使用深度学习的语义分割
这个例子说明了如何使用深学习培养了语义分割网络。
语义分割网络对图像中的每个像素进行分类,从而得到按类分割的图像。语义分割的应用包括用于自主驾驶的道路分割和用于医学诊断的癌细胞分割。想了解更多,请看入门语义分割使用Deep学习.
为了说明训练过程,本实施例列车Deeplab V3 + [1],一种类型的卷积神经网络的(CNN)设计用于语义的图像分割。其他类型的网络对语义分割的包括完全卷积网络(FCN),SegNet,和U-Net的。这里显示的训练过程可以被应用到这些网络了。
本例使用CamVid数据集[2]从剑桥大学进行培训。此数据集是包含在驾驶时获得的街道级视图的图像的集合。该数据集提供了像素级标签32个语义类别包括汽车,行人和道路。
设置
本示例创建Deeplab V3 +网络与来自预训练RESNET-18网络初始化权重。RESNET-18是非常适合于具有有限处理资源的应用程序的有效网络。其他预训练的网络,诸如MobileNet v2或RESNET-50也可以根据应用的需要使用。有关详细信息,请参阅预训练深层神经网络(深度学习工具箱)。
为了获得预训练RESNET-18,安装深度学习工具箱™模型RESNET-18网络.安装完成后,运行以下代码以验证安装是否正确。
resnet18 ();
另外,下载一个预训练版本的DeepLab v3+。预训练的模型允许您运行整个示例,而不必等待训练完成。
pretrainedURL ='//www.tatmou.com/金宝appsupportfiles/vision/data/deeplabv3plusResnet18CamVid.mat';pretrainedFolder = fullfile (tempdir,'pretrainedNetwork');pretrainedNetwork =完整文件(pretrainedFolder,'deeplabv3plusResnet18CamVid.mat');如果〜存在(pretrainedNetwork,'文件')MKDIR(pretrainedFolder);DISP(“预训练下载网(58 MB)......”);websave(pretrainedNetwork,pretrainedURL);结束
强烈建议使用具有计算能力3.0或更高的cuda能力的NVIDIA™GPU来运行此示例。使用GPU需要并行计算工具箱™。
下载CamVid数据集
从以下url下载CamVid数据集。
IMAGEURL =“http://web4.cs.ucl.ac.uk/staff/g.brostow/MotionSegRecData/files/701_StillsRaw_full.zip”;labelURL ='http://web4.cs.ucl.ac.uk/staff/g.brostow/MotionSegRecData/data/LabeledApproved_full.zip';outputFolder =完整文件(TEMPDIR,“CamVid”);labelsZip = fullfile (outputFolder,'labels.zip');imagesZip = fullfile (outputFolder,'images.zip');如果〜存在(labelsZip,'文件')| | ~存在(imagesZip'文件'mkdir (outputFolder) disp (“下载16层MB CamVid数据集的标签......”);websave(labelsZip,labelURL);解压缩(labelsZip,完整文件(outputFolder,'标签'));DISP(“下载557倍MB CamVid数据集的图像......”);websave(imagesZip,IMAGEURL);解压缩(imagesZip,完整文件(outputFolder,“图片”));结束
注:数据的下载时间取决于您的Internet连接。使用上述块MATLAB的命令,直至下载完成。另外,您也可以使用Web浏览器对数据集先下载到本地磁盘。要使用从网上下载的文件,更改outputFolder以上变量指定下载文件的位置。
加载CamVid图片
使用imageDatastore加载视频图像。的imageDatastore使您能够有效地在磁盘上加载大量映像。
imgDir = fullfile (outputFolder,“图片”,'701_StillsRaw_full');imd = imageDatastore (imgDir);
显示其中一个图像。
I = readimage (imd, 1);I = histeq(我);imshow(我)

加载CamVid像素标记的图像
使用pixelLabelDatastore来加载CamVid像素标签图像数据。一个pixelLabelDatastore封装了像素标签数据和标签ID的一类名称映射。
我们让培训变得更容易,我们把原来的32个班级分成了11个班级。指定这些类。
类= [“天空”“建造”“极”“路”“路面”“树”“SignSymbol”“篱笆”“汽车”“行人”“自行车”];
为了将32个类减少到11个,将原始数据集中的多个类分组在一起。例如,“Car”是“Car”、“SUVPickupTruck”、“Truck_Bus”、“Train”和“OtherMoving”的组合。使用支持函数返回分组的标签id金宝appcamvidPixelLabelIDs,它列在本例的末尾。
labelIDs = camvidPixelLabelIDs();
使用类和标签的ID创建pixelLabelDatastore。
labelDir = fullfile (outputFolder,'标签');pxds = pixelLabelDatastore (labelDir、类labelIDs);
读取并通过覆盖其上的图像的顶部的像素标记的图像的显示之一。
C = readimage (pxds, 1);提出= camvidColorMap;我= labeloverlay (C“ColorMap”,CMAP);imshow(B)pixelLabelColorbar(CMAP,班);

没有颜色覆盖的区域没有像素标签,也不会在训练中使用。
分析数据集统计数据
若要查看CamVid数据集,使用类标签的分发countEachLabel.这个函数根据类标签来计算像素的数量。
台= countEachLabel (pxds)
TBL =11×3表名称PixelCount ImagePixelCount ______________ __________ _______________ { '天空'} 7.6801e + 07 4.8315e + 08 { '大厦'} 1.1737e + 08 4.8315e + 08 { '极'} 4.7987e + 06 4.8315e + 08 { '道'}1.4054e + 08 4.8453e + 08 { '路面'} 3.3614e + 07 4.7209e + 08 { '树'} 5.4259e + 07 4.479e + 08 { 'SignSymbol'} 5.2242e + 06 4.6863e + 08 {'栅栏'} 6.9211e + 06 2.516e + 08 {' 汽车”} 2.4437e + 07 4.8315e + 08 { '行人'} 3.4029e + 06 4.4444e + 08 { '自行车运动员'} 2.5912e + 06 2.6196e + 08
通过可视化类的像素数。
频率= tbl.PixelCount /笔(tbl.PixelCount);(1:numel(类),频率)xticks(1:numel(类))xticklabel (tbl.Name) xtickangle(45) ylabel('频率')
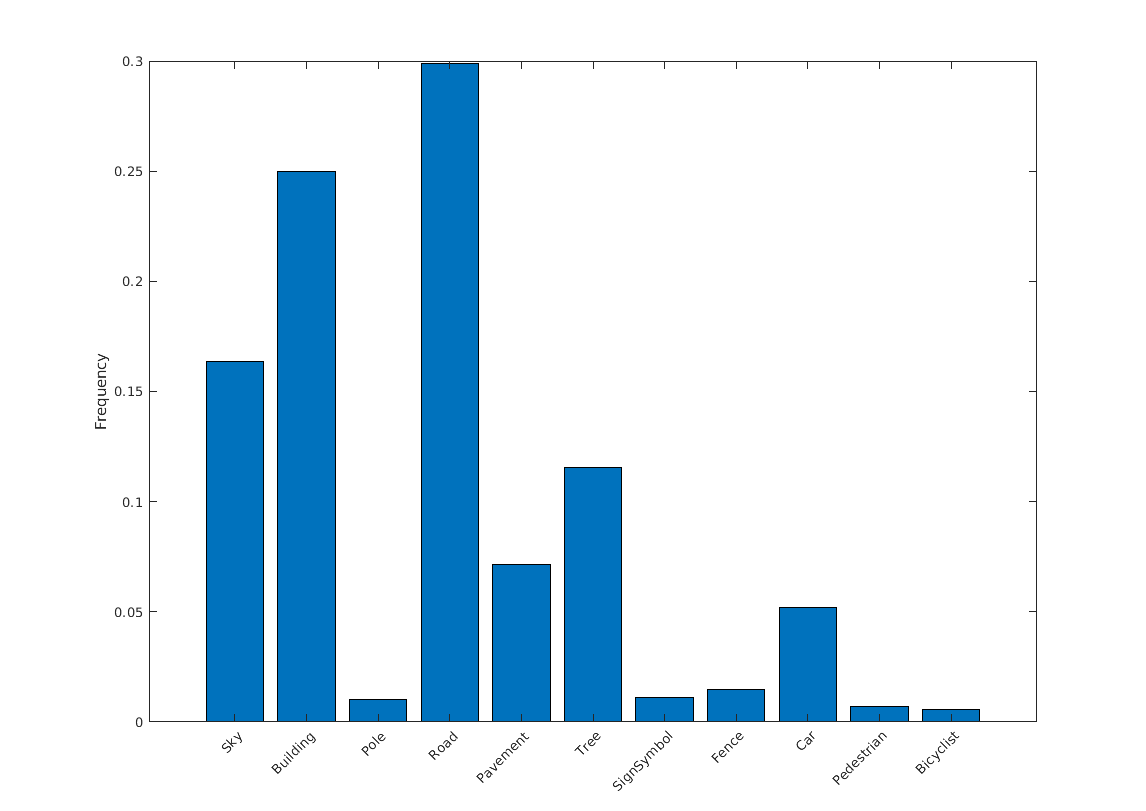
理想情况下,所有的类都应该有相同数量的观察值。然而,在CamVid的类是不平衡的,这是一个常见的问题,在汽车数据集的街道场景。这类场景的天空、建筑物和道路像素比行人和自行车像素更多,因为天空、建筑物和道路在图像中覆盖的面积更大。如果处理不当,这种不平衡会对学习过程产生不利影响,因为学习是偏向于优势阶级的。稍后,在这个示例中,您将使用类加权来处理这个问题。
CamVid数据集中的图像大小是720×960。图像大小的选择使得在NVIDIA™Titan X上进行训练时,可以在内存中容纳足够大的一批图像,而NVIDIA™Titan X的内存为12gb。如果你的GPU没有足够的内存或减少训练批大小,你可能需要调整图像到更小的尺寸。
准备培训、验证和测试集
Deeplab V3 +使用的是数据集中的图像的60%的培训。图像的其余部分在20%平均分配和用于验证和测试分别20%。下面的代码随机分割图像和像素标签数据到训练,验证和测试集。
[imdsTrain, imdsVal, imdsTest, pxdsTrain, pxdsVal, pxdsTest] = partitionCamVidData(imds,pxds);
60/20/20分割结果如下图所示:
numTrainingImages =元素个数(imdsTrain.Files)
numTrainingImages = 421
numValImages = numel(imdsVal.Files)
numValImages = 140
numTestingImages = numel(imdsTest.Files)
numTestingImages = 140
创建网络
使用deeplabv3plusLayers函数创建一个基于ResNet-18的DeepLab v3+网络。为您的应用程序选择最佳网络需要经验分析,这是超参数调优的另一个层次。例如,您可以尝试使用不同的基础网络,如ResNet-50或MobileNet v2,或者您可以尝试其他语义分割网络架构,如SegNet、全卷积网络(FCN)或U-Net。
%指定网络的图像尺寸。这通常是一样的国家队训练图像尺寸。imageSize = [720960 3];%指定的类的数量。numClasses = numel(类);%创建DeepLab v3+。lgraph = deeplabv3plusLayers(imageSize, numClasses,“resnet18”);
使用类加权来平衡类
如图所示早些时候,在CamVid类不均衡。为了提高训练,你可以使用类的权重,以平衡类。使用前面与计算的像素数的标签countEachLabel并计算出中位数频率类的权重。
imageFreq = tbl.PixelCount ./ tbl.ImagePixelCount;classWeights =中间值(imageFreq)./ imageFreq
classWeights =11×10.3182 0.2082 5.0924 0.1744 0.7103 0.4175 4.5371 1.8386 1.0000 6.6059⋮
指定使用的类权重pixelClassificationLayer.
pxLayer = pixelClassificationLayer('名称','标签',“类”,tbl.Name,“ClassWeights”,classWeights);lgraph = replaceLayer (lgraph,“分类”,pxLayer);
选择培训选项
用于培训的优化算法是动量(SGDM)随机梯度下降。使用trainingOptions指定用于SGDM的超参数。
定义验证数据。pximdsVal = pixelLabelImageDatastore (imdsVal pxdsVal);%定义培训选项。选项= trainingOptions(“个”,…“LearnRateSchedule”,“分段”,…'LearnRateDropPeriod'10…“LearnRateDropFactor”,0.3,…“动量”,0.9,…“InitialLearnRate”,1E-3,…“L2Regularization”,0.005,…'ValidationData',pximdsVal,…'MaxEpochs'30,…“MiniBatchSize”8,…“洗牌”,“每个历元”,…'CheckpointPath'tempdir,…“VerboseFrequency”2,…“情节”,“训练进步”,…“ValidationPatience”,4);
学习率采用的是分段的时间表。学习速率是由0.3每10个历元的因子减小。这使得网络具有较高的初始学习率快速学习,同时能够找到一个解决方案接近局部最优一次学习率下降。
网络不受验证数据每历元通过设置测试'ValidationData'参数。的“ValidationPatience”设置为4,停止训练初期验证准确性收敛时。这可以防止网络过度拟合的训练数据集。
小批处理大小为8,用于减少训练时的内存使用。你可以增加或减少根据您的系统上的GPU内存量此值。
此外,'CheckpointPath'被设置为一个临时位置。此名称 - 值对使网络检查站的保存在每个训练时代的结束。如果培训是系统故障或停电中断的原因,您可以继续从已保存的检查点的训练。确保位置的指定'CheckpointPath'有足够的空间来存储网络检查站。例如,储存100个Deeplab V3 +检查点要求6〜GB的磁盘空间,因为每个检查点是61 MB。
数据扩张
数据增强正在训练,以提供网络更多的例子,因为它有助于提高网络的精确度时使用。在这里,为+/- 10像素随机左/右的反射和随机X / Y平移用于数据增强。使用imageDataAugmenter指定这些数据增强参数。
增量= imageDataAugmenter (“RandXReflection”,真正,…“RandXTranslation”-10年[10],“RandYTranslation”,-10年[10]);
imageDataAugmenter金宝app支持其他几种类型的数据扩充。在它们之间进行选择需要进行实证分析,这是超参数调整的另一个层次。
开始训练
结合使用的训练数据和数据扩充选择pixelLabelImageDatastore.的pixelLabelImageDatastore读取批量训练数据,应用数据扩充,并将扩充后的数据发送给训练算法。
pximds = pixelLabelImageDatastore (imdsTrain pxdsTrain,…'DataAugmentation'、增压器);
开始培训使用trainNetwork如果doTraining国旗是正确的。否则,加载一个预先训练好的网络。
注:培训,验证上的英伟达™泰坦X具有12 GB GPU内存中。如果您的GPU具有较少的内存,你可以的记忆训练中跑出来。如果发生这种情况,可以尝试设置“MiniBatchSize”1在trainingOptions或降低了网络的输入和调整用的训练数据“OutputSize”参数pixelLabelImageDatastore.培训这个网络大约需要5个小时。根据您的GPU硬件,可能需要更长的时间。
doTraining = FALSE;如果doTraining [净,信息] = trainNetwork(pximds,lgraph,选项);其他的data =负载(pretrainedNetwork);网= data.net;结束
在一个映像上测试网络
作为一个快速的完整性检查,在一个测试映像上运行这个训练好的网络。
I = readimage (imdsTest 35);C = semanticseg(I, net);
显示结果。
我= labeloverlay (C“Colormap”,CMAP,“透明”,0.4);imshow (B) pixelLabelColorbar(提出、类);

比较结果C与预期的地面真相储存在pxdsTest.绿色和洋红色区域突出了分割结果与期望地面真相不同的区域。
expectedResult = readimage (pxdsTest 35);实际= uint8 (C);预期= uint8 (expectedResult);预计imshowpair(实际)

在视觉上,语义分割结果在道路、天空和建筑物等类中重叠良好。然而,像行人和汽车这样的小物体就不那么精确了。每个类的重叠量可以使用相交-过并集(IoU)度量,也称为Jaccard索引。使用jaccard功能,以衡量欠条。
借据= jaccard (C, expectedResult);表(类、借据)
ans =11×2表学校下设“天”字0.91837“楼”字0.84479“路”字0.31203“路”字0.83698“路”字0.82838“树”字0.89636“标志”字0.57644“栅栏”字0.71046“车”字0.66688“行人”字0.48417“自行车”字0.68431
IoU度量确认了可视化结果。道路、天空和建筑类的IoU得分较高,而行人和汽车类的IoU得分较低。其他常见的细分指标包括骰子和bfscore轮廓匹配分数。
评估培训网络
为了测量多个测试图像,运行精度semanticseg在整个测试集。将4小批量尺寸用于减少存储器的使用,同时分割图像。你可以增加或减少根据您的系统上的GPU内存量此值。
pxdsResults = semanticseg (imdsTest净,…“MiniBatchSize”4…'WriteLocation'tempdir,…“详细”,假);
semanticseg将测试集的结果返回为pixelLabelDatastore宾语。在每一个测试图像的实际像素标签数据imdsTest写入磁盘中由指定的位置'WriteLocation'参数。使用evaluateSemanticSegmentation对测试集结果进行语义分割度量。
度量= evaluateSemanticSegmentation(pxdsResults,pxdsTest,“详细”,假);
evaluateSemanticSegmentation返回整个数据集、单个类和每个测试图像的各种指标。要查看数据集级别指标,请查看metrics.DataSetMetrics.
metrics.DataSetMetrics
ans =表1×5_______ GlobalAccuracy MeanAccuracy MeanIoU WeightedIoU MeanBFScore * * *…………0.87695 0.85392 - 0.6302 0.80851 - 0.65051
数据集指标提供了网络性能的高级概览。要查看每个类对总体性能的影响,请使用以下工具查看每个类的指标metrics.ClassMetrics.
metrics.ClassMetrics
ans =11×3表精度借条MeanBFScore ________ _______ ___________天空0.93112 0.90209 0.8952大厦0.78453 0.76098 0.58511极0.71586 0.21477 0.51439路0.93024 0.91465 0.76696路面0.88466 0.70571 0.70919树0.87377 0.76323 0.70875 SignSymbol 0.79358 0.39309 0.48302栅栏0.81507 0.46484 0.48564汽车0.90956 0.76799 0.69233步行0.87629 0.4366 0.60792自行车运动员0.87844 0.60829 0.55089
尽管整个数据集的性能相当高,但是类指标显示,代表性不足的类,比如行人,骑自行车和车不分段以及类,如路,天空和建造.它包括的代表性不足的班级可能会帮助更多的样品附加数据改善的结果。
金宝app支持功能
功能labelIDs = camvidPixelLabelIDs ()%返回对应于每一类的标签的ID。%CamVid数据集有32个类。把他们分成11个班%原SegNet训练方法[1]。%% 11类是:%的“天空”“建筑”,“极”,“路”,“路面”、“树”、“SignSymbol”,%“篱笆”,“汽车”,“行人”和“自行车运动员”。%% CamVid像素标签id作为RGB颜色值提供。集团成% 11类,并将其作为m×3矩阵的单元数组返回。的每个RGB值旁边都列出了%原始的CamVid类名。请注意%,其他/Void类被排除在下面。labelIDs = {…%的“天空”[128 128 128;…%的“天空”]% “建造”[000 128064;…%“桥”128 000 000;…% “建造”064 192 000;…%的“墙”064 000 064;…%的“隧道”192 000 128;…%“牌楼”]%“极点”[192 192 128;…%”Column_Pole”000 000 064;…% “交通拥挤”]%的道路[128064 128;…%的“路”128 000 192;…% “LaneMkgsDriv”192 000 064;…%”LaneMkgsNonDriv”]%“路面”[000 000 192;…%“人行道”064 192 128;…% “ParkingBlock”128 128 192;…% “RoadShoulder”]%的“树”[128128 000;…%的“树”192 192 000;…%”VegetationMisc”]%”SignSymbol”[192 128 128;…%”SignSymbol”128 128 064;…% “Misc_Text”000 064 064;…%”TrafficLight”]%“篱笆”[064 064 128;…%“篱笆”]%的“汽车”[064 000 128;…%的“汽车”064 128 192;…% “SUVPickupTruck”192 128 192;…%”Truck_Bus”192 064 128;…%“训练”128 064 064;…%”OtherMoving”]%“行人”[064 064 000;…%“行人”192 128 064;…%“孩子”064 000 192;…% “CartLuggagePram”064 128 064;…%的“动物”]%“自行车运动员”[000 128192;…%“自行车运动员”192 000 192;…% “MotorcycleScooter”]};结束
功能一会pixelLabelColorbar(提出)向当前轴添加一个颜色栏。颜色栏被格式化了%以显示类名的颜色。颜色表(GCA,CMAP)%添加颜色栏到当前的数字。c = colorbar (“对等”,GCA);%用途类名的刻度线。c。TickLabels =一会;numClasses =大小(提出,1);%中心标记标签。c。蜱虫= 1 / (numClasses * 2): 1 / numClasses: 1;清除标记。c。TickLength = 0;结束
功能提出= camvidColorMap ()%定义由CamVid数据集使用的颜色表。cmap = [128,128,128]%天空128 0 0% 建造192 192 192%极128 64 128%的道路60 40 222路面%128 128 0%的树192 128 128%SignSymbol64 64 128%的栅栏64 0 128%的车64 64 0%行人0 128 192自行车运动员%];%在[0 1]之间正常化。cmap = cmap ./ 255;结束
功能[imdsTrain, imdsVal, imdsTest, pxdsTrain, pxdsVal, pxdsTest] = partitionCamVidData(imds,pxds)通过随机选择60%的数据进行训练,%分割CamVid数据。的% rest用于测试。设定初始随机状态,例如再现性。rng (0);numFiles =元素个数(imds.Files);shuffledIndices = randperm (numFiles);%用途用于训练图像的60%。numTrain = round(0.60 * numFiles);trainingIdx = shuffledIndices (1: numTrain);%要用于验证图像的20%numVal = round(0.20 * numFiles);valIdx = shuffledIndices (numTrain + 1: numTrain + numVal);%剩余的用于测试。testIdx = shuffledIndices(numTrain + numVal + 1:结束);%创建训练和测试图像数据存储。trainingImages = imds.Files(trainingIdx);valImages = imds.Files(valIdx);testImages = imds.Files(testIdx);imdsTrain = imageDatastore(trainingImages);imdsVal = imageDatastore(valImages);imdsTest = imageDatastore(testImages);提取类和标签id信息。类= pxds.ClassNames;labelIDs = camvidPixelLabelIDs();%创建的培训和测试像素标签数据存储。trainingLabels = pxds.Files (trainingIdx);valLabels = pxds.Files (valIdx);testLabels = pxds.Files (testIdx);pxdsTrain = pixelLabelDatastore(训练标签、类、标签);pxdsVal = pixelLabelDatastore(valLabels, classes, labelid);pxdsTest = pixelLabelDatastore(testlabel, classes, labelid);结束
参考文献
[1]陈,梁杰等。“编码器 - 解码器与Atrous可分离卷积语义图像分割”。ECCV(2018)。
[2] Brostow, G. J., J. Fauqueur,和R. Cipolla。“视频中的语义对象类:高清地面真实数据库。”模式识别的字母.第30卷,2009年第2期,第88-97页。
也可以看看
countEachLabel|evaluateSemanticSegmentation|imageDataAugmenter|labeloverlay|pixelClassificationLayer|pixelLabelDatastore|pixelLabelImageDatastore|segnetLayers|semanticseg|trainNetwork|trainingOptions
相关话题
- 入门语义分割使用Deep学习
- 标签像素的语义分割
- MATLAB中的深度学习(深度学习工具箱)
- 预训练深层神经网络(深度学习工具箱)
您还可以选择从下面的列表中的网站:
