统计和机器学习工具
통계및머신러닝으로데이터를를분석하고모델링할수수수수

统计和机器学习工具箱™는데이터를를,분석분석,모델링하는함수와을제공합니다。탐색적이터분석데위해기술,시각시각,군집군집를사용하고,데이터터에분포를를하며,몬테카를로시뮬레이션을을위해난수생성생성,가설설검정을수행할수수수생성생성생성생성생성생성회귀와분류알고리즘을통해이터로부터추론을도출하고,분류학습기및회귀앱을이용해해대화형방식,또는自动을을을해프로그래밍방식예측모델을구축할있습니다있습니다수있습니다있습니다있습니다있습니다있습니다있습니다있습니다있습니다있습니다있습니다있습니다있습니다있습니다있습니다있습니다있습니다있습니다있습니다있습니다있습니다있습니다있습니다있습니다있습니다있습니다있습니다있습니다있습니다있습니다있습니다있습니다있습니다있습니다있습니다있습니다있습니다있습니다있습니다있습니다있습니다있습니다있습니다있습니다있습니다있습니다있습니다있습니다있습니다있습니다있습니다있습니다있습니다있습니다있습니다있습니다있습니다있습니다있습니다있습니다있습니다수수수수수수
다차원데이터분석분석과과특징특징위해위해,이툴박스는사용자용자변수를할할을pca(주성분분석),정규화,차원축소,특징선택을제공합니다。
툴박스는 SVM(서포트 벡터 머신), 부스팅 결정 트리, k-평균 및 기타 군집화 방법 등을 포함한 지도, 준지도, 비지도 머신러닝 알고리즘을 제공합니다. 부분 종속성 플롯, LIME 등의 해석력 기법을 적용하고, 임베디드 기기로의 배포를 위해 자동으로 C/C++ 코드를 생성할 수도 있습니다. 툴박스의 많은 알고리즘은 메모리에 담기에 너무 큰 데이터 세트에 대해서 사용할 수 있습니다.
시작하기:

무료电子书
머신러닝마스터: MATLAB 단계별 가이드
시각화
확률 플롯, 상자 플롯, 히스토그램, 분위수-분위수 플롯 및 덴드로그램, 행렬도, 앤드류스 플롯 등 다변량 분석을 위한 고급 플롯을 이용하여 데이터를 시각적으로 탐색할 수 있습니다.

다차원산점도플롯을이용한한변수간간관계관계
기술 통계량
관련성이 높은 몇몇의 수치를 이용하여 잠재적인 대규모 데이터 세트를 빠르게 이해하고 설명할 수 있습니다.

그룹화한평균분산을이용한데이터탐색。
군집 분석
K-평균,k-중앙개체,dbscan,계층계층및스펙트럼군집,가우스우스모델,은닉은닉모델을이용해이터를를그룹그룹화패턴을발견할수

두동심그룹에dbscan적용。
특징 추출
희소 필터링 및 복원 ICA 등 비지도 학습 기법을 이용하여 데이터로부터 특징을 추출할 수 있습니다. 특수 기법을 이용하여 이미지, 신호, 텍스트, 숫자형 데이터에서 특징을 추출할 수도 있습니다.

모바일 기기에서 제공한 신호에서 특징 추출.
특징선택
데이터를를모델링할때의예측검정력을제공하는특징을자동으로으로수수수수수수특징선택방법에는단계적,순차순차특징선택,정규화,앙상블앙상블등이있습니다。
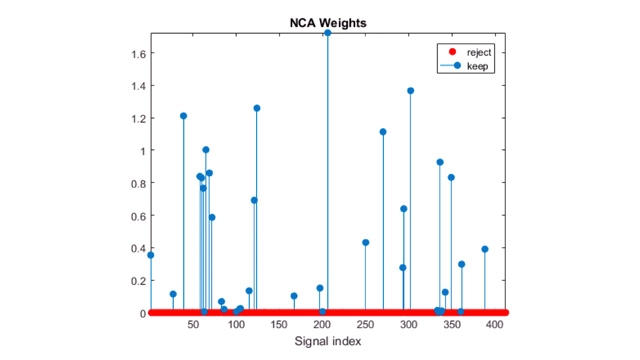
NCA는 모델의 정확도를 가장 잘 보존하는 특징을 선택하게 해줍니다.
특징 변환 및 차원 축소
차원을축소하여의(비범주형)특징들을새로운예측변수변환하면덜적인특징들버릴수수수수수있습니다。특징변환방법에는pca,요인요인,비음수행렬등이있습니다。

PCA는는대부분의의정보보존한채로고차원고차원벡터를직교좌표계에사합니다
예측 모델의 학습, 검증 및 조정
다양다양한머신러닝알고리즘알고리즘을비교,특징을선택하며,하이퍼파라미터파라미터를조정,널리사용되는되는다양한분류및알고리즘의성능성능을평평평평수수수수수수수수수수수수수수수수수수대화형앱으로예측모델을구축하고자동으로최적화하며,스트리밍데이터를이용하여모델을점진적으로개선할수있습니다。
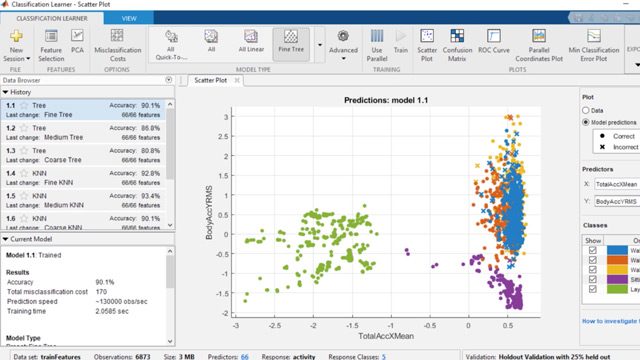
모델해석력
부분 종속성 플롯, ICE(Individual Condition Expectations), LIME(Local Interpretable Model-agnostic Explanations) 등 기성 해석 가능성 모델을 적용하여 블랙박스 머신러닝 모델의 해석력을 개선할 수 있습니다.

LIME은 복잡한 모델의 간단한 근사 모델을 국지적으로 구축합니다.
자동머신러닝(自动机)
자동으로하이퍼파라미터파라미터를조정하고특징과모델선택하며비용행렬로행렬로터세트불균형을해결해결으로써의성능을을개선할수수
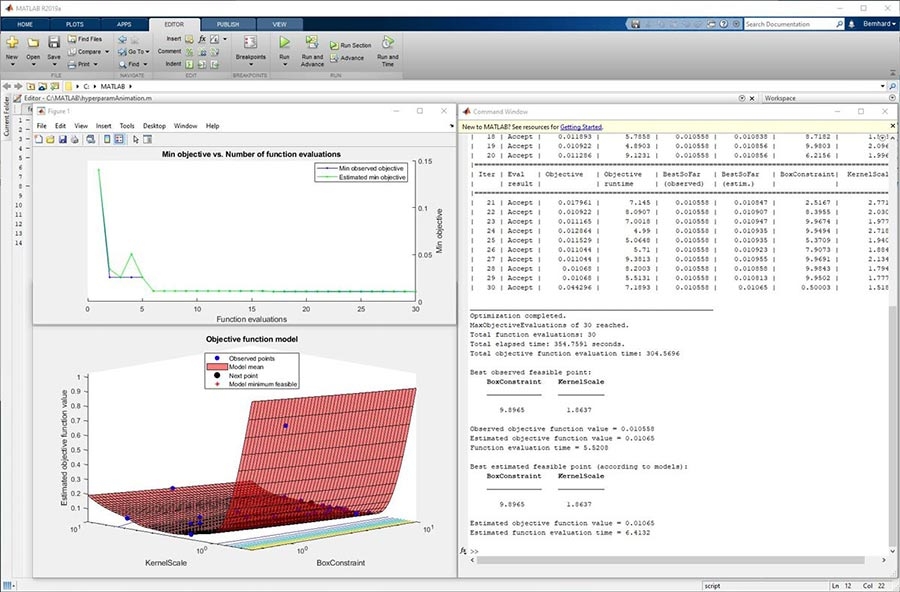
이즈베화를이용한한효율적인인하최적최적최적파라미터최적최적
선형 및 비선형 회귀
많은 선형 및 비선형 회귀 알고리즘에서 선택한 복수의 예측 변수 또는 응답 변수를 사용하여 복잡한 시스템의 동작을 모델링할 수 있습니다. 다중 수준 또는 계층적, 선형, 비선형, 일반화 선형 혼합효과 모델과 중첩 및/또는 교차 임의효과를 피팅시켜, 종단 분석 또는 패널 분석, 반복 측정, 성장 모델링을 수행할 수 있습니다.

회귀 학습기 앱을 사용한 대화형 방식의 회귀 모델 피팅.
비모수적 회귀
svm,랜덤포레스트,가우스과정,가우스커널을이용,예측예측변수와응답변수의관계기술하는모델을지정지정하지정확한을을생성할수수한한을생성생성수수있습니다정확한을을생성할수수있습니다한피팅을생성할수수수한있습니다피팅을생성생성할수수있습니다있습니다피팅을생성생성수수수수수있습니다을생성수수수수수
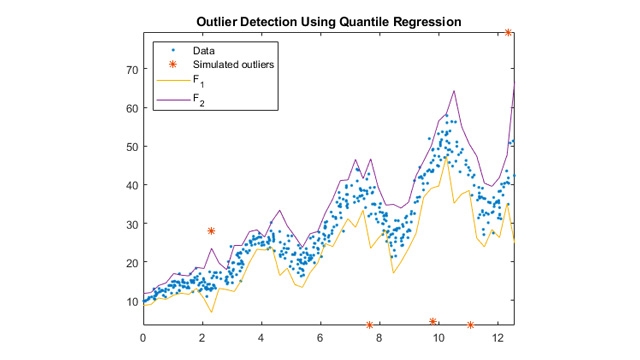
분위수 회귀를 이용한 이상값 식별.
ANOVA (분산분석)
표본 분산을 다양한 요인에 할당해 보고 변이가 다양한 인구 집단 내부에서 발생하는지 아니면 집단 간에 발생하는지 파악할 수 있습니다. 일원, 이원, 다원, 다변량, 비모수적 ANOVA와 공분산 분석(ANOCOVA), 반복 측정 분산분석(RANOVA)을 사용할 수 있습니다.

다원 ANOVA를 사용한 그룹 검정.
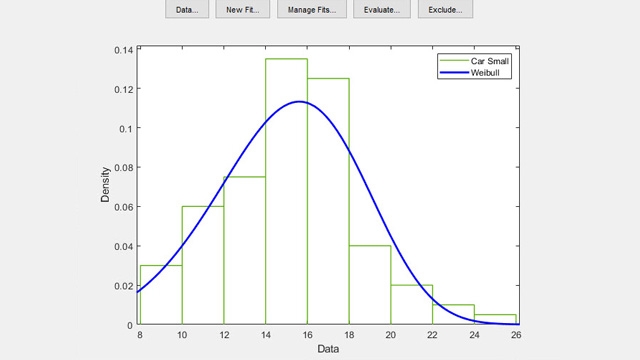
분포 피팅기 앱을 사용한 대화형 방식의 분포 피팅하기.
난수생성
피팅된확률분포또는된된분포로부터의사난수및및준난수스트림을생성할수

대화형 방식의 난수 생성.
가설 검정
하나의표본,표본쌍또는독립표본에대해t-검정,분포검정(카이제곱,jarque-bera,lilliefors,콜모고로프 - 스미르노프)및및적검정을수행할있습니다있습니다。자동교정및임의성을검정하고분포(2-표본콜모고로프 - 스미르노프)를비교할수있습니다。

단측 t-검정의 기각 영역.
DOE (실험계획법)
사용자지정doe를를,분석,시각화할수。데이터입력입력값을조작하고동시에데터터값에미치는영향에대한를생성할지에관한관한계획만들고만들고테스트할수수

Box-Behnken 설계를 적용한 고차원 반응 표면 생성.
SPC (통계적 공정 관리)
공정 변동을 평가하여 제품이나 공정을 모니터링하고 개선할 수 있습니다. 관리도를 만들고 공정 능력을 추정하며, Gage 반복성 및 재현성 연구를 수행할 수 있습니다.
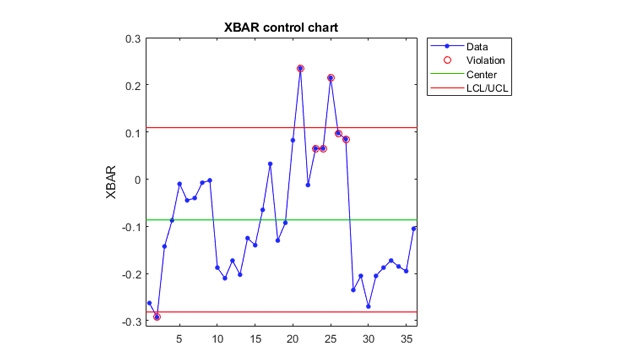
관리도를이용한제조공정모니터링。
신뢰도및생존분석
콕스(Cox) 비례 위험 회귀를 수행하여 중도절단이 있는 경우와 없는 경우의 평균 고장 시간을 시각화하고 분석한 후 분포를 피팅할 수 있습니다. 경험적 위험 함수, 생존 함수, 누적 분포 함수, 커널 밀도 추정값을 계산할 수 있습니다.

'중도절단' 값의 예로서의 고장 데이터.
Tall형 배열을 사용한 빅데이터 분석
다양한 분류, 회귀, 군집화 알고리즘에 tall형 배열과 테이블을 사용하여, 코드를 변경하지 않고 메모리에 담을 수 없는 데이터 세트에 대해 모델을 훈련시킬 수 있습니다.

병렬연산
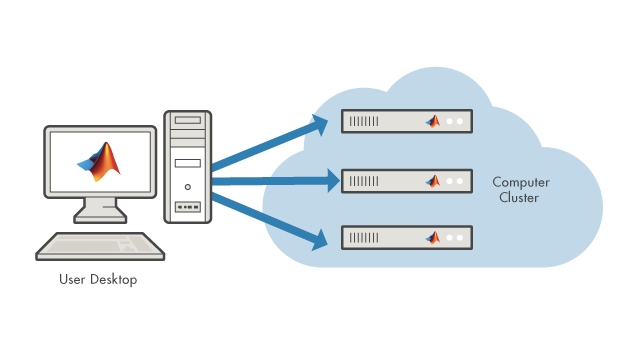
并行计算工具箱또는MATLAB并行服务器를이용한한연산속도。
클라우드 및 분산 연산
클라우드인스턴스를사용하여통계및머신러닝속도속도향상시킬수있습니다。Matlab Online™에서전체머신러닝워크플로를수행할있습니다。

Amazon 또는 Azure 클라우드 인스턴스에서의 연산 수행.
코드생성
분류 및 회귀 알고리즘, 기술 통계량, 확률 분포를 추론할 수 있는 이식성과 가독성이 좋은 C 또는 C++ 코드를 MATLAB Coder™를 사용하여 생성할 수 있습니다. Fixed Point Designer™를 이용하여 감소된 정밀도의 C/C++ 예측 코드를 생성하고, 예측 코드를 재생성하지 않고도 배포된 모델의 파라미터를 업데이트할 수 있습니다.

두 가지 배포 경로: C 코드 생성 또는 MATLAB 코드 컴파일.
金宝appSimulink와와의
머신러닝모델을 Simulink 모델에 통합하여 임베디드 하드웨어에 배포하거나 시스템 시뮬레이션, 검증, 확인에 활용할 수 있습니다.
응용 프로그램 및 엔터프라이즈 시스템과 통합
Matlab Compiler™를사용하여하여통계및머신러닝모델을단독모델모델모델모델모델모델모델모델또는또는또는또는응용프로그램,웹앱앱微软®Excel®추가 기능으로 배포할 수 있습니다. MATLAB Compiler SDK™를 사용하여 C/C++ 공유 라이브러리, Microsoft .NET 어셈블리, Java®클래스, Python®패키지를구축할수있습니다。
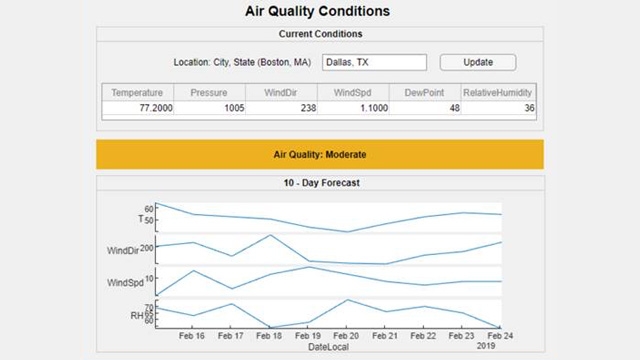
MATLAB Compiler를 사용한 대기 품질 분류 모델 통합.
AutoML
회귀회귀에최적인인모델및관련관련퍼파라미터자동(Fitrauto)
해석력
石灰(本地可解释模型 - 不可知不转解释)획득
SVM预测블록
金宝appSimulink에서svm모델모델이션및및코드
점진적학습
선형 회귀 및 이진 분류 모델의 점진적 훈련
준지도 학습
그래프와 자체 훈련된 모델(fitsemigraph, fitsemiself)을 사용하여 전체 데이터 세트에 부분 클래스 레이블을 외삽
코드생성
예측을 위한 단정밀도 C/C++ 코드 생성
성능
SVM모델의훈련속도향상
위위기능과관련함수함수에대한내용내용릴리스정보를 참조하십시오.

机器学习ondramp.

{kind=link}