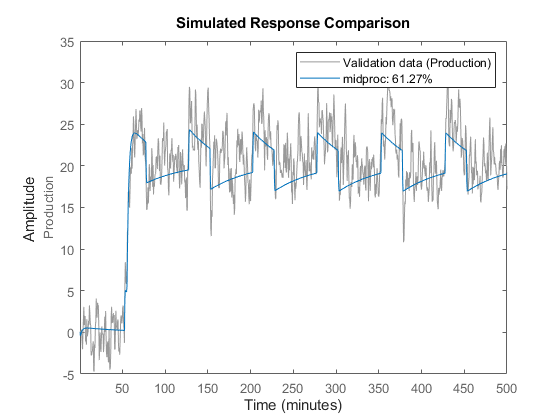
图中显示,模型输出与实测输出基本一致:模型与验证数据之间的一致性为60%。
使用渣油进行残留分析。
渣油(Zv1 midproc)
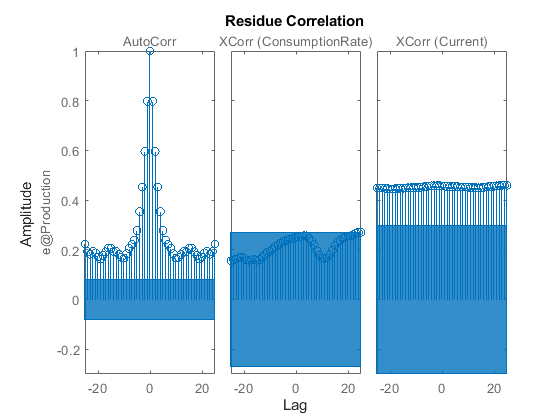
二次输入和残余误差之间的相互关系是显著的。自相关图显示置信区域外的值,表明残差是相关的。
将迭代参数估计算法改为Levenberg-Marquardt算法。
Opt = procestOptions;Opt.SearchMethod =“lm”;midproc1 = procest(Ze1,midproc,Opt);
调整算法属性或指定初始参数猜测并重新运行估计可以改善模拟结果。加入噪声模型可以改善预测结果,但不一定能改善仿真结果。
用噪声模型估计过程模型
本教程的这一部分展示了如何评估流程模型,并在评估中包含噪声模型。包含噪声模型通常会改善模型预测结果,但不一定会改善模拟结果。
使用以下命令指定一阶ARMA噪声:
Opt = procestOptions;Opt.DisturbanceModel =“ARMA1”;midproc2 = procest(Ze1,midproc0,Opt);
你可以打字“距离”而不是“DisturbanceModel”.属性名称不区分大小写,只需包含名称中唯一标识属性的部分。
将得到的模型与测量数据进行比较。
比较(Zv1 midproc2)
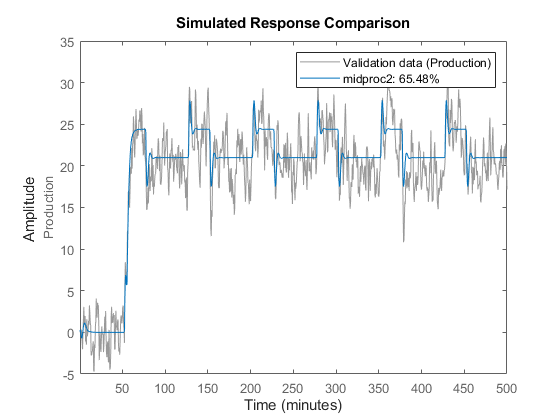
图中显示,模型输出与验证数据输出保持了合理的一致性。
进行残留分析。
渣油(Zv1 midproc2)
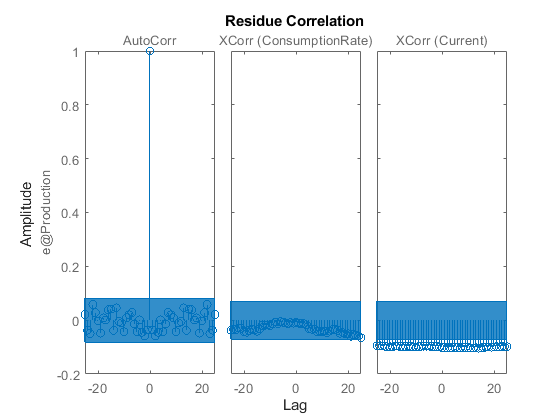
残差图显示自相关值在置信范围内。因此,添加噪声模型会产生不相关的残差。这表明了一个更准确的模型。
估计黑盒多项式模型
估计多项式模型的模型阶
在本教程的这一部分中,您将估计几种不同类型的黑盒输入-输出多项式模型。
您必须已经准备好数据,如准备数据.
您可以使用以下先前估计模型阶数的结果来指定多项式模型的阶数:
对于第一个输入/输出组合,使用:
两极,对应于n一个ARX模型=2。
一个零,对应于nbARX模型=2。
延迟5,对应nk=5个样本(或2.5分钟)在ARX模型。
对于第二个输入/输出组合,使用:
一极,对应于n一个ARX模型=1。
没有零,对应于nbARX模型=1。
延迟10,对应nk=10个样本(或5分钟)在ARX模型。
线性ARX模型的估计
关于ARX模型。对于单输入/单输出系统(SISO), ARX模型结构为:
y (t)表示当时的输出t,u (t)表示当时的输入t,n一个是极点的数目,nb就是0的个数加1,nk输入之前的样本数量是否会影响系统的输出(称为延迟或死时间模型的),以及e (t)就是白噪声干扰。
ARX模型结构不区分单个输入/输出路径的极点:将ARX方程除以一个,其中包含了极点,表明一个出现在两个输入的分母中。因此,您可以设置n一个到每个输入/输出对的极点的和,等于3.在这种情况下。
系统识别工具箱产品估计参数 而且 使用您指定的数据和模型顺序。
使用ARX估计ARX模型。使用arx用快速非迭代方法计算多项式系数arx:
(马克思);“na”3,“注”(2 - 1),“朝鲜”10 [5]);礼物(马克思)显示模型参数不确定信息的%
max =离散时间ARX模型:A(z)y(t) = B(z)u(t) + e(t) A(z) = 1 - 1.027 (+/- 0.02907) z^-1 + 0.1678 (+/- 0.042) z^-2 + 0.01289 (+/- 0.02583) z^-3 B1(z) = 1.86 (+/- 0.189) z^-5 - 1.608 (+/- 0.1888) z^-6 B2(z) = 1.612 (+/- 0.07392) z^-10采样时间:0.5分钟参数化:多项式阶数:na=3 nb=[2 1] nk=[5 10]自由系数数:6使用“polydata”、“getpvec”、“getcov”表示参数及其不确定性。状态:在时域数据“Ze1”上使用ARX估计。拟合估计数据:90.7%(预测焦点)FPE: 2.768, MSE: 2.719更多信息在模型的“报告”属性。
用MATLAB估计多项式一个,B1,B2.每个模型参数的不确定度计算为1个标准偏差,并显示在每个参数值旁边的括号中。
或者,你可以使用下面的简写语法,并将模型顺序指定为单个向量:
马克思= arx(Ze1,[3 2 1 5 10]);
访问模型数据。你估计的模型,马克思,是离散时间的idpoly对象。要获取此模型对象的属性,可以使用得到功能:
(马克思)
A: [1 -1.0267 0.1678 0.0129] B: {[0 0 0 0 0 1.8599 -1.6084] [0 0 0 0 0 0 0 0 0 0 0 0 1.6118]} C: 1 D: 1 F: {[1] [1]} IntegrateNoise: 0变量:'z^-1' IODelay:[0 0]结构:[1x1 pmodel。polynomial] NoiseVariance: 2.7436 InputDelay: [2x1 double] OutputDelay: 0 Ts: 0.5000 TimeUnit: 'minutes' InputName: {2x1 cell} InputUnit: {2x1 cell} InputGroup: [1x1 struct] OutputName: {'Production'} OutputUnit: {'mg/min'} OutputGroup: [1x1 struct]备注:[0x1 string] UserData:[]名称:" SamplingGrid: [1x1 struct]报告:[1x1 idresults.arx]
您可以使用点表示法访问这些属性存储的信息。例如,您可以通过查找的根来计算模型的离散极点一个多项式。
马克思杆=根(马克思。a)
马克思= 0.7953 0.2877 -0.0564
在本例中,您将访问一个多项式使用marx.a.
该模型马克思用三个离散极点描述系统动力学。
提示
你也可以使用极直接计算模型的极点。
学习更多的知识。要了解关于估计多项式模型的更多信息,请参见输入-输出多项式模型.
有关访问模型数据的详细信息,请参见数据提取.
状态空间模型估计
关于状态空间模型。一般状态空间模型结构为:
y (t)表示当时的输出t,u (t)表示当时的输入t,x (t)状态向量是时刻的吗t,e (t)就是白噪声干扰。
您必须指定一个整数作为模型顺序(状态向量的维度)来估计状态空间模型。缺省情况下,延迟时间为1.
系统标识工具箱产品估计状态空间矩阵一个,B,C,D,K使用您指定的模型顺序和数据。
状态空间模型结构是快速估计的一个很好的选择,因为它只包含两个参数:n是杆子的数量(大小一个矩阵),nk就是延迟。
使用n4sid估计状态空间模型。使用n4sid命令指定模型顺序的范围,并评估几个状态空间模型(顺序2到8)的性能:
mn4sid = n4sid(Ze1,2:8,“InputDelay”9 [4]);
该命令使用快速、非迭代(子空间)方法并打开下面的图形。您可以使用这个图来决定哪些状态对输入/输出行为的贡献相对较大,哪些状态的贡献最小。

纵轴是每个状态对模型输入/输出行为贡献多少的相对度量(协方差矩阵奇异值的对数).横轴对应模型顺序n.这张图推荐n = 3,由红色矩形表示。
的选择的顺序订单字段显示推荐的型号订单,3.在本例中,默认为。控件可以更改顺序选择选择的顺序下拉列表。方法中的值选择的顺序字段,并通过单击关闭订单选择窗口应用.
默认情况下,n4sid使用状态空间形式的自由参数化。属性的值可改为估计规范形式SSParameterization财产“规范”.属性指定输入到输出延迟(在示例中)“InputDelay”财产。
mCanonical = n4sid(Ze1,3,“SSParameterization”,“规范”,“InputDelay”9 [4]);礼物(mCanonical);显示模型属性
mCanonical =离散时间识别状态空间模型:x (t + Ts) = x (t) + B K u (t) + e (t) y (t) = C x (t) + D u (t) + e (t) = (x1, x2) x3 x1 1 0 1 0 x2 0 0 x3 0.0737 + / - 0.05919 - -0.6093 + / - 0.1626 - 1.446 + / - 0.1287 B = ConsumptionR当前x1 1.844 + / - 0.175 - 0.5633 + / - 0.122 x2 1.063 + / - 0.1673 2.308 + / - 0.1222 x3 0.2779 + / - 0.09615 - 1.878 + / - 0.1058 C = (x1, x2) x3生产1 0 0 D = ConsumptionR当前生产0 0 K = 0.8674 + / - 0.03169 x1 x2 0.6849 + / - 0.04145 x3 0.5105 + / - 0.04352输入延迟(采样周期):4 9样时间:参数化:带索引的CANONICAL形式:3。馈通:无扰动分量:估计自由系数数:12参数及其不确定性用“idssdata”、“getpvec”、“getcov”表示。状态:在时域数据“Ze1”上使用N4SID估计。拟合估计数据:91.39%(预测焦点)FPE: 2.402, MSE: 2.331更多信息在模型的“报告”属性。
请注意
mn4sid而且mCanonical都是离散时间模型。若要估计连续时间模型,请设置“t”财产0,或使用党卫军命令:
mCT1 = n4sid(Ze1, 3,“t”0,“InputDelay”, [2.5 5]) mCT2 = sest(Ze1, 3,“InputDelay”, [2.5 5])
学习更多的知识。要了解有关估计状态空间模型的更多信息,请参见状态空间模型.
估计Box-Jenkins模型
关于Box-Jenkins模型。一般的Box-Jenkins (BJ)结构为:
要估计BJ模型,需要指定参数nb,nf,nc,nd,nk.
ARX模型结构不区分单个输入/输出路径的极点,而BJ模型在将扰动的极点和零点与系统动力学的极点和零点分开建模方面提供了更大的灵活性。
用聚类估计BJ模型。你可以使用聚来估计BJ模型。聚是一种迭代方法,一般语法如下:
Polyest (data,[na nb nc nd nf nk]);
为了估计BJ模型,输入:
Na = 0;Nb = [2 1];Nc = 1;Nd = 1;Nf = [2 1];Nk = [5 10];mbj = polyest(Ze1,[na nb nc nd nf nk]);
这个命令指定nf = 2,nb = 2,nk = 5对于第一个输入,和nf = nb = 1而且nk = 10对于第二个输入。
显示模型信息。
礼物(mbj)
mbj =离散BJ模型:y (t) = (B (z) / F (z)] u (t) + (C (z) / D (z)] e (t) B1 (z) = 1.823 (+ / - 0.1792) z ^ 5 - 1.315 (+ / - 0.2367) z ^ 6 B2 (z) = 1.791 (+ / - 0.06431) z ^ -10 C (z) = 1 + 0.1068 (+ / - 0.04009) z ^ 1 D (z) = 1 - 0.7452 (+ / - 0.02694) z ^ 1 F1 (z) = 1 - 1.321 (+ / - 0.06936) z ^ 1 + 0.5911 (+ / - 0.05514) z ^ 2 F2 (z) = 1 - 0.8314 (+ / - 0.006441) z ^ 1样品时间:0.5分钟参数化:多项式订单:nb =[2 1]数控= 1 nd = 1 nf = [2 1] nk = 10[5]很多免费的系数:8使用“polydata”、“getpvec”、“getcov”表示参数及其不确定性。状态:终止条件:接近(局部)最小值,(范数(g) < tol)..迭代次数:6次,函数评估次数:13次,在时域数据“Ze1”上使用POLYEST估计。拟合估计数据:90.75%(预测焦点)FPE: 2.733, MSE: 2.689更多信息在模型的“报告”属性。
每个模型参数的不确定度计算为1个标准偏差,并显示在每个参数值旁边的括号中。
的多项式C而且D分别给出噪声模型的分子和分母。
学习更多的知识。要了解有关识别输入-输出多项式模型(如BJ)的更多信息,请参见输入-输出多项式模型.
比较模型输出和测量输出
比较ARX、状态空间和Box-Jenkins模型的输出与测量的输出。
比较(Zv1,马克思,mn4sid mbj)
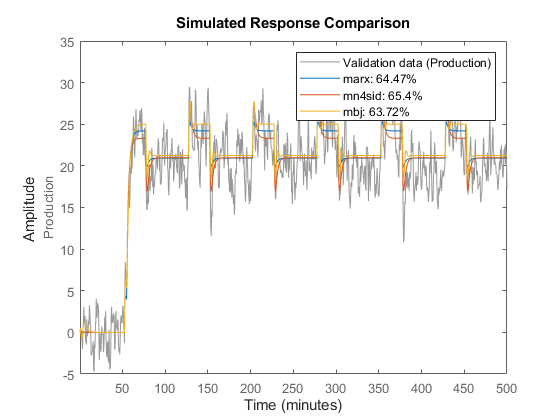
比较将验证数据集中的测量输出与模型的模拟输出绘制成图。来自验证数据集的输入数据作为模型的输入。
在ARX、状态空间和Box-Jenkins模型上执行残差分析。
渣油(Zv1,马克思,mn4sid mbj)
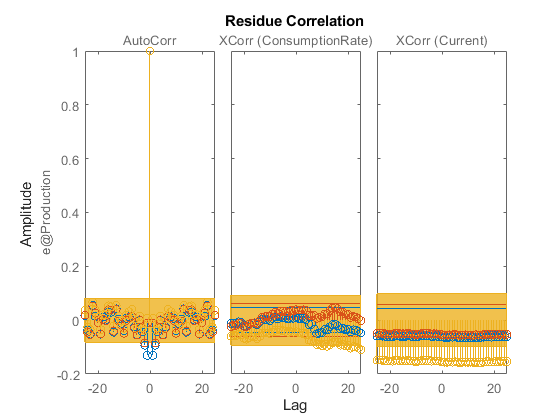
所有三个模型都能很好地模拟输出,并且具有不相关的残差。因此,选择ARX模型,因为它是三个输入-输出多项式模型中最简单的,并能充分捕捉过程动态。
模拟和预测模型输出
模拟模型输出
在本教程的这一部分中,您将模拟模型输出。您必须已经创建了连续时间模型midproc2,详见估计过程模型.
模拟模型输出需要以下信息:
向模型输入值
模拟的初始条件(也称为初始状态)
例如,下面的命令使用iddata而且idinput命令来构造输入数据集,并使用sim卡模拟模型输出:
为模拟创建输入U = iddata([],idinput([200 2]),“t”, 0.5,“TimeUnit”,“最小值”);模拟将初始条件设为零的响应ysim_1 = sim(midproc2,U);
为了使模型的模拟响应与相同输入的测量输出之间的拟合最大化,您可以计算与测量数据对应的初始条件。用,可得到最佳拟合初始条件findstates关于估计模型的状态空间版本。下面的命令估计初始状态x0从数据集中Zv1:
%计算初始状态所需模型的状态空间版本Midproc2_ss = idss(midproc2);X0est = findstates(midproc2_ss,Zv1);
接下来,使用从数据估计的初始状态来模拟模型。
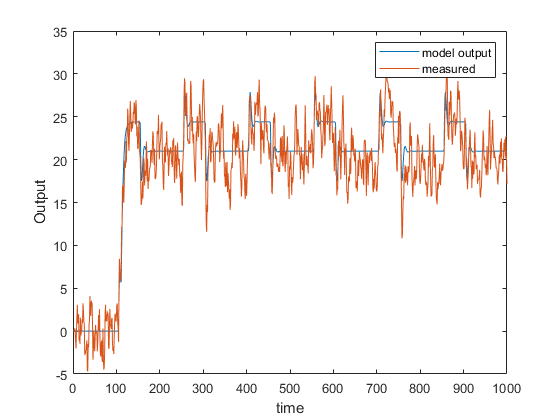
%模拟输入Usim = Zv1(:,[],:);Opt = simOptions(“InitialCondition”, x0);ysim_2 = sim(midproc2_ss,Usim,Opt);
在图上比较模拟输出和实测输出。
图([ysim_2的阴谋。y, Zv1.y])模型输出的,“测量”})包含(“时间”), ylabel (“输出”)
预测未来产量
许多控制设计应用程序要求您使用过去的输入/输出数据来预测动态系统的未来输出。
例如,使用预测提前5步预测模型响应:
预测(midproc2 Ze1 5)
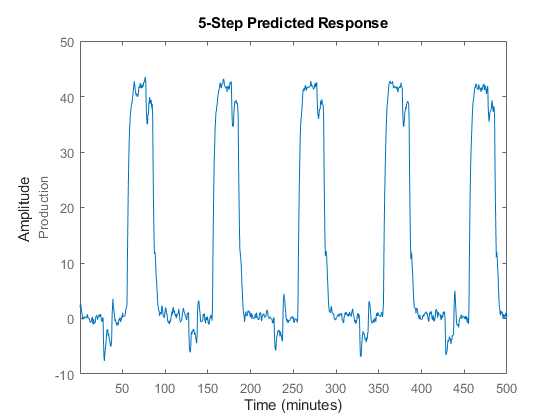
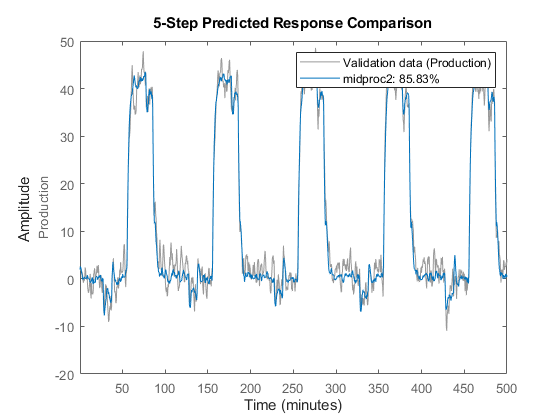
将预测值与实测值进行比较。第三个论点比较指定提前五步的预测。当您没有指定第三个参数时,比较假设一个无限的预测范围,并模拟模型输出。
比较(Ze1 midproc2 5)
使用体育计算预测误差犯错之间的预测产量midproc2和测量的输出。然后,绘制误差谱使用光谱命令。
[Err] = pe(midproc2,Zv1);谱(spa(呃,[],logspace (2200)))

预测误差以1个标准差置信区间绘制。由于扰动的高频性质,在高频处误差更大。
您也可以从以下列表中选择一个网站: