单因素模型校准
这个例子演示了校准一个单因素模型的技术,该模型用于估计投资组合信贷损失creditDefaultCopula或信用额度类。
此示例使用股权返回数据作为信用波动的代理。使用权益数据,对单个因素的敏感性估计是库存和索引之间的相关性。数据集包含一系列股票的每日返回数据,但单因素模型每年需要校准。假设没有自相关,那么股票和市场指数之间的日常交叉相关性等于年度互相关。对于表现出自相关的股票,该示例显示了如何计算包含自相关效果的隐含年相关性。
拟合单因素模型
由于企业违约很少见,在校准违约模型时,通常会使用信用可靠性的代理。单因素联系模型使用一个潜在变量,一个:
在哪里X是系统性信用因素,w定义一个公司对一个因素的敏感性的权重是和吗
是特殊因素。w和
具有0的平均值和1的方差,并且通常被认为是高斯或其他T分布。
计算X和一个:
自X和一个差异1通过建设和
不相关X,那么:
如果你用股票回报作为代理一个而市场指数回报是X,则是权重参数,w,库存和索引之间的相关性。
准备数据
用道琼斯工业平均指数(DJIA)的回报作为市场整体信贷运动的信号。30家成分股公司的回报被用来校准每家公司对系统性信贷运动的敏感性。股票市场上其他公司的权重也是用同样的方法估算的。
%阅读道琼斯指数一年的价格数据t = readtable(“dowPortfolio.xlsx”);表格包含日期和每个公司在市场收盘时的价格%以及Djia。DISP(头(:,1:7))))
日期收AA AIG AXP英航C _________ _____ _____ _____ _____ _____ _____ 1/3/2006 10847 28.72 68.41 51.53 68.63 45.26 1/4/2006 10880 28.89 68.51 51.03 69.34 44.42 1/5/2006 10882 29.12 68.6 51.57 68.53 44.65 1/6/2006 10959 29.02 68.89 51.75 67.57 44.65 1/9/2006 11012 29.37 68.57 53.04 28.44 69.18 - 52.88 67.33 - 44.57 67.01 - 44.43 1/10/2006 110121/11/2006 11043 28.05 69.6 52.59 68.3 44.98 1/12/2006 10962 27.68 69.04 52.6 67.9 45.02
%我们将日期和索引从表中分离出来,并使用% tick2ret。日期= t){2:最终,1};index_adj_close = t {: 2};stocks_adj_close = t{: 3:结束};index_returns = tick2ret (index_adj_close);stocks_returns = tick2ret (stocks_adj_close);
计算单因素权重
从指数回报和每个公司的股票回报之间的相关系数计算单因素权重。
[C,daily_pval] = corr([index_returns stocks_returns]);w_daily = C(2:结束,1);
使用单因素时可以直接使用这些值creditDefaultCopula或信用额度.
线性回归通常用于因素模型。对于单因素模型,利用相关系数与决定系数的平方根相匹配的事实,使用股票市场收益的线性回归(R-平方)的线性回归。
w_daily_regress = zeros(30,1);为I = 1:30 lm = fitlm(index_returns,stocks_returns(:, I));w_daily_regress (i) =√lm.Rsquared.Ordinary);结束%回归的R值等于指数相互关系流('Max Abs Diff: %e\n',max(abs(w_daily_regress(:) - w_daily(:)))))
Max Abs Diff: 7.771561e-16
这种线性回归符合这种形式的模型 ,它通常不符合单因素模型规范。例如, 和 不要让平均值为零,标准差为1。一般来说,系数之间没有关系 和误差项的标准差 .线性回归仅用作为一种工具,以获得由平方根给出的变量之间的相关系数R平方值。
对于单因素模型校准,一个有用的替代方法是使用标准化的股票和市场回报数据拟合线性回归 和 .“标准化”在这里的意思是减去平均值,然后除以标准差。模型是 .然而,因为 和 均值为零,截距为零 总是零,因为两者都是 和 具有1的标准偏差,误差术的标准偏差满足 .这与单因素模型的系数的规格完全匹配。单因素参数 为系数 ,与前面直接通过相关性找到的值相同。
w_regress_std = 0(30日1);index_returns_std = zscore (index_returns);stocks_returns_std = zscore (stocks_returns);为I = 1:30 lm = fitlm(index_returns_std,stocks_returns_std(:, I));w_regress_std (i) = lm。系数{'x1','估计'};结束%回归的R值等于指数相互关系流('Max Abs Diff: %e\n',max(abs(w_regress_std(:) - w_daily(:)))))
MAX ABS差异:5.551115E-16
这种方法使探索变量的分布假设变得很自然。的creditDefaultCopula和信用额度对象支持正常分布金宝app或t底层变量的分布。例如,使用时normplot市场回报有重尾,因此是一个t-copula更符合数据。
normplot (index_returns_std)

估计更长时期的相关性
权重是根据股票和指数之间的每日相关性计算的。然而,通常的目标是估计未来某个时候(通常是一年之后)信贷违约的潜在损失。
为此,有必要对权重进行校准,使其与一年期相关性相对应。由于数据点的稀疏性,任何合理的数据集都没有足够的数据在统计上具有显著性,因此直接根据历史年收益数据进行校准是不实际的。
然后,你要面对的问题是,如何从更频繁的抽样数据集(例如,日收益率)计算年收益率相关性。解决这个问题的一种方法是使用重叠窗口。通过这种方式,您可以考虑给定长度的所有重叠周期的集合。
%以例为例,考虑重叠的1周窗口。index_overlapping_returns = index_adj_close(6:结束)./ index_adj_close(1:end-5) - 1;stocks_overlapping_returns = stocks_adj_close(6:结束,:) ./ stocks_adj_close(1:end-5,:) - 1;c = cor([index_overlapping_returns stocks_overlapping_returns]);w_weekly_overlapping = c(2:结束,1);%将相关性与每日相关性进行比较。%显示每日与重叠的每周相关性barh([w_daily w_weekly_重叠])yticks(1:30) yticklabels(t.Properties.VariableNames(3:end)) title('与索引的相关性');传奇('日常',“重叠周刊”);

最大互相关p-值的日回报显示出很强的统计意义。
maxdailypvalue = max (daily_pval(2:最终,1));disp(表(maxdailypvalue......'variablenames', {“每天”},......'rownames', {'最大p值'})))
每日__________ p-value最大值1.5383e-08
切换到重叠滚动窗口样式的每周相关性提供了稍微不同的相关性。这是一种从每日数据估计较长时期相关性的简便方法。然而,相邻重叠窗口的返回值是相关的,因此对应的p的重叠周返回值无效,因为p- value计算相关系数功能不考虑重叠窗口数据集。例如,相邻的重叠窗口返回由许多相同的DataPoint组成。此权衡是必要的,因为迁移到非传播的窗口可能导致一个不可接受的稀疏样本。
%与非重叠每周回报相比周五= weekday(dates) == 6;index_weekly_close = index_adj_close(星期五);: stocks_weekly_close = stocks_adj_close(星期五);index_weekly_returns = tick2ret (index_weekly_close);stocks_weekly_returns = tick2ret (stocks_weekly_close);[C,weekly_pval] = corr([index_weekly_returns stocks_weekly_returns]); / /每个星期返回一个星期w_weekly_nonoverlapping = C(2:结束,1);maxweeklypvalue = max (weekly_pval(2:最终,1));%对比日与重叠的相关性。barh([w_daily w_weekly_overing w_weekly_nonoverlapping])yticks(1:30)yticklabels(t.properties.variablenames(3:结束))标题('与索引的相关性');传奇('日常',“重叠周刊”,'非重叠每周');

的p-非重叠周相关性的值要高得多,表明统计意义的损失。
%计算每个系列的样本数量numdaily = numel(index_returns);numoverlapping = numel(index_overlapping_returns);numweekly = numel(index_weekly_returns);disp(表([maxdailypvalue; numdaily],[nan; numoverlapping],[maxweeklypvalue; numweekly],......'variablenames', {“每天”,“重叠”,“Non_Overlapping”},......'rownames', {'最大p值','样本大小'})))
每日重叠非_______________________________最大p值1.5383e-08 nan 0.66625样品大小250 246 50
根据年度相关
与财务数据的共同假设是资产返回在时间上不相关。也就是说,资产随时返回T是否与之前的收益不相关T1。在这种假设下,年互相关与日互相关完全相等。
让 是当天市场指数的日常日志回报t和 是相关资产的每日回报。使用CAPM,关系模拟为:
单因素模型是这种关系的一个特例。
假设资产收益和指数收益与各自的过去不相关,则:
y,
将每一系列的年度(日志)收益合计为
在哪里T可能是252.这取决于基本的每日数据。
让 和 为日方差,由日收益数据估计。
日协方差 和 是:
每天的相关性 和 是:
考虑一年的总收益的方差和协方差。在无自相关假设下:
资产与指数之间的年度相关性是:
在没有自相关的假设下,请注意,每日交叉相关实际上是平等的到年度互相关。您可以在单因素模型中直接使用这个假设,方法是将单因素权重设置为每日的相互关系。
自相关处理
如果放松资产没有自相关性的假设,那么资产之间从日相互关系到年相互关系的转换就不那么简单了。的 现在有了附加条款。
首先考虑计算变化的最简单的情况
什么时候T等于2.
自 ,那么:
考虑T=3..表示每日返回之间的相关性
天分开
.
在一般情况下,对于一个集合的方差T日收益率与跟踪自相关k天,有:
这也是同样的资产方差公式:
之间的协方差 和 如前面所示等于 .
因此,索引和资产之间的互相关与尾随的自相关1通过k天是:
注意 为无自相关假设下的权重。平方根项提供了用于解释序列中的自相关的调整。调整更多地取决于指数自相关和股票自相关之间的差异,而不是这些自相关的大小。因此,自相关调整后的年度单因素权重为:
用自相关计算权值
在每个股票中寻找自相关,前一天的返回,并调整权重,以包含为期一天自相关的效果。
corr1 = 0(30日1);pv = 0(30日1);为stockkidx = 1:30 [corr1(stockkidx),pv1(stockkidx)] = corr(stocks_returns(2:end, stockkidx),stocks_returns(1:end-1, stockkidx));结束auto斗牛= find(pv1 < 0.05)
autocorrIdx =4×110 18 26 27
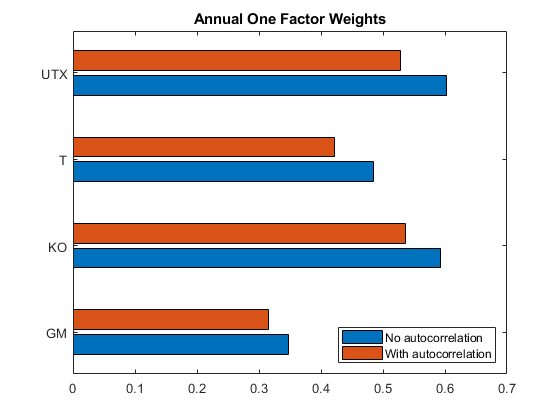
有四支股票处于低位p-可能指示存在自相关的值。在此模型下,考虑到一天的自相关,估计与指数的年度互相关。
%基于年互相关的权重等于日互相关%相关系数乘以另外一个因子。T = 252;w_yearly = w_daily;[rho_index, pval_index] = corr(index_returns(1:end-1),index_returns(2:end)); / /返回结果%检查我们的索引是否有任何显著的自相关性流('指数p-value中的一天自相关:%f\n', pval_index);
指数P值中的一天自相关:0.670196
如果pval_index < 0.05%如果p-值表明指数中没有显著的自相关,%将其rho设置为0。rho_index = 0;结束w_yearx (auto斗牛线)= w_yearx (auto斗牛线).*......√(T / 2 + (T - 1)。* rho_index)。/ (T / 2 + (T - 1)。* corr1 (autocorrIdx)));%将调整后的年交叉相关值与日常值进行比较barh([w_daily(autovorridx)w_yearly(autovorridx)])yticks(1:4);Allnames = T.Properties.variablenames(3:结束);yticklabels(All命名(AutovorRIDX))标题('年度一个因素权重');传奇(“不相关”,'用自相关',“位置”,“东南”);
另请参阅
confidenceBands|creditDefaultCopula|GetScenarios.|portfoliorisk.|riskContribution|模拟
相关的例子
更多关于
你也可以从以下列表中选择一个网站:
