提供
累积分布函数
语法
描述
y = cdf (___“上”)使用更精确地计算极端上尾概率的算法返回CDF的补充。“上”可以跟随前面语法中的任何输入参数。
例子
通过指定分布名称和参数计算正态分布cdf
通过指定分布名称来计算正态分布的cdf值“正常”以及分布参数。
定义输入向量x包含用于计算cdf的值。
x = (2, 1, 0, 1, 2);
用平均值计算正态分布的cdf值 等于1和标准偏差 等于5。
μ= 1;σ= 5;y = cdf (“正常”, x,μ、σ)
y =1×50.2743 0.3446 0.4207 0.5000 0.5793
中的每个值y对应于输入向量中的一个值x.例如,在值x等于1,对应的CDF值y等于0.5000。
使用分布对象计算正态分布cdf
创建一个正态分布对象,并使用该对象计算正态分布的cdf值。
创建一个具有平均值的正态分布对象 等于1和标准偏差 等于5。
μ= 1;σ= 5;pd = makedist (“正常”,“亩”,穆,“σ”,西格玛);
定义输入向量x包含用于计算cdf的值。
x = (2, 1, 0, 1, 2);
中值处计算正态分布的cdf值x.
y=cdf(pd,x)
y =1×50.2743 0.3446 0.4207 0.5000 0.5793
中的每个值y对应于输入向量中的一个值x.例如,在值x等于1,对应的CDF值y等于0.5000。
计算泊松分布cdf
用速率参数创建泊松分布对象, ,等于2。
λ=2;pd=makedist(“泊松”,“拉姆达”,lambda);
定义输入向量x包含用于计算cdf的值。
x=[0,1,2,3,4];
计算中值处泊松分布的cdf值x.
y=cdf(pd,x)
y =1×50.1353 0.4060 0.6767 0.8571 0.9473
中的每个值y对应于输入向量中的一个值x.例如,在值x等于3,对应的CDF值y等于0.8571。
或者,您可以计算相同的cdf值,而无需创建概率分布对象。使用提供函数,并使用相同的速率参数值指定泊松分布,
.
y2 = cdf (“泊松”, x,λ)
y2 =1×50.1353 0.4060 0.6767 0.8571 0.9473
cdf值与使用概率分布对象计算的值相同。
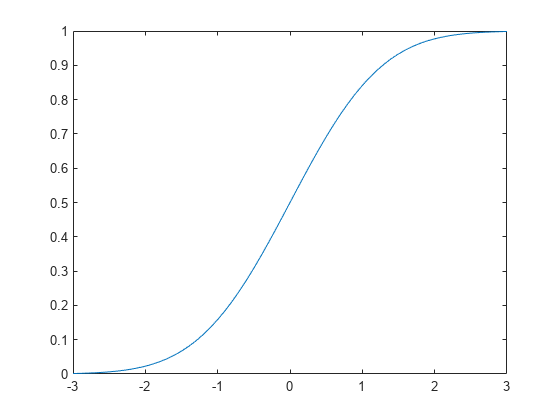
绘制标准正态分布cdf
创建标准正态分布对象。
pd = makedist (“正常”)
pd =正态分布正态分布mu = 0 sigma = 1
指定x值,并计算cdf。
x = 3: .1:3;p = cdf (pd, x);
画出标准正态分布的cdf。
情节(x, p)
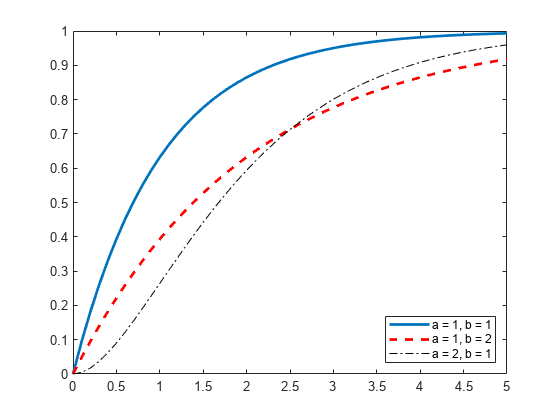
绘制伽马分布图
创建三个gamma分布对象。第一个使用默认参数值。第二个指定一个= 1和b = 2.第三个指定一个= 2和b = 1.
pd_gamma = makedist (“伽马”)
pd_gamma = Gamma distribution伽马分布a = 1 b = 1
pd_12 = makedist (“伽马”,“一个”1.“b”,2)
pd_12 = Gamma distribution伽马分布a = 1 b = 2
pd_21 = makedist (“伽马”,“一个”2.“b”,1)
pd_21 = Gamma distribution伽马分布a = 2 b = 1
指定x值并计算每个分布的CDF。
x=0.1:5;cdf_γ=cdf(pd_γ,x);cdf_12=cdf(pd_12,x);cdf_21=cdf(pd_21,x);
创建一个图形来显示当您为形状参数指定不同的值时伽马分布的cdf是如何变化的一个和b.
图;J =情节(x, cdf_gamma);持有在;K=曲线图(x,cdf_12,“r——”);L =情节(x, cdf_21“k -”。);集(J,“线宽”,2);集合(K,“线宽”,2);图例([J K L],'a = 1, b = 1','a = 1, b = 2','a = 2, b = 1',“位置”,‘东南’);持有从;
将帕累托尾拟合到t分布并计算cdf
将帕累托尾与a拟合 分布在累积概率0.1和0.9。
t = trnd (3100 1);obj = paretotails (t、0.1、0.9);(p, q) =边界(obj)
p =2×10.1000 - 0.9000
q =2×1-1.8487 - 2.0766
中值处计算cdf问.
提供(obj, q)
ans =2×10.1000 - 0.9000
输入参数
输出参数
选择功能
扩展功能
你也可以从以下列表中选择一个网站:
