情节
可视化贝叶斯线性回归模型参数的先验和后验密度
语法
描述
图(或PosteriorMdl)图(图中参数的后验或先验分布贝叶斯线性回归模型PriorMdl)PosteriorMdl或PriorMdl,分别。情节将每个参数的子图添加到一个图形,并在调用时覆盖相同的图形情节很多次了。
图(在同一子图中绘制后验分布和先验分布。PosteriorMdl,PriorMdl)情节使用蓝色实线表示后验密度,红色虚线表示先验密度。
pointsUsed=情节(___)情节用于评价子样地的密度。
[还返回计算密度的值。pointsUsed,posteriorDensity,priorDensity] = plot(___)
如果指定一个模型,则情节返回的密度值PosteriorDensity.否则,情节返回的后验密度值PosteriorDensity先验密度值PriorDensity.
[返回包含分布的图形的图形句柄。pointsUsed,posteriorDensity,priorDensity,FigureHandle] = plot(___)
例子
绘制先验和后验分布
考虑预测美国实际国民生产总值(gdp)的多元线性回归模型(GNPR)采用工业生产指数(新闻学会)、总就业人数(E)和实际工资(或者说是).
对所有 , 是一系列均值为0,方差为0的独立高斯扰动吗 .
假设这些先验分布:
. 4 × 1向量的均值是多少 是一个4乘4的正定协方差矩阵。
. 和 分别是逆伽马分布的形状和比例。
这些假设和数据似然暗示了一个正态-逆伽马共轭模型。
为线性回归参数创建一个正态-逆伽马共轭先验模型。指定预测器的数量p还有变量名。
P = 3;VarNames = [“他们”“E”“福”];PriorMdl = bayeslm(p,“ModelType”,“共轭”,“VarNames”, VarNames);
PriorMdl是一个conjugateblm贝叶斯线性回归模型对象表示回归系数和扰动方差的先验分布。
绘制先验分布。
情节(PriorMdl);
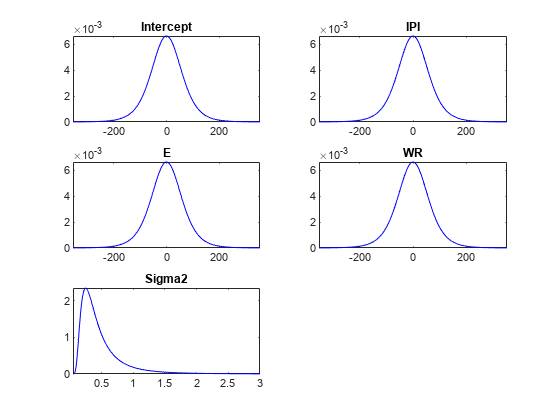
情节绘制截距、回归系数和扰动方差的边际先验分布。
假设回归系数的均值为 它们的协方差矩阵是
扰动方差的先验尺度为0.01。使用点表示法指定先验信息。
PriorMdl。米u = [-20; 4; 0.001; 2]; PriorMdl.V = diag([1 0.001 1e-8 0.01]); PriorMdl.B = 0.01;
请求一个新的图形并绘制先验分布。
情节(PriorMdl);
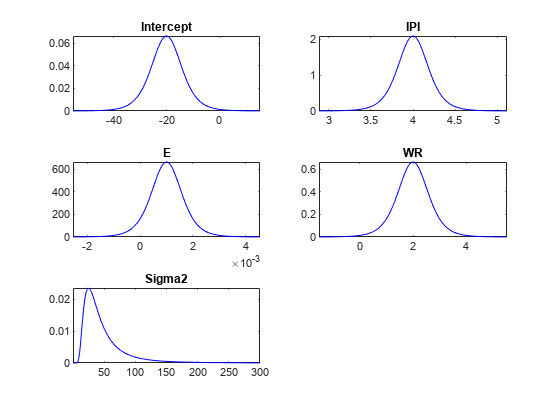
情节用扰动方差的先验分布图替换当前分布图。
加载Nelson-Plosser数据集,并为预测器和响应数据创建变量。
负载Data_NelsonPlosserX = DataTable{:, priormll . varnames (2:end)};y = dattable . gnpr;
估计后验分布。
PosteriorMdl =估计(PriorMdl,X,y,“显示”、假);
PosteriorMdl是一个conjugateblm的后验分布的模型对象
和
.
绘制后验分布。
情节(PosteriorMdl);
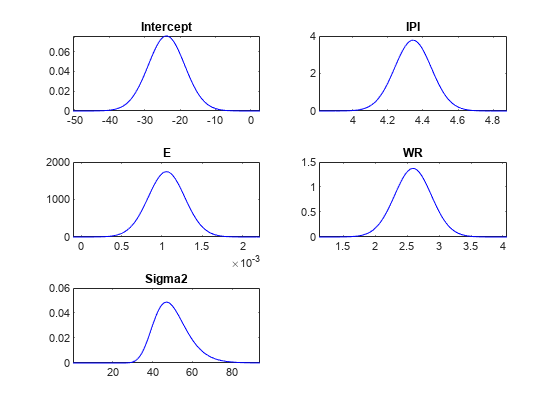
在同一子图上绘制参数的先验和后验分布。
情节(PosteriorMdl PriorMdl);
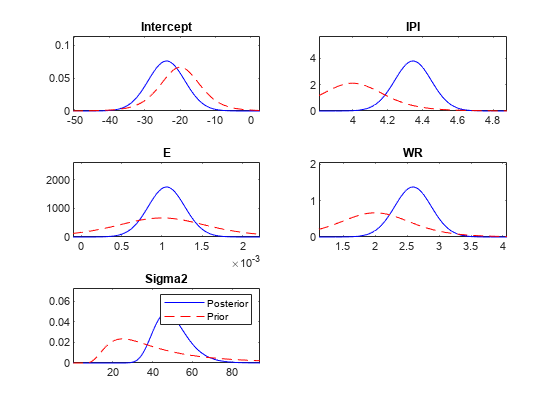
绘制分布以分离图形
中的回归模型绘制先验和后验分布.
加载Nelson-Plosser数据集,创建一个默认的共轭先验模型,然后使用前75%的数据估计后验。关闭估计显示。
P = 3;VarNames = [“他们”“E”“福”];PriorMdl = bayeslm(p,“ModelType”,“共轭”,“VarNames”, VarNames);负载Data_NelsonPlosserX = DataTable{:, priormll . varnames (2:end)};y = dattable . gnpr;D = 0.75;PosteriorMdlFirst =估计(PriorMdl,X(1:地板(d*端),:),y(1:地板(d*端)),…“显示”、假);
绘制扰动方差的先验分布和后验分布。返回数字句柄。
[~,~,~,h] = plot(PosteriorMdlFirst,PriorMdl,“VarNames”,“Sigma2”);
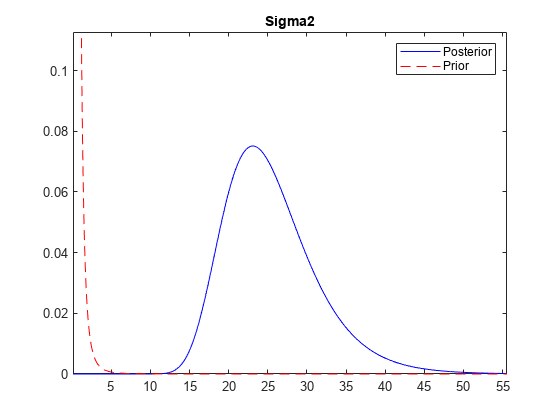
h是分布图的图形句柄。方法更改图形的标记名称标签财产,然后是下一个情节调用将所有新的分布图放在不同的图形上。
将图形句柄的名称更改为FirstHalfData使用点表示法。
h.Tag =“FirstHalfData”;
用剩下的数据估计后验分布。指定基于最后25%数据的后验分布作为先验分布。
PosteriorMdl =估计(PosteriorMdlFirst,X(ceil(d*end):end,:),…y(装天花板(d *结束):结束),“显示”、假);
根据一半数据和所有数据绘制扰动方差的后验图。
情节(PosteriorMdl PosteriorMdlFirst,“VarNames”,“Sigma2”);
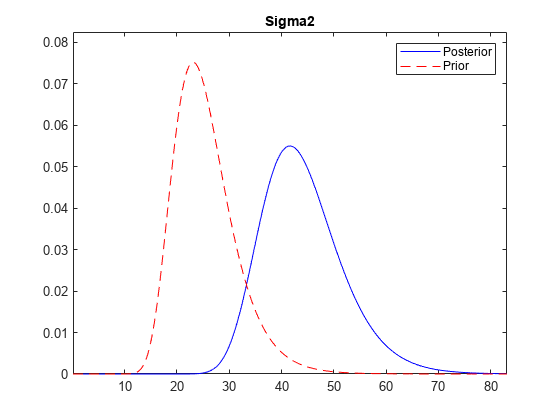
这种类型的图显示了合并新数据时后验分布的演变。
返回默认分布和计算
中的回归模型绘制先验和后验分布.
加载Nelson-Plosser数据集并创建一个默认的共轭先验模型。
P = 3;VarNames = [“他们”“E”“福”];PriorMdl = bayeslm(p,“ModelType”,“共轭”,“VarNames”, VarNames);负载Data_NelsonPlosserX = DataTable{:, priormll . varnames (2:end)};y = dattable . gnpr;
绘制先验分布。请求用于创建图的参数值及其各自的密度。
[pointsUsedPrior,priorDensities1] = plot(PriorMdl);
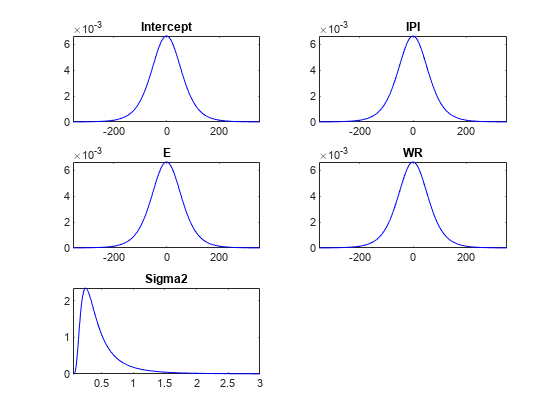
pointsUsedPrior是一个5 × 1单元阵列的1 × 1000数值向量表示的参数值情节用于绘制相应的密度。第一个元素对应截距,后面三个元素对应回归系数,最后一个元素对应扰动方差。priorDensities1和pointsUsed并包含相应的密度值。
估计后验分布。关闭估计显示。
PosteriorMdl =估计(PriorMdl,X,y,“显示”、假);
绘制后验分布。请求用于创建图的参数值及其各自的密度。
[pointsUsedPost,posteriorDensities1] = plot(PosteriorMdl);
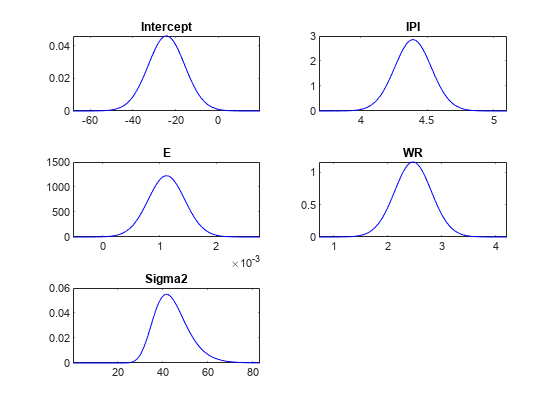
pointsUsedPost和posteriorDensities1有相同的尺寸pointsUsedPrior.的pointsUsedPost输出可以不同pointsUsedPrior.posteriorDensities1包含后验密度值。
绘制先验和后验分布。请求用于创建图的参数值及其各自的密度。
[pointsUsedPP,posteriorDensities2,priorDensities2] = plot(PosteriorMdl,PriorMdl);
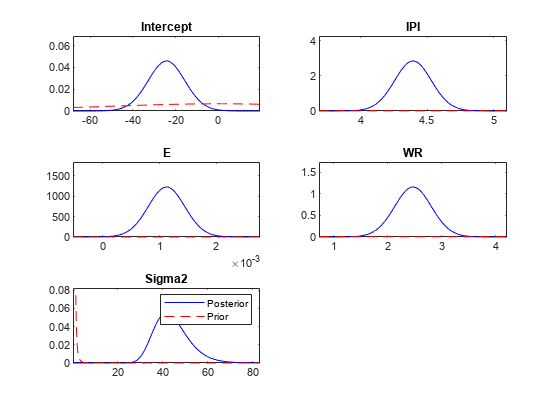
所有输出值都具有相同的维度pointsUsedPrior.的posteriorDensities2输出包含后验密度值。的priorDensities2输出包含先前的密度值。
确认pointsUsedPP等于pointsUsedPost.
比较= @(a,b)sum(a == b) == nummel (a);cellfun(比较、pointsUsedPost pointsUsedPP)
ans =5x1逻辑阵列1 1 1 1 1 1
所用的点数是相等的。
确认后验密度是相同的,但先验密度不是。
cellfun(比较、posteriorDensities1 posteriorDensities2)
ans =5x1逻辑阵列1 1 1 1 1 1
cellfun(比较、priorDensities1 priorDensities2)
ans =5x1逻辑阵列0 0 0 0 0
当只绘制先验分布时,情节评估点上的先验密度,产生一个清晰的先验分布图。在绘制先验分布和后验分布时,情节喜欢清楚地绘制后方。因此,绘图可以确定不同的集合点使用。
指定密度评估和绘图的值
中的回归模型绘制先验和后验分布.
加载Nelson-Plosser数据集,并为回归系数和扰动方差创建默认的共轭先验模型。然后,估计后验分布,得到估计汇总表总结.
P = 3;VarNames = [“他们”“E”“福”];PriorMdl = bayeslm(p,“ModelType”,“共轭”,“VarNames”, VarNames);负载Data_NelsonPlosserX = DataTable{:, priormll . varnames (2:end)};y = dattable . gnpr;PosteriorMdl =估计(PriorMdl,X,y);
方法:分析后验分布观察数:62预测数:4对数边际似然:-259.348 |意味着性病CI95积极的分布 ----------------------------------------------------------------------------------- 拦截| -24.2494 - 8.7821[-41.514,-6.985]0.003吨(-24.25、8.65 ^ 2,68)IPI | 4.3913 - 0.1414 [4.113, 4.669] 1.000 t E(4.39、0.14 ^ 2,68)| 0.0011 - 0.0003[0.000,0.002]1.000吨(0.00、0.00 ^ 2,68)代为| 2.4683 - 0.3490[1.782,3.154]1.000吨(2.47、0.34 ^ 2,68)Sigma2 | 44.1347 - 7.8020[31.427, 61.855] 1.000搞笑(34.00,0.00069)
summaryTbl = summary (PosteriorMdl);summaryTbl = summaryTbl. marginaldistribution;
summaryTbl表中是否包含统计信息估计在命令行中显示。
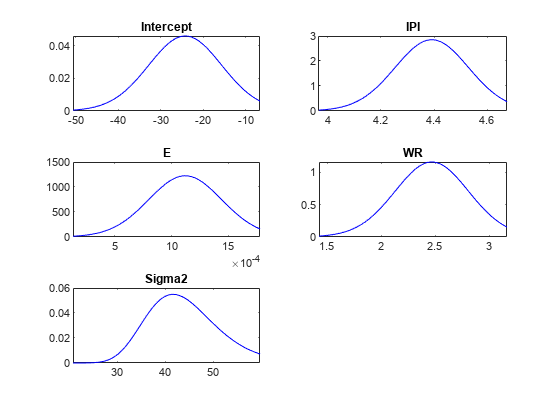
对于每个参数,确定一组50个均匀间隔的值,在平均值的三个标准偏差内。按照组成估计汇总表行的参数的顺序,将值放入5 × 1单元格向量的单元格中。
点数= cell(数值(summaryTbl.Mean),1);%预先配置为j = 1: nummel (summaryTbl.Mean) Points{j} = linspace(summaryTbl.Mean(j) - 3*summaryTbl.Std(j),…summaryTbl.Mean(j) + 2*summaryTbl.Std(j),50);结束
在各自的区间内绘制后验分布。
情节(PosteriorMdl“点”点)
输入参数
输出参数
限制
因为不适当的分布(密度不积分为1的分布)没有很好的定义,情节不能画得很好。
更多关于
另请参阅
对象
conjugateblm|semiconjugateblm|diffuseblm|empiricalblm|customblm|mixconjugateblm|mixsemiconjugateblm|lassoblm
功能
您也可以从以下列表中选择一个网站:
