PEM.
精炼线性和非线性模型的预测误差最小化
描述
例子
精炼估计的状态空间模型
使用子空间方法估算离散时间 - 空间模型。然后,通过最小化预测误差来改进它。
估计使用的离散状态空间模型n4sid.,应用子空间方法。
加载Iddata7.Z7;Z7A = Z7(1:300);opt = n4sidoptions('重点'那'模拟');init_sys = n4sid(z7a,4,选择);
init_sys.提供73.85%拟合估计数据。
init_sys.report.fit.fitpercent.
ANS = 73.8490.
用PEM.提高契合的近距离。
sys = pem(z7a,init_sys);
分析结果。
比较(z7a,sys,init_sys);
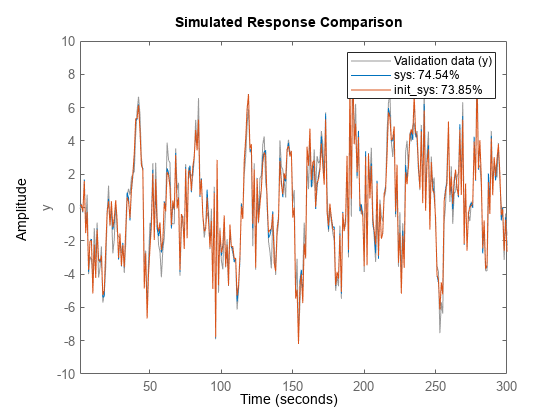
SYS.提供74.54%适合估计数据。
估计非线性灰度盒模型
估算非线性灰度盒模型的参数,以适合直流电机数据。
加载实验数据,并指定信号属性,例如开始时间和单位。
加载(全氟(MatlaBroot,'工具箱'那'ident'那'Iddemos'那'数据'那'dcmotordata'));DATA = IDDATA(Y,U,0.1);data.tstart = 0;data.timeUnit =.';
配置非线性灰度盒型号(idnlgrey.) 模型。
对于此示例,使用dcmotor_m.m.文件。要查看此文件,请键入编辑dcmotor_m.m.在MATLAB®命令提示符下。
file_name =.'dcmotor_m';订单= [2 1 2];参数= [1; 0.28];initial_states = [0; 0];ts = 0;init_sys = idnlgrey(file_name,订单,参数,initial_states,ts);init_sys.timeUnit =.';setInit(init_sys,'固定的',{false false});
init_sys.是一个非线性灰度盒模型,其结构描述于dcmotor_m.m.。该模型具有一个输入,两个输出和两个状态,如指定命令。
setInit(init_sys,'修复',{false false})指定初始状态init_sys.是免费估计参数。
估计模型参数和初始状态。
sys = pem(数据,init_sys);
SYS.是一个idnlgrey.模型,封装估计参数及其协方差。
分析估计结果。
比较(数据,sys,init_sys);
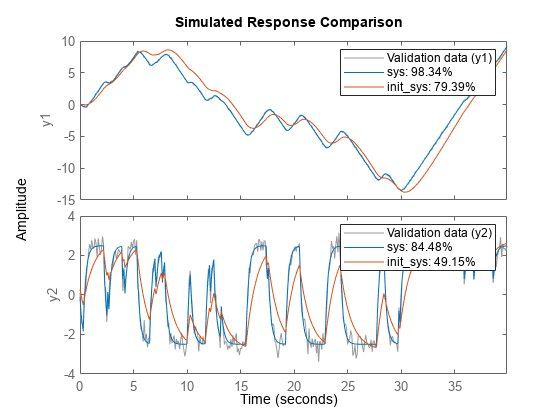
SYS.提供98.34%适合估计数据。
使用过程模型配置估计
创建流程模型结构并更新其参数值以最小化预测误差。
初始化过程模型的系数。
init_sys = iDproc('p2udz');init_sys.kp = 10;init_sys.tw = 0.4;init_sys.zeta = 0.5;init_sys.td = 0.1;init_sys.tz = 0.01;
这kp.那TW.那Zeta.那一个, 和TZ.系数init_sys.配置了他们的初始猜测。
用init_sys.使用测量数据配置预测误差最小化模型的估计。因为init_sys.是一个IDProc.模型,使用ProcestOptions.创建选项集。
加载Iddata1.Z1;opt = procestoptions('展示'那'在'那'SearchMethod'那'lm');sys = pem(z1,init_sys,opt);
过程模型识别估计数据:时域数据Z1数据具有1个输出,1个输入和300个样本。型号类型:{'P2DUZ'}算法:Levenberg-Marquardt搜索
--------------------------------------------------------------------------------------------------------
一阶改进规范(%)
迭代成本步骤最优性预期达到平衡
----------------------------------------------------------------------------------------------------- 011.2201 - 414 3.8 - - 1 19.4048 1.15 323 3.8 8.55 7 2 14.8743 2.48 814 4.41 23.3 0 3 6.84305 0.873 451 4.43 54 114 5.20354 0.977 1.49E + 03 8.75 24 7 5 1.83911 0.973 473 13 64.7 0 6 1.67582 0.225 20.3 1.98 8.88 0 7 1.67335 0.062 0.0829 0.147 0 8 1.67334 0.00494 0.055 0.000374 0.000648 0 ---- - - - 2.0.0648 0 - - - - - - - ----------------------------------------------------------------------------------------------------终止条件:近(本地)最小值,(常规(g)
检查模型适合。
sys.report.fit.fitpercent.
ans = 70.6330.
SYS.提供70.63%适合测量数据。
输入参数
输出参数
算法
PEM使用数值优化来最小化成本职能,预测误差的加权规范,定义为标量输出:
在哪里E(t)是测量的输出和模型的预测输出之间的差异。对于线性模型,错误被定义为:
在哪里E(t)是矢量和成本函数 是标量值。下标N表示成本函数是数据样本数量的函数,并且对于更大的值变得更准确N。对于多输出模型,先前的等式更复杂。有关更多信息,请参阅第7章系统识别:用户理论,第二版,由Lennart Ljung,Prentice Hall Ptr,1999年。
替代功能
您可以达到相同的结果PEM.通过使用各种型号结构的专用估计命令。例如,使用SSEST(数据,init_sys)用于估计状态空间模型。
您还可以从以下列表中选择一个网站: