结合深度学习网络,提高预测精度。
下面这篇文章来自Maria Duarte Rosa,她写了一篇很棒的文章神经网络特征可视化,讨论如何提高模型预测的准确性。
- 您是否尝试过从头开始训练不同的架构?
- 你试过不同的体重初始化吗?
- 你试过使用不同的预训练模型进行迁移学习吗?
- 你是否运行了交叉验证以找到最好的超参数?
如果你对这些问题中的任何一个回答是,这篇文章将告诉你如何利用你训练过的模型来提高预测的准确性。即使你对这四个问题的回答都是否定的,下面的简单技巧仍然可以帮助你提高预测的准确性。
首先,我们来谈谈整体学习。
什么是整体学习?
集成学习或模型集成,是一套完善的机器学习和统计技术[LINK:
https://doi.org/10.1002/widm.1249],通过组合不同的学习算法来提高预测性能。将不同模型的预测组合起来,通常比组成整体的任何单个模型都更准确。集成方法有不同的风格和复杂程度(有关回顾,请参阅)
https://arxiv.org/pdf/1106.0257.pdf),但这里我们着重于结合多个深度学习网络的预测,这些网络之前已经经过训练。
不同的网络会犯不同的错误,这些错误的组合可以通过模型集成加以利用。尽管在深度学习的文献中不像在传统机器学习研究中那么受欢迎,但用于深度学习的模型集成已经取得了令人印象深刻的结果,特别是在非常受欢迎的竞赛中,如ImageNet和其他Kaggle挑战。这些竞赛的获胜者通常是深度学习架构的集合。
在本文中,我们将重点介绍三种结合不同深度神经网络预测的简单方法:
- 平均:对来自不同网络的所有预测(softmax层的输出)的简单平均值
- 加权平均:权重与单个模型的性能成正比。例如,对最佳模型的预测可以加权2,而其他模型没有权重;
- 多数表决:对于每个测试观察,预测是所有预测中最频繁的一类
我们将使用两个示例来说明这些技术如何在以下情况下提高准确性:示例1:结合从头开始训练的不同体系结构。例2:结合不同的预训练模型进行迁移学习。尽管我们选择了两个特定的用例,但这些技术适用于训练了多个深度学习网络的大多数情况,包括在不同数据集上训练的网络。
例子1 -结合不同的架构训练从头开始
这里我们使用CiFAR-10数据集从头开始训练6种不同的ResNet架构。我们遵循这个例子
//www.tatmou.com/help/deeplearning/examples/train-residual-network-for-image-classification.html而不是训练一个单一的体系结构,我们使用以下6种组合来改变单元的数量和网络宽度:和netWidth =[12 32 16 24 9 6]。我们使用与示例中相同的训练选项来训练每个网络,并估计它们各自的验证错误(
验证误差= 100 -预测精度):
个人验证错误:
| 网络1:16.36% |
| 网络2:7.83% |
| 3: 9.52% |
| 4: 7.68% |
| 5: 10.36% |
| 6: 12.04% |
然后我们计算了三种不同的集成技术的误差:
模型整体的错误:
| 平均:6.79% |
| 加权平均:6.79%(网络4计算了两次)。 |
| 多数投票:7.16% |
这些数字的快速图表:
图;酒吧(example1Results);title('示例1:预测错误(%)');xticklabels({'网络1','网络2','网络3','网络4','网络5','网络6',…'Average', 'Weighted Average', 'Majority vote'});xtickangle (40)
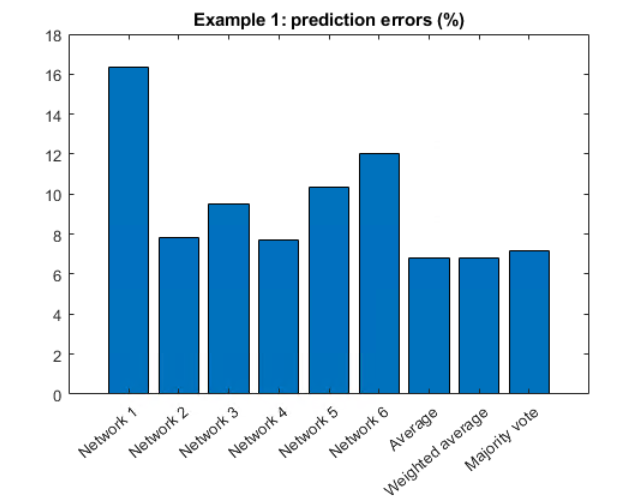
集合预测的误差比任何单个模型的误差都小。差异很小,但在10000张图片中,与最佳的个体模型相比,这意味着89张图片现在被正确分类了。我们可以看到这些图片中的一些例子:
%绘制一些数据(错误分类为最佳模型)加载Example1Results。垫图;for i = 1:4 subplot(2,2,i);imshow(dataVal(:,:,: i)) title(sprintf('Best model: %s / Ensemble: %s',bestModelPreds(i),ensemblePreds(i))) end . for i = 1:4 subplot(2,2,i)

例2 -结合不同的预训练模型进行迁移学习
在这个例子中,我们再次使用CiFAR-10数据集,但这次我们使用不同的迁移学习预训练模型。模型最初是在ImageNet上训练的,可以作为支持包下载[LINK:金宝app
//www.tatmou.com/matlabcentral/profile/authors/8743315-mathworks-deep-learning-toolbox-team].我们使用了googlenet, squeezenet, resnet18, xception和mobilenetv2,并遵循迁移学习示例[LINK:
//www.tatmou.com/help/deeplearning/examples/train-deep-learning-network-to-classify-new-images.html]
个人验证错误:
| googlenet: 7.23% |
| squeezneet: 12.89% |
| resnet18: 7.75% |
| xception: 3.92% |
| mobilenetv2: 6.96% |
模型整体的错误:
| 平均:3.56% |
| 加权平均值:3.28%(例外两次计算)。 |
| 多数投票:4.04% |
%绘制误差图;条形图(example2Results);title('示例2:预测错误(%)');xticklabels({'GoogLeNet','SqueezeNet','ResNet-18', 'Xception', 'MobileNet-v2',…'Average', 'Weighted Average', 'Majority vote'});xtickangle (40)

再一次,集合预测的误差比任何单个模型都要小,并且有64张图片被正确分类。这些包括:
%绘制一些数据(错误分类为最佳模型)加载Example2Results。垫图;for i = 1:4 subplot(2,2,i);imshow(dataVal(:,:,: i)) title(sprintf('Best model: %s / Ensemble: %s',bestModelPreds(i),ensemblePreds(i))) end . for i = 1:4 subplot(2,2,i)

我还应该知道什么?
模型集成可以显著增加预测时间,这使得它在推理时间成本高于做出错误预测成本的应用程序中不切实际。
另一件需要注意的事情是,性能并不会随着网络数量的增加而单调增加。通常,随着这个数字的增加,训练时间显著增加,但结合所有模型的回报减少。
对于应该合并多少个网络,并没有一个神奇的数字。这严重依赖于网络、数据和计算资源。话虽如此,在一个集合中,模型的多样性越多,性能就越好。
希望这对你有用——你尝试过或想过尝试集合学习吗?请在下方留言。
 克利夫角:克利夫·莫尔谈数学和计算机
克利夫角:克利夫·莫尔谈数学和计算机 罗兰关于MATLAB的艺术
罗兰关于MATLAB的艺术 用MATLAB进行图像处理
用MATLAB进行图像处理 人在仿真软件金宝app
人在仿真软件金宝app 深度学习
深度学习 开发区域
开发区域 斯图尔特的MATLAB视频
斯图尔特的MATLAB视频 在标题后面
在标题后面 本周文件交换精选
本周文件交换精选 汉斯在物联网
汉斯在物联网 学生休息室
学生休息室 初创企业、加速器和企业家
初创企业、加速器和企业家 MATLAB社区
MATLAB社区 MATLABユーザーコミュニティー
MATLABユーザーコミュニティー 集合预测的误差比任何单个模型的误差都小。差异很小,但在10000张图片中,与最佳的个体模型相比,这意味着89张图片现在被正确分类了。我们可以看到这些图片中的一些例子:
集合预测的误差比任何单个模型的误差都小。差异很小,但在10000张图片中,与最佳的个体模型相比,这意味着89张图片现在被正确分类了。我们可以看到这些图片中的一些例子:
 再一次,集合预测的误差比任何单个模型都要小,并且有64张图片被正确分类。这些包括:
再一次,集合预测的误差比任何单个模型都要小,并且有64张图片被正确分类。这些包括:







评论
要留下评论,请点击在这里登录到您的MathWorks帐户或创建一个新帐户。