预期短缺估计和回溯测试
这个例子展示了如何对预期不足模型进行估计和回溯测试。
风险价值(VaR)和预期不足(ES)必须一起估计,因为ES估计依赖于VaR估计。本例使用历史数据,在测试窗口上使用历史和参数VaR方法估计VaR和ES。参数VaR是在正态和的假设下计算的<年代P.an class="emphasis">t分布。
此示例运行支持的es返回测试金宝appesbacktest那esbacktestbysim,esbacktestbyde功能来评估测试窗口中的ES模型的性能。
这esbacktest对象不需要任何分布信息。就像varbacktest.对象,esbacktest对象仅接受测试数据作为输入。的输入esbacktest包括投资组合数据,VAR数据和相应的VAR级别,以及ES数据,因为这是返回测试的内容。喜欢varbacktest.那esbacktest运行单一投资组合的测试,但可以一次支持测试多个模型和多个VaR水平。这esbacktest对象使用预先计算的关键值表来确定模型是否应被拒绝。这些基于表的测试可以应用于任何VAR模型的近似测试。在此示例中,它们适用于后退测试历史和参数var模型。它们可用于其他VAR方法,如Monte-Carlo或极值模型。
相比之下,esbacktestbysim和esbacktestbyde对象需要分布信息,即分布名称(正常的或<年代P.an class="emphasis">t)和测试窗口中每天的分布参数。esbacktestbysim和esbacktestbyde一次只能支持测试一个模型,因为它们与特定的分布相关联,尽管你仍然可以一次支持测试多个VaR级别。这esbacktestbysim对象实现基于模拟的测试,并使用提供的分布信息运行模拟以确定临界值。这esbacktestbyde对象实现从大样本近似或模拟(有限样本)中导出临界值的测试。这Connitionalde.测试的esbacktestbyde对象测试是随时间的独立性,以评估是否存在在一系列尾部损失中自相关的证据。所有其他测试都是严重性测试,以评估尾部损耗的幅度是否与模型预测一致。这俩esbacktestbysim和esbacktestbyde对象支持正常和金宝app<年代P.an class="emphasis">t分布。这些测试可用于投资组合结果的基本分布为正态或正态的任何模型<年代P.an class="emphasis">t,例如指数加权移动平均(EWMA),Delta-Gamma或广义自回归条件异质娱乐性(GARCH)模型。
有关ES回溯测试方法的更多信息,请参见esbacktest那esbacktestbysim,esbacktestbyde,也见[1], [2], [3.]和[5.参考文献中。
评估VaR和ES
本例中使用的数据集包含标准普尔指数大约10年的历史数据,从1993年中期到2003年中期。估计窗口大小被定义为250天,因此使用全年的数据来估计历史VaR和波动率。本例中的测试窗口从1995年初运行到2002年底。
在本例中,按照交易账簿基本审查(FRTB)法规的要求,使用了97.5%的VaR置信水平;看 [4.].
负载<年代P.an style="color:#A020F0">varexampledata.mat.回报= tick2ret (sp);DateReturns =日期(2:结束);SampleSize =长度(回报);TestWindowStart =发现(1995年(DateReturns) = = 1);TestWindowEnd =发现(2002年(DateReturns) = = 1,<年代P.an style="color:#A020F0">'最后的');TestWindow = TestWindowStart: TestWindowEnd;EstimationWindowSize = 250;日期= DateReturns (TestWindow);ReturnsTest =回报(TestWindow);VaRLevel = 0.975;
历史VaR是一种非参数方法,通过一个估计窗口从历史数据估计VaR和ES。VaR是一个百分位数,基于有限样本有多种方法来估计分布的百分位数。一种常见的方法是使用刺耳函数。另一种方法是对数据进行排序,并根据样本大小和VaR置信水平确定切点。同样,也有基于有限样本估计ES的替代方法。
这hHistoricalVaRES本例底部的局部函数使用有限样本方法估计VaR和ES,采用[7.].在有限的样本中,VAR下面的观察数可能与对应于VAR水平相对应的总尾概率不匹配。例如,对于100种观察和5级为97.5%,尾部观察为2,其为样品的2%,但所需的尾部概率为2.5%。对于具有重复观察值的示例,例如,如果第二和第三排序值相同,则两者都等于VAR,那么只有比样品中最小的观察值的值比VAR相同,那么这是样品的1%,而不是所需的2.5%。实施方法hHistoricalVaRES进行校正,使尾部概率始终与变量水平一致;看 [7.详情)。
VaR_Hist = 0(长度(TestWindow), 1);ES_Hist = 0(长度(TestWindow), 1);<年代P.an style="color:#0000FF">为t = TestWindow i = t - TestWindowStart + 1;EstimationWindow = t-EstimationWindowSize: t - 1;[VaR_Hist(我),ES_Hist (i)) = hHistoricalVaRES(返回(EstimationWindow), VaRLevel);<年代P.an style="color:#0000FF">结束
下图显示了日收益,以及用历史方法估计的VaR和ES。
图;-VaR_Hist ReturnsTest情节(日期,日期,日期,-ES_Hist)传说(<年代P.an style="color:#A020F0">“返回”那<年代P.an style="color:#A020F0">“VaR”那<年代P.an style="color:#A020F0">“西文”那<年代P.an style="color:#A020F0">“位置”那<年代P.an style="color:#A020F0">“东南”)标题(<年代P.an style="color:#A020F0">“历史VaR和ES”网格)<年代P.an style="color:#A020F0">在
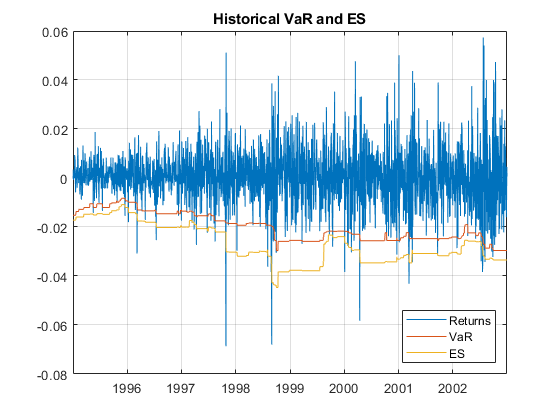
对于参数模型,必须计算返回的波动率。鉴于波动率,VAR和es可以分析计算。
本例中假设均值为零,但可以用类似的方法进行估计。
对于正态分布,直接用估计的波动率来得到VaR和ES。为<年代P.an class="emphasis">t位置-尺度分布,尺度参数由估计的波动性和自由度计算得到。
这hNormalVaRES和hTVaRES局部函数将分布参数(可以作为数组传递)作为输入,并返回VaR和ES。这些局部函数使用VaR和ES的解析表达式<年代P.an class="emphasis">t分别location-scale分布;看 [6.详情)。
在测试窗口上估计波动性波动率= 0(长度(TestWindow), 1);<年代P.an style="color:#0000FF">为t = TestWindow i = t - TestWindowStart + 1;EstimationWindow = t-EstimationWindowSize: t - 1;波动(i) =性病(返回(EstimationWindow));<年代P.an style="color:#0000FF">结束在这个例子中% Mu=0μ= 0;<年代P.an style="color:#228B22">正态分布的标准差参数=波动性SigmaNormal =波动;<年代P.an style="color:#228B22">对于T分配的%Sigma(比例参数)=波动率* SQRT((DOF-2)/ DOF)SigmaT10 =波动*√(10)/ 10);SigmaT5 =波动*√(5 - 2)/ 5);<年代P.an style="color:#228B22">%估计VaR和ES,正常[var_normal,es_normal] = hnormalvares(mu,sigmanormal,varlevel);<年代P.an style="color:#228B22">%估计var和es,t,t 10和5度自由度[VaR_T10, ES_T10] = hTVaRES(10μSigmaT10 VaRLevel);[VaR_T5, ES_T5] = hTVaRES(5μSigmaT5 VaRLevel);
下图显示了日收益,以及用正常方法估计的VaR和ES。
图;-VaR_Normal ReturnsTest情节(日期,日期,日期,-ES_Normal)传说(<年代P.an style="color:#A020F0">“返回”那<年代P.an style="color:#A020F0">“VaR”那<年代P.an style="color:#A020F0">“西文”那<年代P.an style="color:#A020F0">“位置”那<年代P.an style="color:#A020F0">“东南”)标题(<年代P.an style="color:#A020F0">'正常var和es'网格)<年代P.an style="color:#A020F0">在

对于参数化方法,同样的步骤可以用于估计备选方法的VaR和ES,如EWMA、delta-gamma近似和GARCH模型。在所有这些参数化方法中,波动性每天都被估计,要么来自EWMA的更新,要么来自delta-gamma近似,或者作为GARCH模型的条件波动性。波动性可以像上面一样得到VaR和ES估计值<年代P.an class="emphasis">tlocation-scale分布。
没有分布信息的ES反向测试
这esbacktestObject为ES模型提供了两个后备测试。这两个测试都使用Acerbi提出的无条件测试统计和Szecely在[1[给出
在哪里
是测试窗口中的时间段。
是投资组合的结果,也就是投资组合的收益还是投资组合的盈亏<年代P.an class="emphasis">T。
为定义为1-VaR水平的VaR失败概率。
估计的预期短缺期间吗<年代P.an class="emphasis">T。
VaR失效指示器是否有周期<年代P.an class="emphasis">t值为1 if<年代P.an class="inlineequation"> 和0否则。
该检验统计量的期望值为0,当存在风险低估的证据时,它为负。为了确定拒绝模型的负面程度,需要临界值,为了确定临界值,需要对组合结果进行分布假设<年代P.an class="inlineequation"> .
无条件检验统计量在一系列的分布假设中是稳定的<年代P.an class="inlineequation"> ,从瘦尾分布,如正态分布,到重尾分布,如<年代P.an class="emphasis">t自由度低(高个位数)。只有最严重的<年代P.an class="emphasis">t分布(低单位数字)导致临界值的更明显的差异。看 [1详情)。
这esbacktest对象利用无条件测试统计量的临界值的稳定性,并使用预先计算的临界值表来运行ES回测。esbacktest有两组临界值表。第一组关键值假设投资组合的结果<年代P.an class="inlineequation">
符合标准正态分布;这是unconditionalNormal测试。第二组临界值使用最重的尾部,它假设投资组合结果<年代P.an class="inlineequation">
跟随A.<年代P.an class="emphasis">t3自由度分布;这是unconditionalT测试。
无条件测试统计量对相对于ES估计的VaR失败的严重程度和VaR失败的数量(违反VaR的次数)都是敏感的。因此,相对于ES的单个但非常大的VaR失效(或只有很少的大损失)可能会导致在特定时间窗内的模型被拒绝。当ES估计也很大时,较大损失对测试结果的影响可能不像ES较小时的较大损失那么大。在许多VaR失败的时期,模型也可以被拒绝,即使所有的VaR违规相对较小,仅略高于VaR。这两种情况都在本例中说明了。
这esbacktest对象接受测试数据作为输入,但不向其提供分布信息esbacktest.您还可以为投资组合指定ID,并为每一个被回溯测试的VaR和ES模型指定ID。尽管本例中的模型ID有分布引用(例如,“正常”或“t 10”),这些只是用于报告目的的标签。测试不使用第一个模型是历史var方法的事实,或者其他模型是替代的参数var模型。用于估计上一节中的VAR和es的分布参数未通过esbacktest,并不在本节中以任何方式使用。然而,必须为支持的仿真测试提供这些参数金宝appesbacktestbysim讨论的对象基于仿真的测试节中支持的测试金宝appesbacktestbyde讨论的对象大样本和模拟测试部分。
ebt = esbacktest(ReturnsTest,[VaR_Hist VaR_Normal VaR_T10 VaR_T5],<年代P.an style="color:#0000FF">...[ES_Hist ES_Normal ES_T10 ES_T5],<年代P.an style="color:#A020F0">“PortfolioID”那<年代P.an style="color:#A020F0">“标准普尔,1995 - 2002”那<年代P.an style="color:#0000FF">...“VaRID”,[<年代P.an style="color:#A020F0">“历史”“普通的”那<年代P.an style="color:#A020F0">“T 10”那<年代P.an style="color:#A020F0">“T 5”],<年代P.an style="color:#A020F0">“VaRLevel”, VaRLevel);DISP(EBT)
esbacktest with properties: [2087x1 double] VaRData: [2087x4 double] ESData: [2087x4 double] portfolio: "S&P, 1995-2002" VaRID: ["Historical" "Normal" "T 10" "T 5"] VaRLevel: [0.9750 0.9750 0.9750 0.9750 0.9750]
通过运行来开始分析总结函数。
s =总结(光大通信);DISP(s)
PortfolioID VaRID VaRLevel ObservedLevel ExpectedSeverity ObservedSeverity观察故障预计比失踪 ________________ ____________ ________ _____________ ________________ ________________ ____________ ________ ________ ______ _______ " 标准普尔,1995 - 2002”“历史”0.975 - 0.96694 1.3711 - 1.4039 52.175 - 1.3225 2087 69 0”标普、标普,1995-2002" "T 5" 0.975 0.97173 1.37 1.4075 2087 59 52.175 1.1308 0
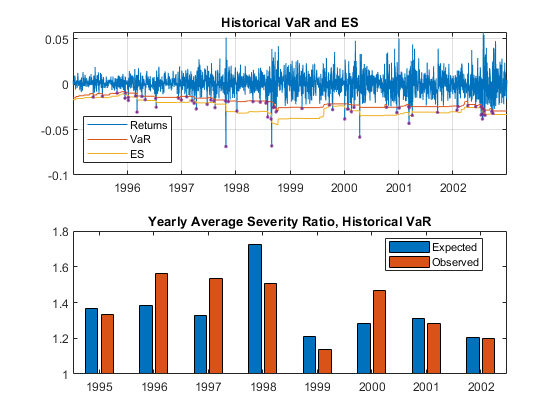
这ObservedSeverity列显示在违反VaR期间损失与VaR的平均比率。这ExpectedSeverity列使用VaR违规期间的ES与VaR的平均比率。为“历史”和“T 5”模型,观察和预期的剧烈是可比性的。但是,对于“历史”方法,则观察到的故障数(失败列)远高于预期的故障数(预期列),大约高出32%(见比柱子)。这俩“普通的”和“T 10”模型观察到的严重程度远远高于预期的严重程度。
图;子图(2,1,1)栏(分类(S.Varid),[S.ExpedSeyferity,S.ObservedSeverity])Ylim([1 1.5])传奇(<年代P.an style="color:#A020F0">“预期”那<年代P.an style="color:#A020F0">“观察”那<年代P.an style="color:#A020F0">“位置”那<年代P.an style="color:#A020F0">“东南”)标题(<年代P.an style="color:#A020F0">的平均程度比) subplot(2,1,2) bar(categorical(s.VaRID),[s.Expected,s.Failures]) ylim([40 70]) legend(<年代P.an style="color:#A020F0">“预期”那<年代P.an style="color:#A020F0">“观察”那<年代P.an style="color:#A020F0">“位置”那<年代P.an style="color:#A020F0">“东南”)标题(<年代P.an style="color:#A020F0">“VaR失败次数”的)

这runtests函数运行所有测试并仅报告接受或拒绝结果。无条件正常测试更严格。对于8年的测试窗口,两个模型都没有通过测试(“历史”和“普通的”),其中一个模型没有通过无条件正态检验,但通过无条件t检验(“T 10”),其中一个模型通过了这两个测试(“T 5”).
t = runtests(光大通信);disp (t)
portfolioid varid varlevel无条件无条件无条件___________________________________________________________________________________________________________________________________________________&p,1995-2002“S&P,1995-2002”“正常”0.975拒绝拒绝“T 10”0.975拒绝接受“标准普,1995-2002”“T 5”0.975接受接受
有关测试的其他详细信息可以通过调用各个测试函数来获得。以下是细节unconditionalNormal测试。
t = unconditionalNormal(光大通信);disp (t)
TestLevel PortfolioID VaRID VaRLevel UnconditionalNormal PValue TestStatistic CriticalValue观察 ________________ ____________ ________ ___________________ _________ _____________ _____________ ____________ _________ " 标准普尔,1995 - 2002”“历史”拒绝2087 0.0047612 -0.37917 -0.23338 0.975 0.95”标普、标准普尔,1995-2002" "T 10" 0.975不合格0.037528 -0.2569 -0.23338 2087 0.95 "标准普尔,1995-2002" "T 5" 0.975接受0.13069 -0.16179 -0.23338 2087 0.95
以下是细节unconditionalT测试。
t = unconditionalT(光大通信);disp (t)
TestLevel PortfolioID VaRID VaRLevel UnconditionalT PValue TestStatistic CriticalValue观察 ________________ ____________ ________ ______________ ________ _____________ _____________ ____________ _________ " 标准普尔,1995 - 2002”“历史”拒绝2087 0.017032 -0.37917 -0.27415 0.975 0.95”标普、标准普尔,1995-2002" "T 10" 0.975接受0.062835 -0.2569 -0.27415 2087 0.95 "标准普尔,1995-2002" "T 5" 0.975接受0.16414 -0.16179 -0.27415 2087 0.95
使用测试进行更高级的分析
本节介绍如何使用esbacktest对象,以运行用户定义的红绿灯测试,以及如何在滚动的测试窗口上运行测试。
定义交通灯测试的一种方法是将来自无条件正常和无条件的结果组合<年代P.an class="emphasis">t测试。因为无条件标准更严格,我们可以用以下水平来定义红绿灯测试:
绿色:模型通过无条件正常和无条件<年代P.an class="emphasis">t测试。
黄色:模型没有通过无条件正常测试,但通过了无条件正常测试<年代P.an class="emphasis">t测试。
Red:模型被无条件的normal和无条件的拒绝<年代P.an class="emphasis">t测试。
t = runtests(光大通信);TLValue = (t.UnconditionalNormal = =<年代P.an style="color:#A020F0">'拒绝') + (t。UnconditionalT = =<年代P.an style="color:#A020F0">'拒绝');t.TrafficLight =分类(TLValue 0:2, {<年代P.an style="color:#A020F0">“绿色”那<年代P.an style="color:#A020F0">“黄色”那<年代P.an style="color:#A020F0">'红色的'},<年代P.an style="color:#A020F0">“顺序”,真正的);disp (t)
PortfolioID VaRID VaRLevel UnconditionalNormal UnconditionalT TrafficLight ________________ ____________ ________ ___________________ ______________ ____________ " 标准普尔,1995 - 2002”“历史”0.975拒绝拒绝红”标准普尔,1995 - 2002”“正常“0.975拒绝拒绝红”标准普尔,1995 - 2002”“T 10“0.975拒绝接受黄色”标普,1995-2002" "T 5" 0.975接受接受绿色
另一种用户定义的红绿灯测试可以使用单个测试,但在不同的测试置信水平:
格林:结果是
“接受的测试水平为95%。黄色:结果是
'拒绝'在95%的测试水平,但是“接受“在99%。瑞德:结果是
'拒绝'99%的测试水平。
在[1,检测水平为99.99%。
t95 = runtests(光大通信);<年代P.an style="color:#228B22">%95%是默认的测试级别值T99 = runtests(EBT,<年代P.an style="color:#A020F0">'testlevel', 0.99);TLValue = (t95。UnconditionalNormal = =<年代P.an style="color:#A020F0">'拒绝') + (t99。UnconditionalNormal = =<年代P.an style="color:#A020F0">'拒绝');恶意破坏= t95 (:, 1:3);恶意破坏。UnconditionalNormal95 = t95.UnconditionalNormal;恶意破坏。UnconditionalNormal99 = t99.UnconditionalNormal;恶意破坏。TrafficLight =分类(TLValue 0:2, {<年代P.an style="color:#A020F0">“绿色”那<年代P.an style="color:#A020F0">“黄色”那<年代P.an style="color:#A020F0">'红色的'},<年代P.an style="color:#A020F0">“顺序”,真正的);disp(旋转)
PortfolioID VARID VaRLevel UnconditionalNormal95 UnconditionalNormal99交通灯________________ ____________ ________ _____________________ _____________________ ____________ “S&P,1995-2002”, “历史” 0.975拒绝拒绝红色 “S&P,1995-2002”, “正常” 0.975拒绝拒绝红色 “S&P,1995-2002”“T 10“0.975拒绝接受黄色”标准普尔,1995-2002“”T 5“0.975接受接受绿色
在不同的测试窗口中,测试结果可能不同。在这里,一年滚动窗口用于在原始测试窗口所覆盖的8年内运行ES回退测试。将上述第一个用户定义的红绿灯添加到测试结果表中。这总结函数也会在每一年调用,以查看风险价值失效的严重程度和数量的历史。
srolling =表;Trolling =表;<年代P.an style="color:#0000FF">为年= 1995:2002 Ind =年(Datestest)==年;portid = [<年代P.an style="color:#A020F0">“标普”,num2str(年)];PortfolioData = ReturnsTest(印第安纳州);VaRData = [VaR_Hist(Ind) VaR_Normal(Ind) VaR_T10(Ind) VaR_T5(Ind)];ESData = [ES_Hist(Ind) ES_Normal(Ind) ES_T10(Ind) ES_T5(Ind)];光大通信= esbacktest (PortfolioData VaRData ESData,<年代P.an style="color:#0000FF">...“PortfolioID”,portid,<年代P.an style="color:#A020F0">“VaRID”,[<年代P.an style="color:#A020F0">“历史”“普通的”“T 10”“T 5”],<年代P.an style="color:#0000FF">...“VaRLevel”, VaRLevel);<年代P.an style="color:#0000FF">如果年== 1995 Srolling =摘要(EBT);拖钓= runtests(EBT);<年代P.an style="color:#0000FF">其他的srolling = [srolling;摘要(EBT)];<年代P.an style="color:#228B22">% #好< AGROW >恶意破坏=[恶意破坏;runtests(光大通信)];<年代P.an style="color:#228B22">% #好< AGROW >结束结束%可选:添加上面描述的第一个用户定义的流量灯测试TLValue =(恶意破坏。UnconditionalNormal = =<年代P.an style="color:#A020F0">'拒绝') +(恶意破坏。UnconditionalT = =<年代P.an style="color:#A020F0">'拒绝');恶意破坏。TrafficLight =分类(TLValue 0:2, {<年代P.an style="color:#A020F0">“绿色”那<年代P.an style="color:#A020F0">“黄色”那<年代P.an style="color:#A020F0">'红色的'},<年代P.an style="color:#A020F0">“顺序”,真正的);
一次显示一个模型的结果。这“T 5”模型在这些测试中表现最好(两次)“黄色”),“普通的”模型最糟糕(三个“红“和一个“黄").
disp(恶意破坏(恶意破坏。VaRID = =<年代P.an style="color:#A020F0">“历史”:))
PortfolioID VARID VaRLevel UnconditionalNormal UnconditionalT交通灯___________ ____________ ________ ___________________ ______________ ____________ “S&P,1995年”, “历史” 0.975接受接受绿色 “S&P,1996年”, “历史” 0.975拒绝接受黄色的 “S&P,1997年”, “历史” 0.975拒绝拒绝红色的“S&P,1998,1998“历史”0.975接受绿色“标准普尔,1999”“历史”0.975接受绿色“标准普尔,2000”“历史”0.975接受接受绿色“标准普,2001”“历史”0.975“”历史“0.975接受绿色”标准普尔“,2002“”历史“0.975拒绝拒绝红色
disp(恶意破坏(恶意破坏。VaRID = =<年代P.an style="color:#A020F0">“普通的”:))
PortfolioID VARID VaRLevel UnconditionalNormal UnconditionalT交通灯________ ________ ________ ___________________ ______________ ____________ “S&P,1995年”, “正常” 0.975接受接受绿色 “S&P,1996年”, “正常” 0.975拒绝拒绝红色的 “S&P,1997年”, “正常” 0.975拒绝拒绝红色的“S&P,1998" 年, “正常” 0.975拒绝接受黄色的 “S&P,1999年”, “正常” 0.975接受接受绿色 “S&P,2000”, “正常” 0.975接受接受绿色 “S&P,2001年”, “正常” 0.975接受接受绿色“S&P,2002年“”正常“0.975拒绝拒绝红色
disp(恶意破坏(恶意破坏。VaRID = =<年代P.an style="color:#A020F0">“T 10”:))
PortfolioID VaRID VaRLevel UnconditionalNormal UnconditionalT TrafficLight ___________ ______ ________ ___________________ ______________ ____________ " 标普1995”“T 10“0.975接受接受绿色”标准普尔,1996”“T 10“0.975拒绝拒绝红”标准普尔,1997”“T 10“0.975拒绝接受黄色”标准普尔,1998“T 10“0.975接受接受绿色”标普、1999" "T 10" 0.975 accept accept green "标准普尔,2000" "T 10" 0.975 accept accept green "标准普尔,2001" "T 10" 0.975 accept accept green "标准普尔,2002" "T 10" 0.975 reject reject red
disp(恶意破坏(恶意破坏。VaRID = =<年代P.an style="color:#A020F0">“T 5”:))
PortfolioID VaRID VaRLevel UnconditionalNormal UnconditionalT TrafficLight ___________ _____ ________ ___________________ ______________ ____________ " 标普1995 T”“5”0.975接受接受绿色”标准普尔,1996“T”5“0.975拒绝接受黄”标准普尔,1997“T”5“0.975接受接受绿色”标准普尔,1998“T”5“0.975接受接受绿色”标普、1999" "T 5" 0.975 accept accept green "标普,2000" "T 5" 0.975 accept accept green "标普,2001" "T 5" 0.975 accept accept green "标普,2002" "T 5" 0.975 reject accept yellow
2002年是一年的一个例子,剧烈较小,但许多var失败。所有型号在2002年表现不佳,即使观察到的严重程度低。但是,某些型号的VAR故障数量超过预期的VAR故障的两倍。
disp(总结(光大通信))
PortfolioID VARID VaRLevel ObservedLevel ExpectedSeverity ObservedSeverity观察故障预期比率缺少___________ ____________ ________ _____________ ________________ ________________ ____________ ________ ________ ______ ______ “S&P,2002年的” “史记” 0.975 0.94636 1.2022 1.2 261 14 6.525 2.1456 0 “S&P,2002年的” “正常” 0.975 0.94636 1.19281.2111 261 14 6.525 2.1456 0“标准普尔,2002”“T 10”0.975 0.95019 1.2652 1.2066 261 13 6.525 1.9923 0“S&P,2002”“T 5”0.975 0.95019 1.37 1.2077 26113 6.525 1.2077 261 13 6.525 1.9923 0
下图显示了整个8年窗口期的数据,以及每年(预期和观测)的严重程度比率“历史”模型。损失的绝对规模没有ES(或等价地,与VaR)相比的相对规模那么重要。1997年和1998年的损失都相当大。然而,1998年预期的严重程度要高得多(更大的ES估计)。总的来说,“历史”方法似乎在严重性比率方面做得很好。
sH = sRolling (sRolling。VaRID = =<年代P.an style="color:#A020F0">“历史”:);图;subplot(2,1,1) FailureInd = ReturnsTest<-VaR_Hist;-VaR_Hist ReturnsTest情节(日期,日期,日期,-ES_Hist)<年代P.an style="color:#A020F0">在绘图(Datestest(destest(dessiond),returnstest(dirlision),<年代P.an style="color:#A020F0">'。')举行<年代P.an style="color:#A020F0">从传奇(<年代P.an style="color:#A020F0">“返回”那<年代P.an style="color:#A020F0">“VaR”那<年代P.an style="color:#A020F0">“西文”那<年代P.an style="color:#A020F0">“位置”那<年代P.an style="color:#A020F0">“最佳”)标题(<年代P.an style="color:#A020F0">“历史VaR和ES”网格)<年代P.an style="color:#A020F0">在子图(2,1,2)栏(1995:2002,[sh.expedseyverity,sh.observedseyferity])ylim([1 1.8])传奇(<年代P.an style="color:#A020F0">“预期”那<年代P.an style="color:#A020F0">“观察”那<年代P.an style="color:#A020F0">“位置”那<年代P.an style="color:#A020F0">“最佳”)标题(<年代P.an style="color:#A020F0">“年平均严重程度比率,历史VaR”的)
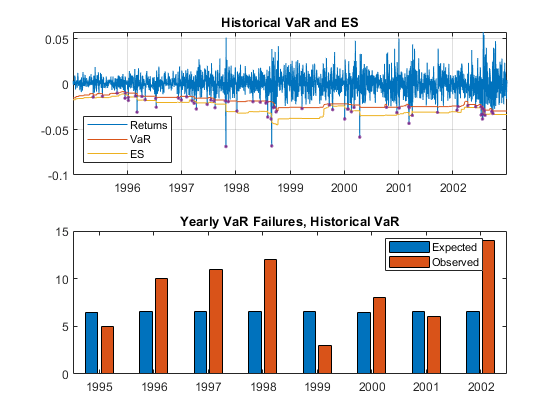
然而,一个类似的可视化的预期与观察到的VaR失败的数量显示“历史”方法往往被违反的次数比预期的多。例如,尽管在2002年预期的平均严重性比率与观察到的比率非常接近,但VaR失败的数量是预期数字的两倍多。这将导致无条件正常和无条件的测试失败<年代P.an class="emphasis">t测试。
图;子图(2,1,1)绘图(Datestest,returnstest,datestest,-var_hist,datestest,-es_hist)hold<年代P.an style="color:#A020F0">在绘图(Datestest(destest(dessiond),returnstest(dirlision),<年代P.an style="color:#A020F0">'。')举行<年代P.an style="color:#A020F0">从传奇(<年代P.an style="color:#A020F0">“返回”那<年代P.an style="color:#A020F0">“VaR”那<年代P.an style="color:#A020F0">“西文”那<年代P.an style="color:#A020F0">“位置”那<年代P.an style="color:#A020F0">“最佳”)标题(<年代P.an style="color:#A020F0">“历史VaR和ES”网格)<年代P.an style="color:#A020F0">在子图(2,1,2)栏(1995:2002,[SH.Expected,SH.Failures])传奇(<年代P.an style="color:#A020F0">“预期”那<年代P.an style="color:#A020F0">“观察”那<年代P.an style="color:#A020F0">“位置”那<年代P.an style="color:#A020F0">“最佳”)标题(<年代P.an style="color:#A020F0">“年度VaR失败,历史VaR”的)
基于仿真的测试<年代P.an id="mw_rtc_ExpectedShortfallBacktestingExample_H_5D7F0B9F" class="anchor_target">
这esbacktestbysim对象支持五个基金宝app于仿真的ES背面测试。esbacktestbysim需要投资组合结果的分布信息,即分布名称(“正常”或“t”)和测试窗口中每天的分布参数。esbacktestbysim使用提供的分布信息运行模拟以确定临界值。中支持的测试金宝appesbacktestbysim是有条件的那无条件的那斯蒂利韦那minBiasAbsolute,minBiasRelative.这些是Acerbi和Szekely在[1), (2], [3.2017年和2019年。
这esbacktestbysim对象支持普通和金宝app<年代P.an class="emphasis">t分布。这些测试可用于投资组合结果的基本分布为正态或正态的任何模型<年代P.an class="emphasis">t,例如指数加权移动平均(EWMA),Delta-Gamma或广义自回归条件异质娱乐性(GARCH)模型。
ES反馈必须近似,因为它们对预测变量中的错误敏感。然而,微小的偏见测试仅对var误差具有很小的敏感性,并且灵敏度是谨慎的,因为var误差导致更刺激的ES测试。查看acerbi-szekely([2], [3.2017年和2019年)。当分布信息可用时,建议采用最小偏差检验(见minBiasAbsolute那minBiasRelative).
这“普通的”那“T 10”,“T 5”中的基于仿真的测试可以对模型进行回溯测试esbacktestbysim.仅供说明之用“T 5”是,val。分布名称(“t”)和参数(自由度、位置和比例)时提供esbacktestbysim创建对象。
rng (<年代P.an style="color:#A020F0">“默认”);<年代P.an style="color:#228B22">%的再现性;esbacktestbysim构造函数运行一个模拟本系统= esbacktestbysim (ReturnsTest VaR_T5 ES_T5,<年代P.an style="color:#A020F0">“t”那<年代P.an style="color:#A020F0">'自由程度'5,<年代P.an style="color:#0000FF">...“位置”亩,<年代P.an style="color:#A020F0">“规模”SigmaT5,<年代P.an style="color:#0000FF">...“PortfolioID”那<年代P.an style="color:#A020F0">“标准普”那<年代P.an style="color:#A020F0">“VaRID”那<年代P.an style="color:#A020F0">“T 5”那<年代P.an style="color:#A020F0">“VaRLevel”, VaRLevel);
推荐的工作流程相同:首先,运行总结函数,然后运行runtests函数,然后运行各个测试函数。
这总结函数提供完全相同的信息总结功能从esbacktest.
s =摘要(ebts);DISP(s)
PortfolioID VaRID VaRLevel ObservedLevel ExpectedSeverity ObservedSeverity观察故障预计比失踪 ___________ _____ ________ _____________ ________________ ________________ ____________ ________ ________ ______ _______ " 标普”“T 2087 59 52.175 - 1.1308 0.975 0.97173 1.37 1.4075 0
这runtests函数显示最终的接受或拒绝结果。
t = runtests(ebts);disp (t)
无条件PortfolioID VaRID VaRLevel条件分位数MinBiasAbsolute MinBiasRelative ___________ _____ ________ ___________ _____________ ________ _______________ _______________ " 标普”“接受接受接受接受接受0.975 T 5”
关于测试结果的附加细节可以通过调用单个测试函数获得。例如,调用minBiasAbsolute测试。第一个输出,t,包含测试结果和其他细节,如p值、测试统计信息等。第二个输出,年代,包含假设分布假设正确的模拟检验统计量。例如,esbacktestbysim在这种情况下生成了1000个投资组合结果场景,其中每个场景是一系列的2087个观察模拟<年代P.an class="emphasis">t随机变量,具有5度自由和给定位置和比例参数。模拟值返回在可选中年代如果分布假设是正确的,输出显示检验统计量的典型值。这些是用来确定试验的显著性的模拟统计数据,即报告的临界值和<年代P.an class="emphasis">P.- 值。
(t, s) = minBiasAbsolute(于);disp (t)
PortfolioID VaRID VaRLevel MinBiasAbsolute PValue TestStatistic CriticalValue TestLevel观察场景 ___________ _____ ________ _______________ ______ _____________ _____________ ____________ _________ _________ " 标准普尔5 T”接受0.299 -0.00080059 -0.0030373 0.975 0.95 2087 1000
谁是<年代P.an style="color:#A020F0">年代
Name Size Bytes Class Attributes s 1x1000 8000 double
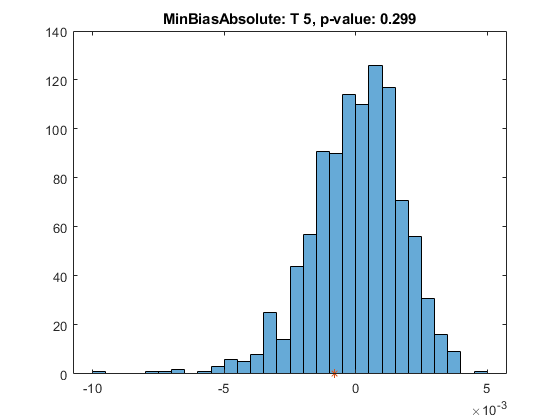
选择测试以显示测试结果并可视化测试的重要性。柱状图表示模拟检验统计量的分布,星号表示实际投资组合收益检验统计量的值。
ESTestChoice =<年代P.an class="live_control_container">“MinBiasAbsolute”;<年代P.an style="color:#0000FF">开关ESTestChoice<年代P.an style="color:#0000FF">情况下“MinBiasAbsolute”(t, s) = minBiasAbsolute(于);<年代P.an style="color:#0000FF">情况下“MinBiasRelative”[t,s] = minbiasrelative(ebts);<年代P.an style="color:#0000FF">情况下'条件'(t, s) =条件(于);<年代P.an style="color:#0000FF">情况下'无条件'[t,s] =无条件(ebts);<年代P.an style="color:#0000FF">情况下'standile'(t, s) =分位数(于);<年代P.an style="color:#0000FF">结束disp (t)

PortfolioID VaRID VaRLevel MinBiasAbsolute PValue TestStatistic CriticalValue TestLevel观察场景 ___________ _____ ________ _______________ ______ _____________ _____________ ____________ _________ _________ " 标准普尔5 T”接受0.299 -0.00080059 -0.0030373 0.975 0.95 2087 1000
图;直方图;抓住<年代P.an style="color:#A020F0">在;情节(t。TestStatistic 0<年代P.an style="color:#A020F0">‘*’);抓住<年代P.an style="color:#A020F0">从;标题= sprintf(<年代P.an style="color:#A020F0">'%s: %s, p-value: %4.3f', t.VaRID ESTestChoice t.PValue);标题(标题)
报告的无条件检验统计量esbacktestbysim与报告的无条件测试统计数据完全相同esbacktest.然而,报告的临界值esbacktestbysim是基于一个模拟使用<年代P.an class="emphasis">t5自由度分布,给定位置和尺度参数。这esbacktest对象给出了近似的测试结果“T 5”模型,而这里的结果是特定于所提供的分布信息的。同时,为有条件的测试,这是独立条件测试(ConditionalOnly结果如上表)。最终的条件测试结果(有条件的列)也依赖于初步的VaR回溯测试(VaRTestResult柱子)。
这“T 5”模型通过五个测试。
这esbacktestbysim对象提供了一个模拟函数来运行一个新的模拟。例如,如果有一个边界测试结果,其中测试统计量接近临界值,则可以使用模拟函数模拟新的场景。在需要更高精度的情况下,可以运行更大的模拟。
这esbacktestbysim按照上述相同的方法,可以在滚动窗口上运行测试esbacktest.也可以定义用户定义的流量光测试,例如,使用两种不同的测试置信符合水平,类似于上面所做的esbacktest.
大样本和模拟测试<年代P.an id="mw_rtc_ExpectedShortfallBacktestingExample_H_C18C9020" class="anchor_target">
这esbacktestbyde对象支持用大样金宝app本近似或模拟(有限样本)确定临界值的两个ES回测。esbacktestbyde需要投资组合结果的分布信息,即分布名称(“正常”或“t”)和测试窗口中每天的分布参数。它不需要ES数据的VaR。esbacktestbyde使用提供的分布信息将组合结果映射到“等级”中,也就是说,应用累积分布函数将返回映射到单位区间的值中,其中定义了测试统计数据。esbacktestbyde可以使用大样本近似或有限样本模拟来确定临界值。
中支持的测试金宝appesbacktestbyde是Connitionalde.和unconditionalDE.这些是Du和Escanciano在[3.].这unconditionalDE测试和本示例中先前讨论的所有测试都是严重测试,用于评估尾部损失的大小是否与模型预测一致。这Connitionalde.然而,测试是一种随时间推移的独立性测试,评估是否有证据表明在一系列尾部损失中存在自相关。
这esbacktestbyde对象支持普通和金宝app<年代P.an class="emphasis">t分布。这些测试可用于投资组合结果的基本分布为正态或正态的任何模型<年代P.an class="emphasis">t,例如指数加权移动平均(EWMA),Delta-Gamma或广义自回归条件异质娱乐性(GARCH)模型。
这“普通的”那“T 10”,“T 5”模型可以用中的测试进行回溯测试esbacktestbyde.仅供说明之用“T 5”是,val。分布名称(“t”)及参数(DegreesOfFreedom那位置,规模)时提供esbacktestbyde创建对象。
rng (<年代P.an style="color:#A020F0">“默认”);<年代P.an style="color:#228B22">%的再现性;esbacktestbyde构造函数运行一个模拟ebtde = esbacktestbyde (ReturnsTest,<年代P.an style="color:#A020F0">“t”那<年代P.an style="color:#A020F0">'自由程度'5,<年代P.an style="color:#0000FF">...“位置”亩,<年代P.an style="color:#A020F0">“规模”SigmaT5,<年代P.an style="color:#0000FF">...“PortfolioID”那<年代P.an style="color:#A020F0">“标准普”那<年代P.an style="color:#A020F0">“VaRID”那<年代P.an style="color:#A020F0">“T 5”那<年代P.an style="color:#A020F0">“VaRLevel”, VaRLevel);
推荐的工作流程相同:首先,运行总结函数,然后运行runtests函数,然后运行各个测试函数。这总结函数提供完全相同的信息总结功能从esbacktest.
s =总结(ebtde);DISP(s)
PortfolioID VaRID VaRLevel ObservedLevel ExpectedSeverity ObservedSeverity观察故障预计比失踪 ___________ _____ ________ _____________ ________________ ________________ ____________ ________ ________ ______ _______ " 标普”“T 2087 59 52.175 - 1.1308 0.975 0.97173 1.37 1.4075 0
这runtests函数显示最终的接受或拒绝结果。
t = runtests (ebtde);disp (t)
PortfolioID VaRID VaRLevel ConditionalDE UnconditionalDE ___________ _____ ________ _____________ _______________ " 标普”“0.975 T 5”拒绝接受
关于测试结果的附加细节可以通过调用单个测试函数获得。
t = conditionalDE (ebtde);disp (t)
PortfolioID VaRID VaRLevel ConditionalDE PValue TestStatistic CriticalValue自相关观测CriticalValueMethod TestLevel NumLags场景 ___________ _____ ________ _____________ __________ _____________ _____________ _______________ ____________ ___________________ _______ _________ _________ " 标普”“0.00034769 0.975 T 5”拒绝12.794 3.8415 0.078297 2087“大样品”1 NaN 0.95
默认情况下,临界值由大样本近似确定。用模拟方法估计的有限样本分布的临界值是可用的'qualitalvaluemethod'可选的名称-值对参数。
(t, s) = conditionalDE (ebtde,<年代P.an style="color:#A020F0">'qualitalvaluemethod'那<年代P.an style="color:#A020F0">“模拟”);disp (t)
PortfolioID VaRID VaRLevel ConditionalDE PValue TestStatistic CriticalValue自相关观测CriticalValueMethod TestLevel NumLags场景 ___________ _____ ________ _____________ ______ _____________ _____________ _______________ ____________ ___________________ _______ _________ _________ " 标普”“拒绝0.01 12.794 3.7961 0.975 T 5”0.078297 2087“模拟”1 1000 0.95
第二个输出,年代,包含模拟的测试统计值。下面的可视化对于比较模拟的有限样本分布与大样本近似的匹配程度是有用的。图中显示,对于基于模拟的(有限样本)分布,测试统计量分布的尾部略重。这意味着基于模拟的测试版本更有容忍度,在大样本近似结果被拒绝的某些情况下不会被拒绝。大样本和模拟分布的匹配程度不仅取决于测试窗口中的观测数,还取决于VaR置信水平(在有限样本分布中,更高的VaR水平导致更重的尾部)。
XLS = 0:0.05:30;pdfls = chi2pdf(xls,t.numlags);直方图(s,<年代P.an style="color:#A020F0">“归一化”那<年代P.an style="color:#A020F0">“pdf”)举行<年代P.an style="color:#A020F0">在情节(xLS, pdfLS)<年代P.an style="color:#A020F0">从ylim([0 0.1])传奇({<年代P.an style="color:#A020F0">“模拟”那<年代P.an style="color:#A020F0">“大样本”}) Title = sprintf(<年代P.an style="color:#A020F0">“条件测试分布\nVaR级别:%g%%,样本大小= %d”VaRLevel * 100, t.Observations);标题(标题)
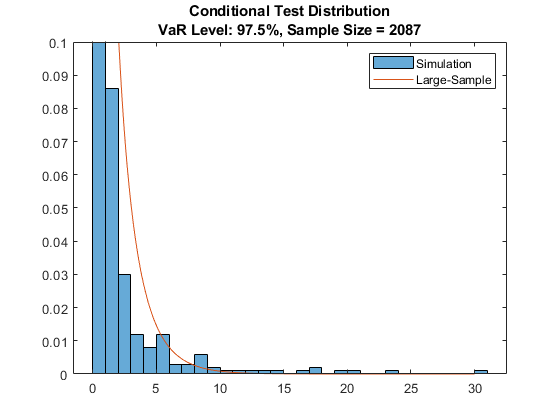
可以使用类似的步骤查看详细信息unconditionalDE测试,并比较基于大样本和仿真的结果。
这esbacktestbyde对象提供了一个模拟函数来运行一个新的模拟。例如,如果有一个边界测试结果,其中测试统计量接近临界值,则可以使用模拟函数模拟新的场景。此外,在默认情况下,模拟为条件测试存储最多5个延迟的结果,因此如果需要基于模拟的大量延迟的结果,则必须使用模拟函数。
如果大样本近似测试是您唯一需要的测试,因为它们对于特定的样本大小和VaR水平是可靠的,那么您可以在创建一个esbacktestbyde对象的“模拟”可选输入。
这esbacktestbyde按照上述相同的方法,可以在滚动窗口上运行测试esbacktest.您还可以定义流量灯测试,例如,您可以使用两个不同的测试置信符合水平,类似于上面所做的esbacktest.
结论
对比三个ES回溯测试对象:
这
esbacktest对象用于广泛的分布假设:历史VaR、参数VaR、蒙特卡罗VaR或极值模型。然而,esbacktest根据同一测试的两个变体提供近似测试结果:具有两组不同的预先计算的关键值的无条件测试统计(unconditionalNormal和unconditionalT).这
esbacktestbysim对象用于参数化方法的标准和<年代P.an class="emphasis">t分布(包括EWMA、GARCH和delta-gamma),并需要分布参数作为输入。esbacktestbysim提供五种不同的测试(有条件的那无条件的那斯蒂利韦那minBiasAbsolute,minBiasRelative这些测试的临界值是使用您提供的分布信息模拟的,因此更加准确。尽管所有的ES后测对VaR估计误差都很敏感,但最小偏差测试的敏感性很小,推荐使用(详见Acerbi-Szekely 2017和2019年[2], [3.])。这
esbacktestbyde对象也用于参数化方法与普通和<年代P.an class="emphasis">t分布(包括EWMA、GARCH和delta-gamma),并需要分布参数作为输入。esbacktestbyde包含严重程度(unconditionalDE)和时间无关(Connitionalde.)测试,它具有大型样本,快速版本的测试。这Connitionalde.测试是这三个类别中支持的所有测试中的ES模型的独立测试的唯一测试。金宝app
如本例所示,所有三个ES反向测试对象都提供了生成关于严重性、VaR失败和测试结果信息的报告的功能。这三个ES后测对象提供了在它们基础上构建的灵活性。例如,您可以创建用户定义的红绿灯测试,并在滚动窗口上运行ES回溯测试分析。
参考文献
[1] Acerbi, C.和B. Szekely。“val预期缺口。”MSCI Inc., 2014年12月。
[2] Acerbi, C.和B. Szekely。可测试统计的一般性质。<年代P.an class="emphasis">SSRN电子杂志。2017年1月。
[3] Acerbi, C.和B. Szekely。“ES的最小偏差Backtest。”<年代P.an class="emphasis">风险。2019年9月。
[4]巴塞尔银行监管委员会。《市场风险的最低资本要求》2016年1月,https://www.bis.org/bcbs/publ/d352.htm
[5] Du, Z.和J. C. Escanciano。“回溯测试预期缺口:对尾部风险的解释。”<年代P.an class="emphasis">管理科学.第63卷第4期2017年4月
McNeil, A., R. Frey和P. Embrechts。<年代P.an class="emphasis">量化风险管理:概念,技术和工具.普林斯顿大学出版社,2005。
R. T.和S. Uryasev。"一般损失分配的条件风险值"<年代P.an class="emphasis">银行和金融杂志。第26卷,2002年,1443-1471页。
本地函数
函数(VaR, ES) = hHistoricalVaRES(样本,VaRLevel)<年代P.an style="color:#228B22">%计算历史VaR和ES%技术细节见[7]折算成损失示例=样本;N =长度(样本);k =装天花板(N * VaRLevel);z =排序(样本);VaR = z (k);<年代P.an style="color:#0000FF">如果k < N ES = ((k - N * VaRLevel) * z (k) +总和(z (k + 1: N))) / (N * (1 - VaRLevel));<年代P.an style="color:#0000FF">其他的ES = z (k);<年代P.an style="color:#0000FF">结束结束函数(VaR, ES) = hNormalVaRES(μ、σVaRLevel)<年代P.an style="color:#228B22">计算VaR和ES为正态分布%技术细节见[6]VaR = 1 * (Mu-Sigma * norminv (VaRLevel));ES = 1 * (Mu-Sigma * normpdf (norminv (VaRLevel)。/ (1-VaRLevel));<年代P.an style="color:#0000FF">结束函数(VaR, ES) = hTVaRES(景深,μ、σVaRLevel)<年代P.an style="color:#228B22">计算位置尺度分布的VaR和ES%技术细节见[6]var = -1 *(mu-sigma * tinv(varlevel,dof));ES_STANDARDT =(TPDF(瓦莱佛,DOF),DOF)。*(DOF + TINV(varlevel,DOF)。^ 2)./((1-verlevel)。*(DOF-1)));ES = -1 *(MU-SIGMA * ES_STASTADDT);<年代P.an style="color:#0000FF">结束
相关例子
更多关于
选择网站
选择一个网站,在那里获得翻译的内容,并看到当地的活动和优惠。根据您的位置,我们建议您选择:<年代trong class="recommended-country">.
选择<年代P.an class="recommended-country">网站你也可以从以下列表中选择一个网站:
