主要内容
Kfoldpredict
对交叉验证的分类模型进行分类观察
句法
描述
标签= kfoldpredict(cvmdl.,'incorment interaction',internate interaction.)
例子
使用交叉验证预测创建混淆矩阵
使用判别分析模型的10倍交叉验证预测来创建混淆矩阵。
加载渔民数据集。X包含150种不同花的花测量,y列出每种花的物种或类。创建一个变量命令这指定类的顺序。
加载渔民x = meas;y =物种;订单=独特(Y)
订购=3x1细胞{'setosa'} {'versicolor'} {'virginica'}
通过使用通过使用10倍交叉验证的判别分析模型fitcdiscr.功能。默认情况下,fitcdiscr.确保培训和测试集具有大致相同的花卉物种比例。指定花卉类的顺序。
cvmdl = fitcdiscr(x,y,'kfold'10,'classnames',命令);
预测测试套装的种类。
predatespecies = kfoldpredict(cvmdl);
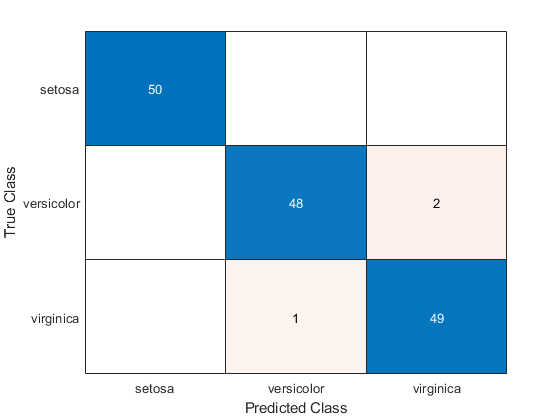
创建一个混淆矩阵,将真实类值与预测类值进行比较。
ConfusionChart(y,predatespecies)
从集合估算交叉验证预测
找到基于Fisher虹膜数据的模型的交叉验证预测。
装载Fisher的Iris数据集。
加载渔民
使用Adaboostm2培训分类树的集合。将树桩指定为弱学习者。
RNG(1);重复性的%t = templatetree('maxnumsplits',1);mdl = fitcensemble(meas,speies,'方法'那'adaboostm2'那'学习者',t);
使用10倍交叉验证交叉验证培训的合奏。
cvmdl = crossval(mdl);
估算交叉验证预测标签和分数。
[Elabel,Escore] = KfoldPredict(CVMDL);
显示每个类的最大和最小分数。
马克斯(埃斯勒)
ans =.1×39.3862 8.9871 10.1866
MIN(埃斯科)
ans =.1×30.0018 3.8359 0.9573
输入参数
输出参数
算法
Kfoldpredict计算相应中所述的预测预测对象功能。对于特定于模型的描述,请参阅相应的预测函数参考页面在下表中。
扩展能力
在R2011A介绍
您还可以从以下列表中选择一个网站:
