 克利夫角:克利夫·莫尔谈数学和计算机
克利夫角:克利夫·莫尔谈数学和计算机 罗兰关于MATLAB的艺术
罗兰关于MATLAB的艺术 用MATLAB进行图像处理
用MATLAB进行图像处理 人在仿真软件金宝app
人在仿真软件金宝app 深度学习
深度学习 开发区域
开发区域 斯图尔特的MATLAB视频
斯图尔特的MATLAB视频 在标题后面
在标题后面 本周文件交换精选
本周文件交换精选 汉斯在物联网
汉斯在物联网 学生休息室
学生休息室 初创企业、加速器和企业家
初创企业、加速器和企业家 MATLAB社区
MATLAB社区 MATLABユーザーコミュニティー
MATLABユーザーコミュニティー定义自己的网络层
注:帖子更新于2018年9月27日,以纠正在实现向后函数时出现的拼写错误。
R2017b的一个新的神经网络工具箱特性是定义自己的网络层的能力。今天我将向你展示如何制作指数线性单元(ELU)层。
乔帮我处理了今天的邮件。Joe是少数几个在MathWorks工作的时间比我长的开发人员之一。事实上,他是我来这里应聘时面试过我的人之一。在过去的几年里,我有幸与Joe在MATLAB设计的许多方面密切合作。他真的很喜欢摆弄深度学习网络。
乔偶然发现了这份报纸基于指数线性单元(ELUs)的快速精确深度网络学习通过Clevert, Unterthiner和Hichreiter,他想用R2017b制作一个ELU层。
$ f (x) = \左\{\{数组}{你}开始x & x > 0 \ \ \α(e ^ x - 1)和x \ leq 0 \{数组}\正确。$结束
让我们将ELU形状与其他几种常用的激活函数进行比较。
α1 = 1;elu_fcn = @ x (x)。* (x > 0) +α1 * (exp (x) - 1) * (x < = 0);alpha2 = 0.1;Leaky_relu_fcn = @(x) alpha2*x。*(x <= 0) + x.*(x <= 0);Relu_fcn = @(x) x.*(x > 0);fplot (elu_fcn (-10 3),“线宽”, 2)在fplot (leaky_relu_fcn (-10 3),“线宽”2) fplot (relu_fcn (-10 3),“线宽”, 2)从甘氨胆酸ax =;斧子。XAxisLocation =“起源”;斧子。YAxisLocation =“起源”;盒子从传奇({“ELU”,“漏ReLU”,“ReLU”},“位置”,“西北”)

Joe想要创造一个ELU层,每个通道有一个学到的alpha值。他按照书中概述的程序行事定义一个带有可学习参数的图层使用神经网络工具箱创建一个ELU层。
下面是带有可学习参数的图层模板。我们将探索如何填充这个模板来创建一个ELU层。
classdefmyLayer < nnet.layer.Layer属性%(可选)图层属性%图层属性到这里结束属性(可学的)%(可选)层可学习参数%图层学习参数到这里结束方法函数层= myLayer ()%(可选)创建一个myLayer%该函数必须与层名相同%层构造函数在这里结束函数Z =预测(层,X)%在预测时间通过层转发输入数据%输出结果%%的输入:% layer -要转发的层% X -输入数据%输出:% Z -层前向函数的输出%用于预测的层前向函数在这里结束函数[Z,内存]= forward(layer, X)%(可选)在训练时通过层转发输入数据%时间并输出结果和一个内存值%%的输入:% layer -要转发的层% X -输入数据%输出:% Z -层前向函数的输出% memory -可用于的内存值%向后传播%用于训练的图层正向功能在这里结束函数[dLdX, dLdW1,...=向后(layer, X, Z, dLdZ, memory)将损失函数的导数向后传递到%的层%%的输入:%图层-图层向后传播通过% X -输入数据% Z -层前向函数的输出% dLdZ -梯度从更深的层传播% memory -可以使用的内存值%向后传播%输出:% dLdX -损失对…的导数%的输入数据% dLdW1,…,dLdWn - Derivatives of the loss with respect to each%可学的参数%图层向后函数在这里结束结束结束
对于带有可学习alpha参数的ELU层,这里有一种方法来编写构造函数和可学的属性块。
classdefeluLayer < nnet.layer.Layer属性(可学的)α结束方法函数layer = eluLayer(num_channels,name) layer。类型=“指数线性单元”;%指定传入的图层名称。如果Nargin > 1层。Name =名称;结束给这个层一个有意义的描述。层。描述=“指数线性单位与”+...num_channels +“通道”;%初始化可学习的alpha参数。层。α=兰德(1,1,num_channels);结束
的预测函数是我们实现激活函数的地方。记住它的数学形式:
$ f (x) = \左\{\{数组}{你}开始x & x > 0 \ \ \α(e ^ x - 1)和x \ leq 0 \{数组}\正确。$结束
注意:表达式(exp (min (X, 0)) - 1)在预测函数中这样写是为了避免计算大的正数的指数,这可能导致无穷大和nan出现。
函数Z =预测(层,X)%在预测时间通过层转发输入数据%输出结果%%的输入:% layer -要转发的层% X -输入数据%输出:% Z -层前向函数的输出%表示计算的矢量形式允许它%直接在GPU上执行。Z = (x .* (x > 0)) +...(exp(min(X,0)) - 1) .*(X <= 0));结束
的落后的函数实现了损失函数的导数,这是训练所需要的。的定义一个带有可学习参数的图层文档页解释了如何获得所需的数量。
函数[dLdX, ddalpha] =向后(layer, X, Z, dLdZ, ~)将损失函数的导数向后传递到%的层%%的输入:%图层-图层向后传播通过% X -输入数据% Z -层前向函数的输出% dLdZ -梯度从更深的层传播% memory -可以使用的内存值%向后传播[未使用]%输出:% dLdX -损失的导数%对输入数据% dLdAlpha -损失的衍生%相对于%原表达式:% dLdZ = (dLdZ .* (X > 0)) +…% (dLdZ .* (layer + Z) .* (X <= 0));%%优化表达式:* ((X > 0) +...((层。* (X <= 0));= (exp(min(X,0)) - 1));图像行和列的总和。dLdAlpha =总和(sum (dLdAlpha, 1), 2);汇总所有的观察在小批。dLdAlpha = (dLdAlpha, 4)之和;结束
这就是我们的图层所需要的。我们不需要实现向前因为我们的图层没有记忆,也不需要做任何特殊的训练。
加载样本数字训练集,并显示其中的一张图像。
[XTrain, YTrain] = digitTrain4DArrayData;imshow (XTrain (::,:, 1010),“InitialMagnification”,“健康”) YTrain (1010)
2 .单词conduct联想记忆

制作一个使用我们新的ELU层的网络。
层= [...imageInputLayer([28 28 1])卷积2dlayer (5,20) batchNormalizationLayer eluLayer(20) fulllyconnectedlayer (10) softmaxLayer classificationLayer];
培训网络。
选择= trainingOptions (“个”);网= trainNetwork (XTrain、YTrain层,选择);
单GPU训练。初始化图像正常化。|=========================================================================================| | 时代| |迭代时间| Mini-batch | Mini-batch |基地学习| | | | | | |精度损失速率(秒) | |=========================================================================================| | 1 | 1 | 0.03 | 2.5173 | 5.47% | 0.0100 | |2 | 50 | 0.63 | 0.4548 | 85.16% | 0.0100 | | 3 | 100 | 1.20 | 0.1550 | 96.88% | 0.0100 | | 4 | 150 | 1.78 | 0.0951 | 99.22% | 0.0100 | | 6 | 200 | 2.37 | 0.0499 | 99.22% | 0.0100 | | 250 | | 2.96 | 0.0356 | 100.00% | 0.0100 | | 300 | | 3.55 | 0.0270 | 100.00% | 0.0100 | | 350 | | 4.13 | 0.0168 | 100.00% | 0.0100 | | 400 | | 4.74 | 0.0145 |100.00% | 0.0100 | | 12 | 450 | 5.32 | 0.0118 | 100.00% | 0.0100 | | 13 | 500 | 5.89 | 0.0119 | 100.00% | 0.0100 | | 15 | 550 | 6.45 | 0.0074 | 100.00% | 0.0100 | | 16 | 600 | 7.03 | 0.0079 | 100.00% | 0.0100 | | 17 | 650 | 7.60 | 0.0086 | 100.00% | 0.0100 | | 18 | 700 | 8.18 | 0.0065 | 100.00% | 0.0100 | | 20 | 750 | 8.76 | 0.0066 | 100.00% | 0.0100 | | 21 | 800 | 9.34 | 0.0052 | 100.00% | 0.0100 | | 22 | 850 | 9.92 | 0.0054 | 100.00% | 0.0100 | | 24 | 900 | 10.51 | 0.0051 | 100.00% | 0.0100 | | 25 | 950 | 11.12 | 0.0044 | 100.00% | 0.0100 | | 26 | 1000 | 11.73 | 0.0049 | 100.00% | 0.0100 | | 27 | 1050 | 12.31 | 0.0040 | 100.00% | 0.0100 | | 29 | 1100 | 12.93 | 0.0041 | 100.00% | 0.0100 | | 30 | 1150 | 13.56 | 0.0040 | 100.00% | 0.0100 | | 30 | 1170 | 13.80 | 0.0043 | 100.00% | 0.0100 | |=========================================================================================|
在我们的测试集中检查网络的准确性。
[XTest, YTest] = digitTest4DArrayData;YPred = classification (net, XTest);精度=(欧美= = YPred) /元素个数之和(欧美)
精度= 0.9872
看看测试集中的一张图片,看看它是如何被网络分类的。
k = 1500;imshow (XTest (:,:,:, k),“InitialMagnification”,“健康”) YPred (k)
2 .单词conduct联想记忆

现在,您已经了解了如何定义自己的层、将其包含在网络中并对其进行训练。
- 类别:
- 深度学习


另请参阅
-
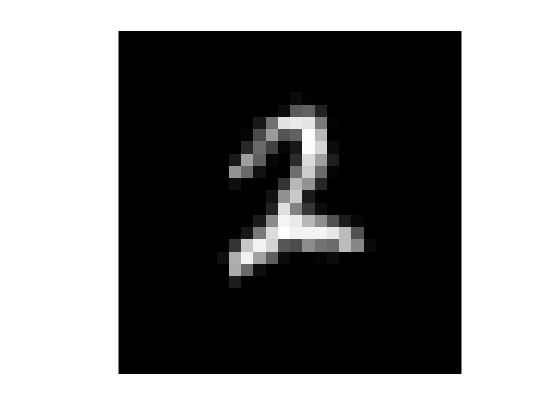
定义自己的网络层(重述)
博客
-
创建一个简单的DAG网络
博客
-
-
-

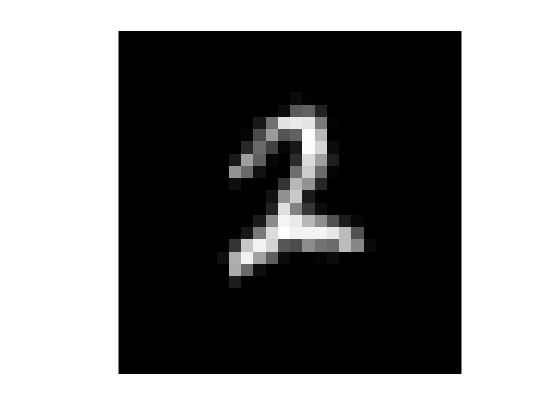

评论
要留下评论,请点击在这里登录到您的MathWorks帐户或创建一个新帐户。