 Cleve's Corner:数学和计算上的Clyver
Cleve's Corner:数学和计算上的Clyver 罗兰关于MATLAB的艺术
罗兰关于MATLAB的艺术 用MATLAB进行图像处理
用MATLAB进行图像处理 人在仿真软件金宝app
人在仿真软件金宝app 深度学习
深度学习 开发区域
开发区域 斯图尔特的MATLAB视频
斯图尔特的MATLAB视频 在标题后面
在标题后面 本周文件交换精选
本周文件交换精选 汉斯在物联网
汉斯在物联网 学生休息室
学生休息室 初创公司,加速器和企业家
初创公司,加速器和企业家 Matlab社区
Matlab社区 MATLABユーザーコミュニティー
MATLABユーザーコミュニティー基于gpu和MATLAB的深度学习
大家好!虽然这篇文章中的大部分信息都是正确的,但这是一篇2017年的原创文章,gpu的世界变化很快。我鼓励你在这里查看gpu的更新资源:https://explore.mathworks.com/all-about-gpus.
Matlab用户向我们询问关于GPU的很多问题,今天我想回答其中一些。我希望你能带来一种基本意义,如何选择GPU卡,以帮助您在Matlab中深入学习。
我向本·托多夫求助。我第一次见到Ben大约是在12年前,当时他给图像处理工具箱开发提供了很多关于我们功能的反馈。从那时起,他进入了软件开发,现在他领导的团队负责GPU,分布式,和高阵列支持MATLAB和并行计算工具箱。金宝app

内容
获取关于GPU卡的信息
这个函数GPudevice.告诉你关于GPU硬件的信息。我让本给我介绍一下GPudevice.在我的电脑上。
GPudevice.
ans = CUDADevice属性:名称:“泰坦Xp”指数:1 ComputeCapability:“6.1”SupportsDouble: 1 DriverVersi金宝appon: 9 ToolkitVersion: 8 MaxThreadsPerBlock: 1024 MaxShmemPerBlock: 49152 MaxThreadBlockSize: [1024 1024 64] MaxGridSize: [2.1475 e + 09年65535 65535]SIMDWidth: 32 TotalMemory: 1.2885 e + 10 AvailableMemory: 1.0425 e + 10 MultiprocessorCount:30 ClockRateKHz: 1582000 ComputeMode: 'Default' GPUOverlapsTransfers: 1 KernelExecutionTimeout: 1 CanMapHostMemory: 1 Device金宝appSupported: 1 DeviceSelected: 1
本:“那是泰坦Xp卡。你的GPU相当不错,比我的要好得多,至少在深度学习方面。”(我将在下面解释这一评论。)
“指数为1意味着NVIDIA驱动认为这个GPU是你电脑上安装的最强大的GPU。和ComputeCapability指此卡支持的计算能力的生成。金宝app第六代被称为帕斯卡。”在R2017b发布,GPU计算与MATLAB和并行计算工具箱需要一个ComputeCapability至少3.0。
其他资料由GPudevice.对于编写低级GPU计算例程或故障排除的开发人员来说非常有用。不过,在比较gpu时,还有一个数字可能会对您有所帮助。的MultiProcessorcount.实际上是GPU上的芯片数量。“相同一代内的高端卡和低端卡之间的差异通常会归结为可用的芯片数量。”
Gpubench.
下一件事是Ben和我讨论的是GPubench的输出,由Ben的团队维护的GPU性能测量工具。你可以从中得到它MATLAB中央档案交换.以下是报告的部分内容:

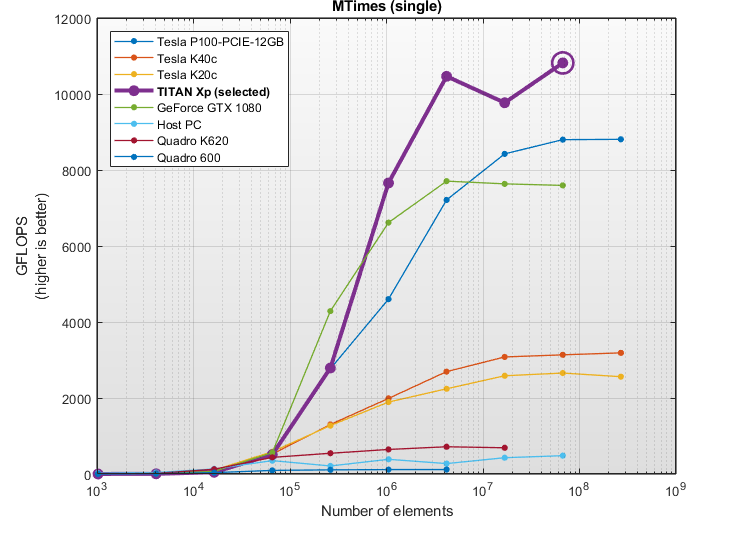
GFLOP是一个计算速度的单位。1 GFLOP每秒大约10亿浮点操作。该报告测量双精度和单精度浮点的计算速度。一些卡在双精度下擅长,有些卡在单级精度下做得更好。该报告显示顶部最好的双重精度卡,因为这对于一般Matlab计算最重要。
该报告包括三个不同的计算基准:MTimes(矩阵乘法)、反斜杠(线性系统求解)和FFT。矩阵乘法基准最适合测量纯计算速度,因此它的GFLOP数最高。另一方面,FFT和反斜杠基准测试涉及更多的计算和I/O的混合,因此报告的GFLOP率较低。
在双精度计算方面,我的Titan Xp卡比我的CPU(上表中的主机)要好,但它绝对比上面列出的卡慢。那么,为什么本告诉我我的卡片对深度学习很有帮助呢?因为报告的右边一栏,重点是单精度计算.对于图像处理和深度学习来说,单精度速度比双精度速度更重要。
Titan Xp在单精度计算方面的速度非常快,使用大型矩阵进行矩阵乘法的速度高达11000 GFLOPS。如果您感兴趣,可以深入GPUBench报告获取更多细节,如下所示:
NVIDIA GPU卡的类型
我稍微帮忙了解NVIDIA制作的各种各样的GPU卡。“嗯,为了深入学习,你可以专注于三行卡片:GeForce,Titan和Tesla。GeForce卡是最便宜的,具有体面的计算性能,但你必须记住他们不起作用如果您使用的是远程桌面软件。Titan是一个汤边版本的GeForce,它确实具有远程桌面支持。并且Tesla卡旨在为双重精度应用中的计算服务器的高性能卡。“金宝app
比较CPU和GPU的深度学习速度
神经网络工具箱和其他产品中的许多深度学习函数现在支持一个名为下载188bet金宝搏金宝app“ExecutionEnvironment”.选择是:“汽车”,“cpu”,“图形”,'多gpu','平行线'.您可以使用此选项来尝试某些网络培训和预测计算,以测量您自己计算机对深度学习的实际GPU影响。
我将使用此选项进行实验“训练卷积神经网络用于回归”的例子.这里我只做训练步骤,不做完整的例子。首先,我将使用我的GPU。
选择= trainingOptions ('sgdm','italllearnrate', 0.001,...“MaxEpochs”15);网= trainNetwork (trainImages、trainAngles层,选择);
单个GPU培训。初始化图像正常化。| ==========================================================================================|时代|迭代|经过时间的时间迷你批量|迷你批量|基础学习| | | | (seconds) | Loss | RMSE | Rate | |=========================================================================================| | 1 | 1 | 0.01 | 352.3131 | 26.54 | 0.0010 | | 2 | 50 | 0.75 | 114.6249 | 15.14 | 0.0010 | | 3 | 100 | 1.40 | 69.1581 | 11.76 | 0.0010 | | 4 | 150 | 2.04 | 52.7575 | 10.27 | 0.0010 | | 6 | 200 | 2.69 | 54.4214 | 10.43 | 0.0010 | | 7 | 250 | 3.33 | 40.6091 | 9.01 | 0.0010 | | 8 | 300 | 3.97 | 29.9065 | 7.73 | 0.0010 | | 9 | 350 | 4.63 | 28.4160 | 7.54 | 0.0010 | | 11 | 400 | 5.28 | 28.4920 | 7.55 | 0.0010 | | 12 | 450 | 5.92 | 21.7896 | 6.60 | 0.0010 | | 13 | 500 | 6.56 | 22.7835 | 6.75 | 0.0010 | | 15 | 550 | 7.20 | 24.8388 | 7.05 | 0.0010 | | 15 | 585 | 7.66 | 17.7162 | 5.95 | 0.0010 | |=========================================================================================|
您可以在“Elapsed Time”列中看到,这个简单示例的训练大约花了8秒。
现在让我们只使用CPU重复训练。
选择= trainingOptions ('sgdm','italllearnrate', 0.001,...“MaxEpochs”15岁的“ExecutionEnvironment”,“cpu”);网= trainNetwork (trainImages、trainAngles层,选择);
初始化图像正常化。|=========================================================================================| | 时代| |迭代时间| Mini-batch | Mini-batch |基地学习| | | | | |(秒)损失RMSE |率 | |=========================================================================================| | 1 | 1 | 0.17 | 354.9253 | 26.64 | 0.0010 | | 2| 50 | 6.74 | 117.6613 | 15.34 | 0.0010 | | 3 | 100 | 13.31 | 92.0581 | 13.57 | 0.0010 | | 4 | 150 | 20.10 | 57.7432 | 10.75 | 0.0010 | | 6 | 200 | 26.66 | 50.4582 | 10.05 | 0.0010 | | 250 | | 33.35 | 35.4191 | 8.42 | 0.0010 | | 300 | | 40.06 | 30.0699 | 7.75 | 0.0010 | | 350 | | 46.70 | 24.5073 | 7.00 | 0.0010 | | 400 | | 53.35 | 28.2483| 7.52 | 0.0010 | | 450 | | 59.95 | 23.1092 | 6.80 | 0.0010 | | 500 | | 66.54 | 18.9768 | 6.16 | 0.0010 | | 550 | | 73.10 | 15.1666 | 5.51 | 0.0010 | | 585 | | 77.78 | 20.5303 | 6.41 | 0.0010 | |=========================================================================================|
比使用GPU的培训花了大约需要10倍。对于现实网络,我们期望差异更大。拥有更强大的深度学习网络需要数小时或几天训练,您可以了解为什么我们建议使用良好的GPU进行大量的深度学习工作。
我希望这些信息对你有帮助。祝您在使用MATLAB建立自己的深度学习系统时好运!
PS。谢谢,本!
- 类别:
- 深度学习







评论
要留下评论,请点击在这里登录到您的MathWorks帐户或创建一个新帐户。