 克利夫角:克利夫·莫尔谈数学和计算机
克利夫角:克利夫·莫尔谈数学和计算机 罗兰关于MATLAB的艺术
罗兰关于MATLAB的艺术 用MATLAB进行图像处理
用MATLAB进行图像处理 人在仿真软件金宝app
人在仿真软件金宝app 深度学习
深度学习 开发区域
开发区域 斯图尔特的MATLAB视频
斯图尔特的MATLAB视频 在标题后面
在标题后面 本周文件交换精选
本周文件交换精选 汉斯在物联网
汉斯在物联网 学生休息室
学生休息室 初创企业、加速器和企业家
初创企业、加速器和企业家 MATLAB社区
MATLAB社区 MATLABユーザーコミュニティー
MATLABユーザーコミュニティー深啤酒设计师
这篇文章来自于Ieuan Evans,他创造了一个非常独特的例子,将深度学习与LSTM和啤酒相结合。(请负责任地饮酒!)
我喜欢精酿啤酒。如今,有太多的选择,这可能是一个巨大的问题!最近,当我在酒吧里仔细挑选啤酒时,我发现自己变得懒惰起来,我倾向于选择名字听起来最好的啤酒。
我开始思考:MATLAB能自动分析名单并为我选择一种啤酒吗?为什么不呢?我能让MATLAB为我设计一种独特的啤酒吗?
在这个示例中,我将展示如何根据名称对啤酒类型进行分类,如何生成新的啤酒名称,甚至还将自动生成一些品尝记录。

查看数据的随机样本。
加载来自剑桥啤酒节的数据,除了名字和风格,还包含品尝记录。使用HTML解析工具从文本分析工具箱提取数据。
啤酒风格分类
首先,利用Kaggle数据,创建一个长短期记忆(LSTM)深度学习模型,对给定名称的啤酒类型进行分类。使用单词云可视化啤酒样式的分布。
 正如您在wordcloud中看到的,这些样式非常不平衡,有些样式只包含几个实例。为了改进模型,删除实例少于5个的样式,然后将数据分成90%的训练分区和10%的测试分区。(数据准备的详细信息可以在完整的示例文件中找到)
将每个啤酒名称转换为一个整数序列,其中每个整数代表一个字符。
答案是啤酒的风格。
正如您在wordcloud中看到的,这些样式非常不平衡,有些样式只包含几个实例。为了改进模型,删除实例少于5个的样式,然后将数据分成90%的训练分区和10%的测试分区。(数据准备的详细信息可以在完整的示例文件中找到)
将每个啤酒名称转换为一个整数序列,其中每个整数代表一个字符。
答案是啤酒的风格。
接下来创建深度学习网络架构。使用单词嵌入层来学习字符的嵌入,并将整数映射到向量。使用双向LSTM (BiLSTM)层来学习啤酒名称中字符之间的双向长期依赖关系。
为了学习BiLSTM层的隐藏单元之间更强的相互作用,包括一个额外的50大小的完全连接层。使用退出层来帮助防止网络过拟合。
 在这里,我们可以看到模型过度拟合。该模型对训练数据的记忆效果较好,但对测试数据的记忆精度不够高。
这也许是意料之中的:很多啤酒的名字并没有透露太多的风格,所以网络几乎没有工作。有些很容易分类,因为它们的名称中包含了啤酒的风格。
例如,你认为下面的啤酒是什么风格的?你能打败分类器吗?
在这里,我们可以看到模型过度拟合。该模型对训练数据的记忆效果较好,但对测试数据的记忆精度不够高。
这也许是意料之中的:很多啤酒的名字并没有透露太多的风格,所以网络几乎没有工作。有些很容易分类,因为它们的名称中包含了啤酒的风格。
例如,你认为下面的啤酒是什么风格的?你能打败分类器吗?
比较你的猜测和网络做出的预测和正确的标签
那么,我可以用这个网络为我选择啤酒吗?假设测试集包含一家酒吧的所有啤酒。我倾向于选择某种印度淡啤酒。让我们看看哪些啤酒属于国际淡啤酒。这可以是任何包含“IPA”的类标签。
看起来有些不错的建议!
 给啤酒起新名字
我们建立了一个深入的网络,可以帮我找瓶啤酒。我的下一个愿望是用MATLAB为我设计一款啤酒。首先它需要一个名字。为此,我将使用LSTM网络进行序列预测,它预测序列的下一个字符。为了改进模型,我还将包括来自英国剑桥啤酒节的啤酒名称。验证数据在这里没有帮助,所以我们将在所有数据上进行训练。
给啤酒起新名字
我们建立了一个深入的网络,可以帮我找瓶啤酒。我的下一个愿望是用MATLAB为我设计一款啤酒。首先它需要一个名字。为此,我将使用LSTM网络进行序列预测,它预测序列的下一个字符。为了改进模型,我还将包括来自英国剑桥啤酒节的啤酒名称。验证数据在这里没有帮助,所以我们将在所有数据上进行训练。
构建网络架构。
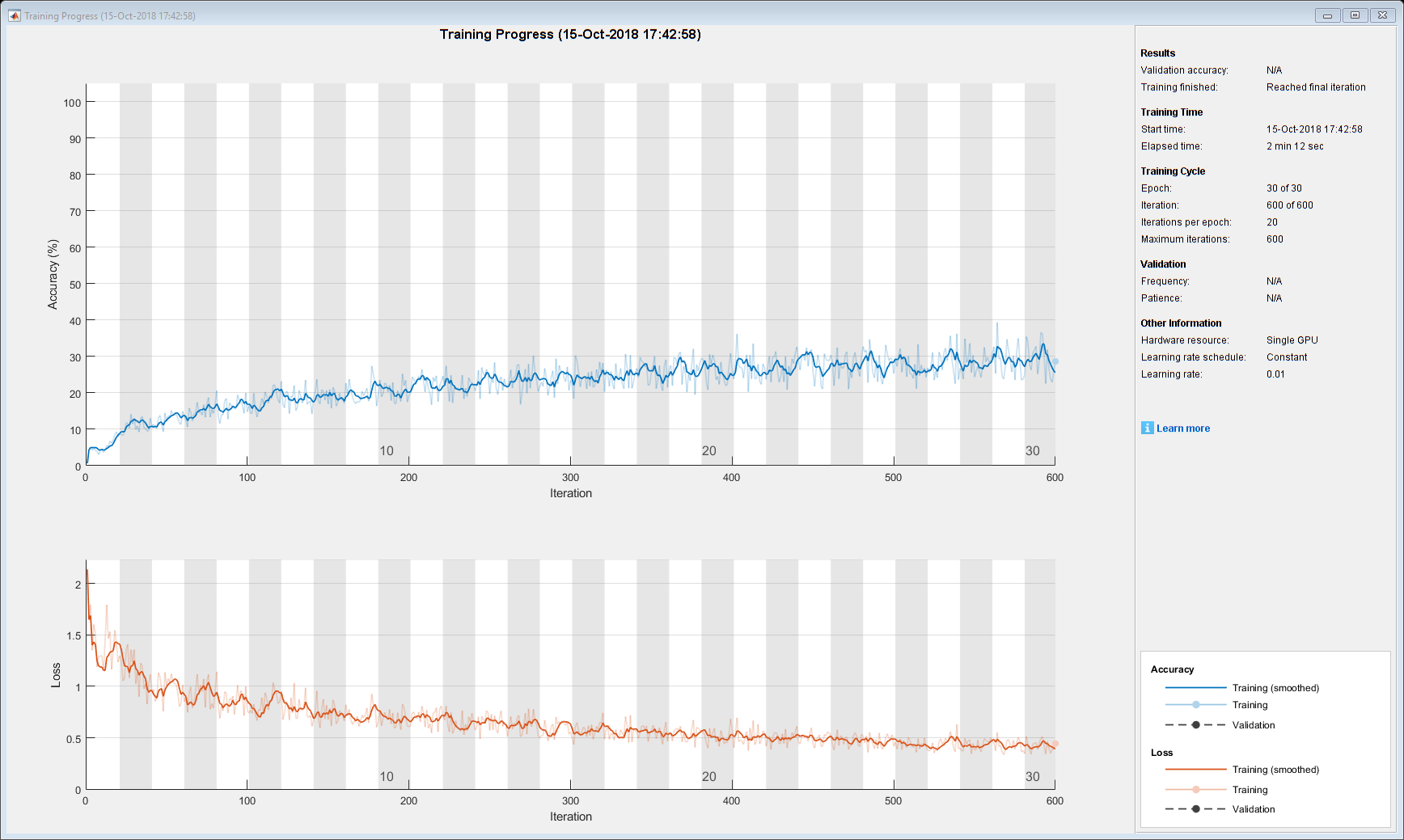 在这里,网络可能看起来并不是特别好。这也是意料之中的。为了获得较高的精度,网络必须准确地生成训练数据。我们不希望网络过度拟合,因为网络只会生成训练数据。
生成一些啤酒名称使用
generateText
函数,该函数包含在本文末尾的完整示例文件中。
在这里,网络可能看起来并不是特别好。这也是意料之中的。为了获得较高的精度,网络必须准确地生成训练数据。我们不希望网络过度拟合,因为网络只会生成训练数据。
生成一些啤酒名称使用
generateText
函数,该函数包含在本文末尾的完整示例文件中。
生成口味
我们有了啤酒名称,现在需要一些品酒笔记。与名字生成器类似,从剑桥啤酒节笔记创建一个品尝笔记生成器。
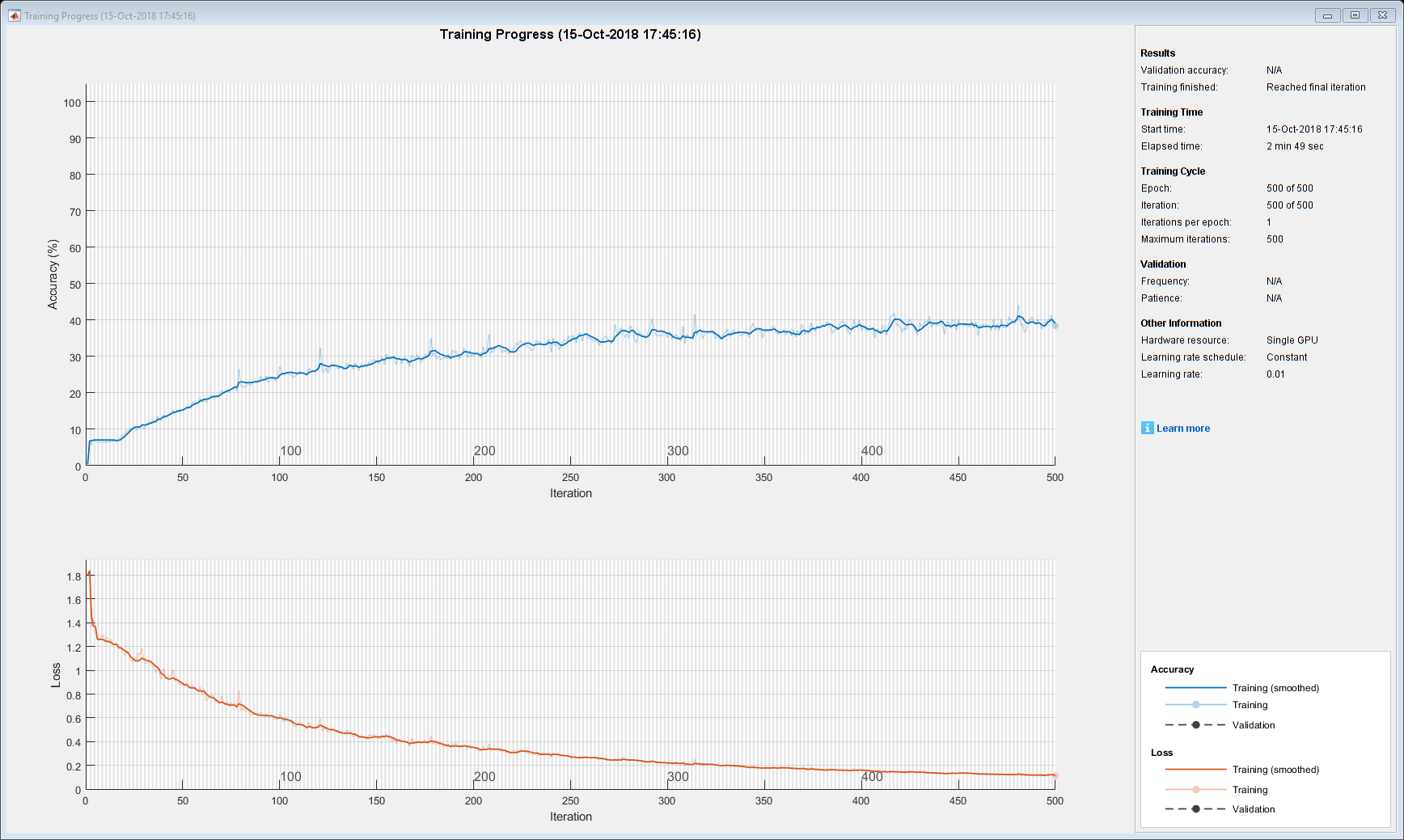 使用示例最后列出的generateText函数生成一些品尝笔记。
使用示例最后列出的generateText函数生成一些品尝笔记。
完美!我现在可以开始酿造我自己的完美啤酒了。您可以多次运行该代码以生成更多的名称和品尝说明。到目前为止我见过的我最喜欢的设计是:
Hopky狼音标
“这款双IPA啤酒以大麦芽为主,有葡萄柚、橙子和柠檬的味道,带有浓郁的花香和帐篷般的复杂味道。平衡的香气反映了它的口感。它是用Fuggle和Golding啤酒花混合跳跃的。”
现在我只需要MATLAB来自动化酿造过程…
哈佩希尔Hefeweizen

一种浓郁的传统玛氏比利时酵母。浓郁的酒体,带有坚果的味道和轻微的甜果味。”
(matlab生成名字和品尝笔记。不坏!)
导入数据
对于这个示例,有两个可用的数据源:- Kaggle精酿啤酒数据集:https://www.kaggle.com/nickhould/craft-cans
- 英国剑桥啤酒节上的啤酒清单:https://www.cambridgebeerfestival.com/下载188bet金宝搏products/cbf45-beer
Rng (0) filename = "beer .csv";dataKaggle = readtable(文件名,“TextType”,“弦”,“编码”,“utf - 8”);
idx = randperm(大小(dataKaggle, 1), 10);disp (dataKaggle (idx[“名称”“风格”)))
| 的名字 | 风格 |
| _______________________________________ | _______________________________________ |
| “隆(2014)” | “季节/农家啤酒” |
| “耀西的花蜜” | “加州普通/蒸汽啤酒” |
| “1327荚的ESB” | “特别特别/强烈苦味(ESB)” |
| “游行广场咖啡搬运工” | “美国波特” |
| “永恒的黑暗” | “比利时浓黑啤酒” |
| “La Frontera Premium IPA” | “美国音标” |
| “峡谷奶油啤酒” | “奶油啤酒” |
| “比利时风格的智慧” | “Witbier” |
| “Squatters Hop Rising Double IPA” | “美国双国际音标/皇家国际音标” |
| “良好氛围音标” | “美国音标” |
url = " https://www.cambridgebeerfestival.com下载188bet金宝搏/products/cbf44-beer ";代码= webread (url);树= htmlTree(代码);提取啤酒名称。
子树= findElement(树,“跨类= " " productname”“]”);name = extractHTMLText(子树);提取品尝笔记。
子树= findElement(树,“跨类=“品尝”“]”);笔记= extractHTMLText(子树);dataCambridge =表(姓名、笔记);把品酒笔记想象成一个词云。的 wordcloud 函数直接从字符串数据创建词云。
图wordcloud(笔记);标题(“口味”)

textData = dataKaggle.name;标签=分类(dataKaggle.style);图wordcloud(标签);标题(“啤酒风格”)
 正如您在wordcloud中看到的,这些样式非常不平衡,有些样式只包含几个实例。为了改进模型,删除实例少于5个的样式,然后将数据分成90%的训练分区和10%的测试分区。(数据准备的详细信息可以在完整的示例文件中找到)
将每个啤酒名称转换为一个整数序列,其中每个整数代表一个字符。
答案是啤酒的风格。
正如您在wordcloud中看到的,这些样式非常不平衡,有些样式只包含几个实例。为了改进模型,删除实例少于5个的样式,然后将数据分成90%的训练分区和10%的测试分区。(数据准备的详细信息可以在完整的示例文件中找到)
将每个啤酒名称转换为一个整数序列,其中每个整数代表一个字符。
答案是啤酒的风格。
YTrain = labelsTrain;欧美= labelsTest;YTrain (1:6)
| Ans = 6x1字符串数组 |
| 美国的淡啤酒 |
| 美国音标 |
| 美国双国际音标/英国皇家国际音标 |
| 美国音标 |
| 燕麦片的 |
numFeatures = 1;embeddingDimension = 100;(XTrain numCharacters = max ({}):);numClasses =元素个数(类别(YTrain));layers = [sequenceInputLayer(numFeatures) wordEmbeddingLayer(embeddingDimension,numCharacters) bilstmLayer(200,'OutputMode','last') dropoutLayer(0.5) fullconnectedlayer (50) dropoutLayer(0.5) fulllyconnectedlayer (numClasses) softmaxLayer classificationLayer];
指定培训选项。
options = trainingOptions('adam',…“MaxEpochs”,100年,…“InitialLearnRate”,0.01,…“GradientThreshold”,2,…“洗牌”、“every-epoch’,……ValidationData, {XTest,欧美},…“ValidationFrequency”,80年,…“阴谋”、“训练进步”,…“详细”,假);
培训网络。
beerStyleNet = trainNetwork (XTrain、YTrain层,选择);
 在这里,我们可以看到模型过度拟合。该模型对训练数据的记忆效果较好,但对测试数据的记忆精度不够高。
这也许是意料之中的:很多啤酒的名字并没有透露太多的风格,所以网络几乎没有工作。有些很容易分类,因为它们的名称中包含了啤酒的风格。
例如,你认为下面的啤酒是什么风格的?你能打败分类器吗?
在这里,我们可以看到模型过度拟合。该模型对训练数据的记忆效果较好,但对测试数据的记忆精度不够高。
这也许是意料之中的:很多啤酒的名字并没有透露太多的风格,所以网络几乎没有工作。有些很容易分类,因为它们的名称中包含了啤酒的风格。
例如,你认为下面的啤酒是什么风格的?你能打败分类器吗?
Idx = [1 4 5 8 9 10 12 14 15 17];textDataTest (idx)
| Ans = 10x1字符串数组 |
| “一知半解的季节” |
| “分裂的天空” |
| “亲爱的Kolsch” |
| “阿拉斯加琥珀” |
| “加州啤酒” |
| ”兄弟姐妹“蒸汽 |
| “愤怒的果园苹果姜” |
| “长叶” |
| “这个赛季的金发女郎” |
| “拉” |
YPred =分类(beerStyleNet XTest);disp(表(textDataTest (idx) YPred (idx),欧美(idx),“VariableNames”,(“名字”“预测”“True”)))
| 的名字 | 预测 | 真正的 |
| ______________________________ | ______________________________ | ______________________________ |
| “一知半解的季节” | 调味酒/农家麦芽酒 | 调味酒/农家麦芽酒 |
| “分裂的天空” | 美国琥珀/红麦芽酒 | 美国音标 |
| “亲爱的Kolsch” | Kolsch | Kolsch |
| “阿拉斯加琥珀” | 美国琥珀/红麦芽酒 | 酿造 |
| “加州啤酒” | 美国琥珀/红色拉格啤酒 | 美国琥珀/红色拉格啤酒 |
| ”兄弟姐妹“蒸汽 | 美国淡麦啤酒 | 加州普通啤酒/蒸汽啤酒 |
| “愤怒的果园苹果姜” | 苹果酒 | 苹果酒 |
| “长叶” | 慕尼黑地狱啤酒 | 美国音标 |
| “这个赛季的金发女郎” | 奶油啤酒 | 美国金发啤酒 |
| “拉” | 水果/蔬菜啤酒 | 美国双国际音标/英国皇家国际音标 |
一会=字符串(beerStyleNet.Layers(结束). class);idx =包含(类名,“音标”);(idx classNamesIPA =类名)
| Ans = 5x1字符串数组 |
| “美国音标” |
| “美国音标” |
| “美国白人音标” |
| “比利时音标” |
| 英国印度淡啤酒 |
[YPred,分数]= (beerStyleNet XTest)进行分类;idx =包含(字符串(YPred),“音标”);选择= textDataTest (idx);
让我们看看有多少比例被标记为国际音标。
accuracyIPA =意味着(包含字符串(欧美(idx)),“音标”))accuracyIPA = 0.7241 查看按分类分数排序的前10个预测。更令人兴奋的是,让我们排除所有名字中带有“国际音标”的名字
topScores = max(分数(idx:), [], 2);[~, idxSorted] =排序(topScores,“下”);selectionSorted =选择(idxSorted);%删除与IPA在名称中idx = contains(selectionSorted,["印度淡啤酒"]);selectionSorted (idx) = [];selectionSorted (1:10)
| Ans = 10x1字符串数组 |
| 《美国白痴麦芽酒》(2012) |
| “Citra面临“ |
| “在公海上跳跃(卡利普索)” |
| “孟加拉虎” |
| 剑铁天鹅啤酒 |
| “26” |
| “伊西斯” |
| “En Parfaite Harmonie” |
| “分别为圣” |
| “红鲑Maibock” |
 给啤酒起新名字
我们建立了一个深入的网络,可以帮我找瓶啤酒。我的下一个愿望是用MATLAB为我设计一款啤酒。首先它需要一个名字。为此,我将使用LSTM网络进行序列预测,它预测序列的下一个字符。为了改进模型,我还将包括来自英国剑桥啤酒节的啤酒名称。验证数据在这里没有帮助,所以我们将在所有数据上进行训练。
给啤酒起新名字
我们建立了一个深入的网络,可以帮我找瓶啤酒。我的下一个愿望是用MATLAB为我设计一款啤酒。首先它需要一个名字。为此,我将使用LSTM网络进行序列预测,它预测序列的下一个字符。为了改进模型,我还将包括来自英国剑桥啤酒节的啤酒名称。验证数据在这里没有帮助,所以我们将在所有数据上进行训练。
textData = [dataKaggle.name;dataCambridge.name];为了帮助生成,将所有空格字符替换为“·”(中间的点)字符,在开头插入文本的开始字符,在结尾插入文本的结束字符。
startOfTextCharacter =组成(" \ x0002 ");whitespaceCharacter =组成(" \ x00B7 ");endOfTextCharacter =组成(" \ x2403 ");
对于预测器,在啤酒名称之前插入文本字符的开头。对于响应,在啤酒名称后附加文本结束字符。这里,反应和预测者一样,只是移动了一个时间步长。
textDataPredictors = startOfTextCharacter + replace(textData," ", whitespaccharacter);textDataResponses = replace(textData," ", whitespaccharacter) + endOfTextCharacter;
XTrain = cellfun (@double、textDataPredictors UniformOutput,假);YTrain = cellfun(@(Y) categorical(cellstr(Y')'),textDataResponses,'UniformOutput',false);查看预测器和响应的第一个序列。
XTrain {1}
| ans = 1 x9 |
| 2 80 117 98 183 66 101 101 114 |
YTrain {1}
| Ans = 1x9绝对 |
| P u b·b e e r␃ |
numFeatures = 1;numClasses =元素个数(类别([YTrain {:})));(XTrain numCharacters = max ({}):);layers = [sequenceInputLayer(numFeatures) wordEmbeddingLayer(200,numCharacters) lstmLayer(400) dropoutLayer(0.5) fulllyconnectedlayer (numClasses) softmaxLayer classificationLayer];
指定培训选项。
options = trainingOptions('adam',…“InitialLearnRate”,0.01,…“GradientThreshold”,2,…“洗牌”、“every-epoch’,……“阴谋”、“训练进步”,…“详细”,假);
培训网络。
beerNameNet = trainNetwork (XTrain、YTrain层,选择);
 在这里,网络可能看起来并不是特别好。这也是意料之中的。为了获得较高的精度,网络必须准确地生成训练数据。我们不希望网络过度拟合,因为网络只会生成训练数据。
生成一些啤酒名称使用
generateText
函数,该函数包含在本文末尾的完整示例文件中。
在这里,网络可能看起来并不是特别好。这也是意料之中的。为了获得较高的精度,网络必须准确地生成训练数据。我们不希望网络过度拟合,因为网络只会生成训练数据。
生成一些啤酒名称使用
generateText
函数,该函数包含在本文末尾的完整示例文件中。
号向全国发表= 30;generatedBeers =字符串(号向全国发表,1);for i = 1:numBeers generatedBeers(i) = generateText(beerNameNet,startOfTextCharacter, whitespaccharacter,endOfTextCharacter);结束有时,网络可能会简单地根据训练数据预测啤酒名称。移除它们。
idx = ismember (generatedBeers textData);generatedBeers (idx) = [];查看生成的啤酒。
generatedBeers
| generatedBeers = |
| “Firis琥珀” |
| “Sprecian Claisper” |
| “值得淡色麦酒” |
| "Ma's Canido Winter Ale" |
| “跳激动” |
| “亲爱的Fuddel比尔森啤酒” |
| “Slowneck啤酒” |
| “cuda Colora啤酒” |
| “没有黑麦比尔森啤酒” |
| “黑暗光异丙醇” |
textData = dataCambridge.notes;与前面一样,为了帮助生成名称,将所有空格字符替换为“·”(中间的点)字符,在开头插入文本开头字符,在结尾插入文本结尾字符。 同样,定义网络体系结构,指定培训选项,并培训网络。 (详情见本文末尾的主要示例文件链接)
 使用示例最后列出的generateText函数生成一些品尝笔记。
使用示例最后列出的generateText函数生成一些品尝笔记。
号向全国发表= 5;for i = 1:numBeers generatedNotes = generateText(beerNotesNet,startOfTextCharacter, whitespaccharacter,endOfTextCharacter)结束
| “这款淡色麦酒有着非常强烈的淡色和醇厚的酒体以及拉格朗的回味。” |
| “这是一款酒体醇厚的皇家黑啤,带有轻微但富有弹性的口感,融合了烘焙、麦芽的味道,并在丝质黑啤的余味中呈现出微妙的特点。”Unfined。” |
| "浅铜,传统苦味,麦芽味。用最好的英国马里斯水獭口味酿造,果香浓郁,余味甜中带苦。” |
| “用多种口味酿造的烈性黑啤酒。Unfined。” |
| "混合麦芽和水果,让它沸腾" |
The MathWorks, Inc.版权所有
获取MATLAB代码
|
- 类别:
- 深度学习的例子








评论
要留下评论,请点击在这里登录到您的MathWorks帐户或创建一个新帐户。